Autoscaling AWS Step Functions Activities

-
Devesh Chourasiya, Jingjing Gu
- Jun 26, 2019
In an ongoing effort to break down our monolithic applications into microservices here at Yelp, we’ve migrated several business flows to modern architecture using AWS Step Functions.
Transactional ordering at Yelp covers a wide variety of verticals, including food (delivery/takeout orders), booking, home services, and many more. These orders are processed via Step Functions, where each is represented as an execution instance of the workflow, as shown below.
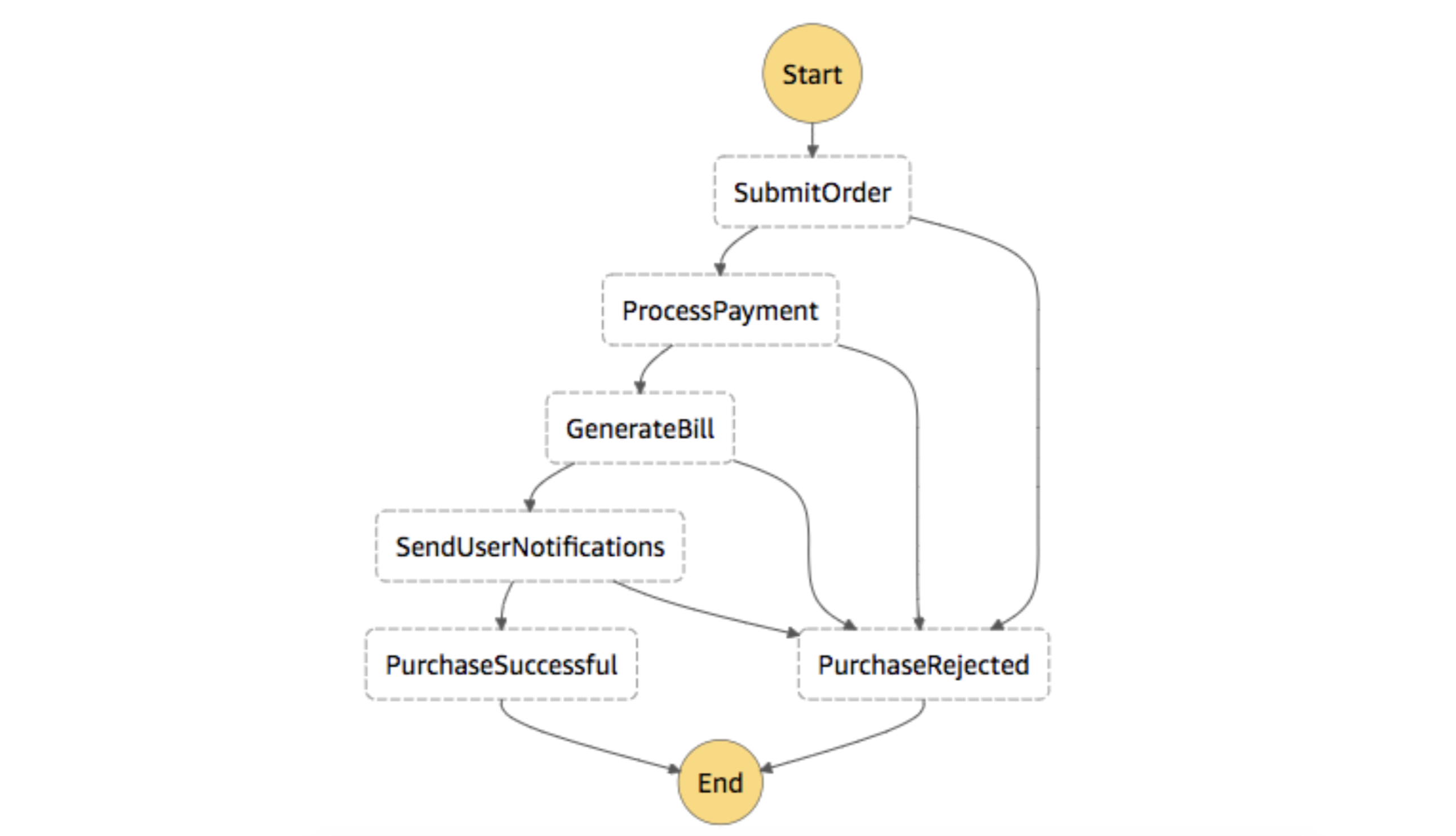
Figure 1: Illustrative Step Functions Workflow for Transactions Orders
Each step in the above workflow is an “activity,” and Yelp implements these activities as batch daemons, which interact with AWS Step Functions via an API integration that fetches tasks and submits activity execution results. We run multiple instances of these batch daemons, which we deploy via PaaSTA, an in-house deployment platform.
Each workflow execution, i.e., processing of an order, is time bound. We do this by enabling the timeout capabilities provided by Step Functions. Each activity within a workflow needs to be completed within a specified time, such that the sum of the time taken by all activities in a workflow is within the limits of the workflow timeout. We also use activity retries, which are configurable per activity, to achieve resiliency in cases of intermittent recoverable failures.
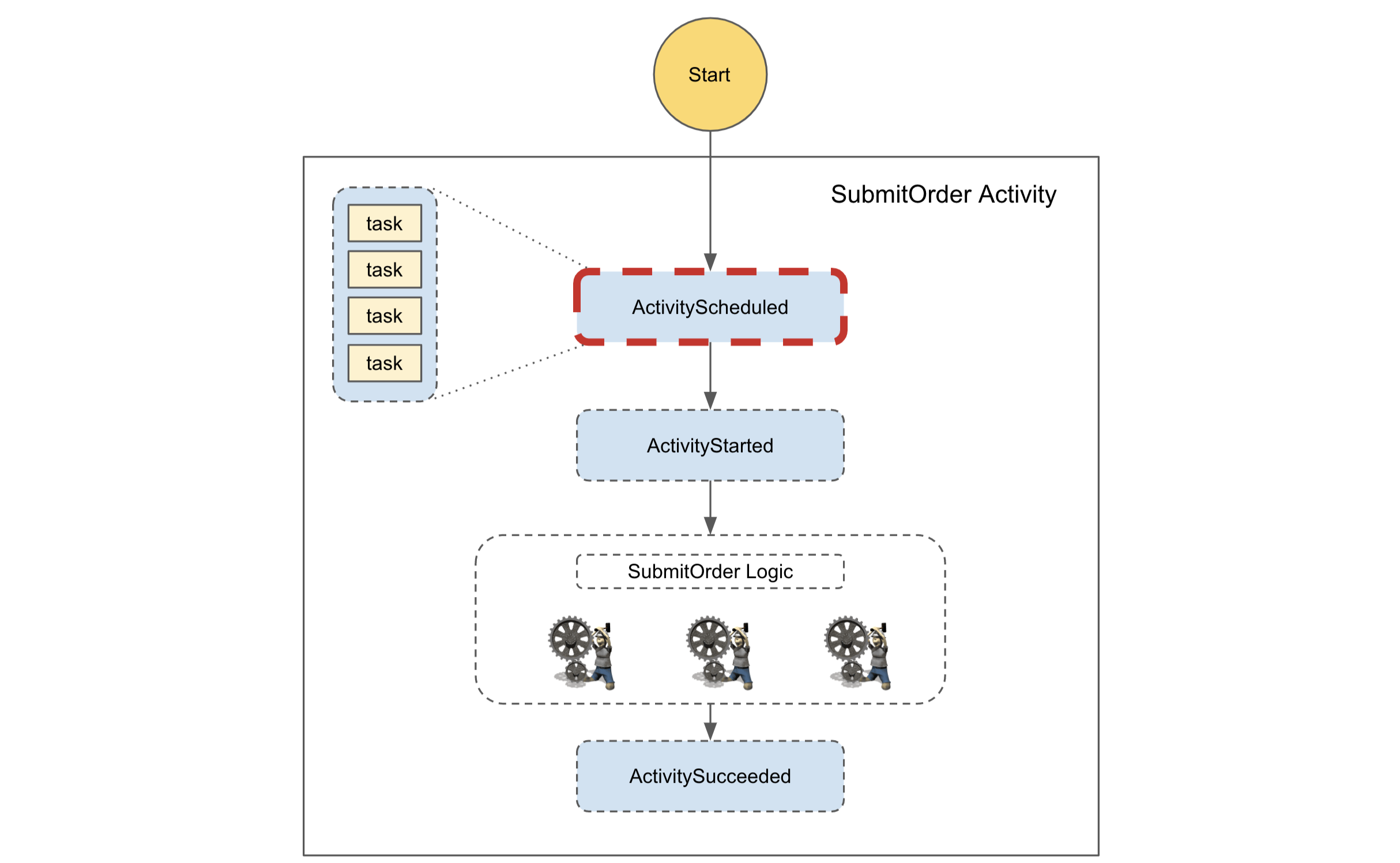
Figure 2: Zoom-in view for SubmitOrder activity execution (Step Functions' internal steps shown in blue color)
If we zoom in on a specific activity (SubmitOrder in this case) for each workflow execution, each execution will be queued in the ActivityScheduled state until it’s picked up by one of the “activity workers.” Since the total time per activity (including execution and wait time) is bound, tasks with longer wait times get less time for execution. These tasks may need retries, and cascading effects from multiple activities could hit a workflow timeout threshold. As AWS provides aggregated metrics on the wait time for these tasks (ActivityScheduleTime), in order to maintain the desired success rate and latencies for workflow processing, we need to have a healthy count of activity workers.
Why Activity Instances Need Auto-Scaling
Transactional flows at Yelp experience repetitive traffic patterns over the course of the day and week. Before the new autoscaling system, we used Step Functions cloudwatch metrics to tune the activity instances count to meet service-level objectives. In these cases, we provisioned a static count of activity workers to handle peak traffic, which led to a lot of unused compute capacity during non-peak hours, making transactional flow an ideal use case for auto-scaling.
Auto-scaling from PaaSTA is based on pyramid uwsgi metrics and CPU usage, whereas Step Functions(SFN) workflows rely on a timely execution (ActivityScheduleTime metric) of the activities. The Step Functions Autoscaler bridges the gap between these two systems to manage and control activity instances.
Autoscaler Architecture
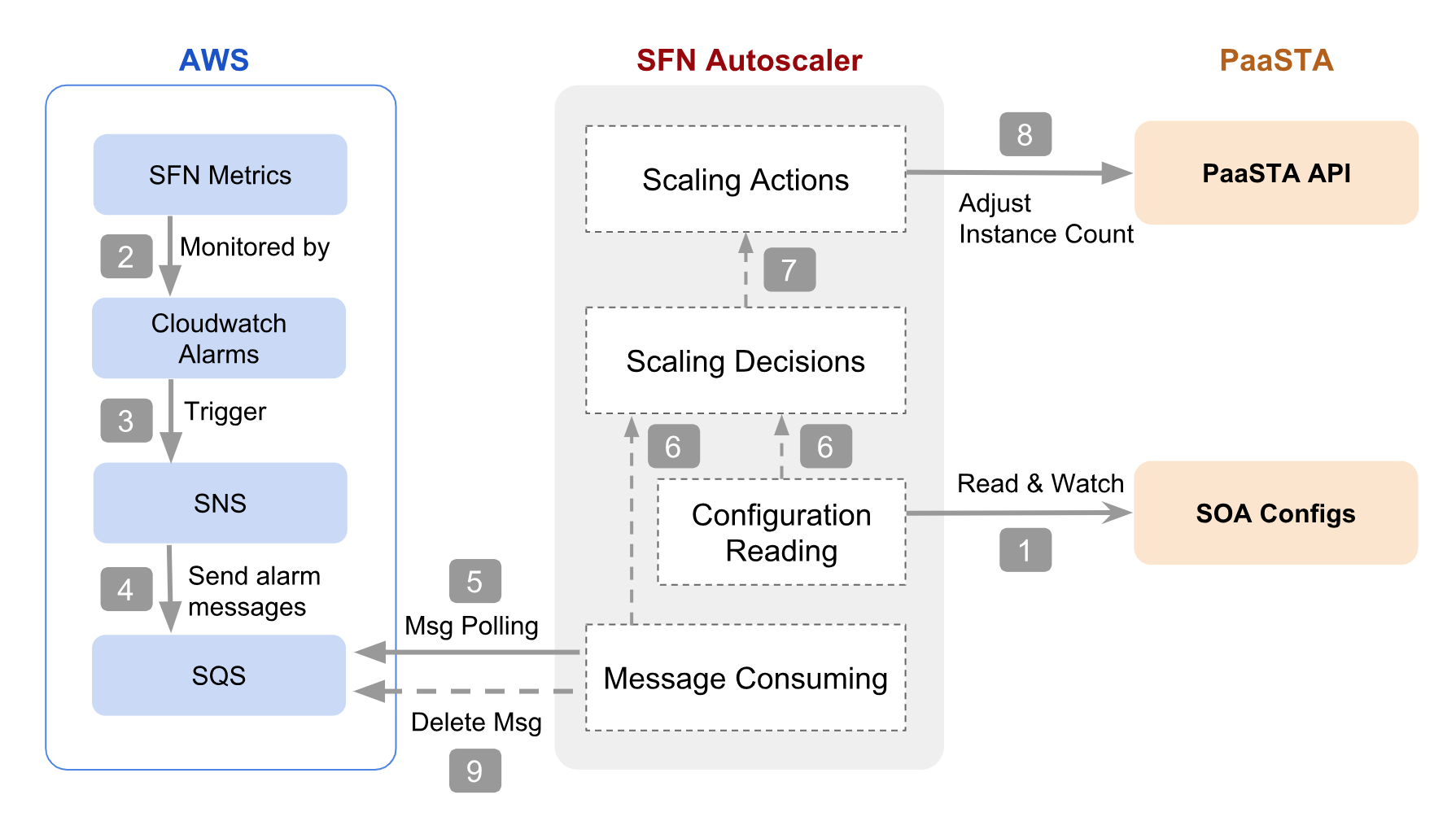
Figure 3: Different components of the Autoscaler and it's interactions with AWS services and PaaSTA
The Autoscaler system consists of three components: AWS Services, the Autoscaler service, and the PaaSTA system. At a high level, the Autoscaler first fetches the scaling configuration, then gathers scaling demands from the AWS side, computes the scaling decision, and, lastly, invokes the PaaSTA api to adjust the instance count.
AWS Components
We utilize Step Functions Metrics (ActivityScheduleTime metric) and Cloudwatch Alarms to detect any scaling-worthy events, and SNS and SQS services for relaying scaling messages.
More specifically, there are two cloudwatch alarms for each activity: scale up and scale down. When an alarm detects a breaching condition, it sends out “ALARM” notifications to be polled by the Autoscaler. It will then send an “OK” notification when the ActivityScheduleTime metric is back to normal.
Scaling Brain
Upon receiving scaling messages, the Autoscaler will validate the message, parse, and comprehend the request, and then compute a concrete scaling decision for a specific activity. It considers two major factors for scaling decisions: scaling configurations (e.g., min/max count and scaling gradient) and scaling record (e.g., the last alarming time and the last scaling time).
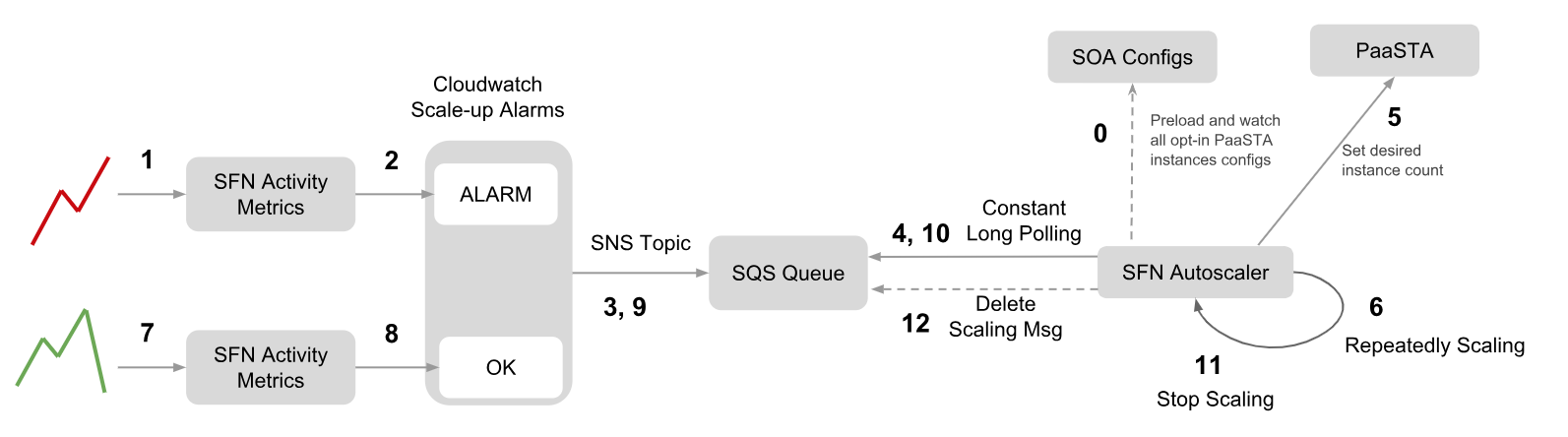
Figure 4: Steps involved in the scale-up process, highlighting repeated scaling.
Design Considerations
Repeatedly Scaling
When traffic ramps up, the scale-up alarm fires off an “ALARM” notification and the Autoscaler repeatedly scales up the activity workers until the ActivityScheduleTime metric is back to the normal threshold. When traffic settles down, the cloudwatch alarm sends out an “OK” notification. With the “OK” message, the autoscaler will begin to clean up the previous “ALARM” notification and wrap up the cycle of scaling for that activity.
Avoid Scale Flapping
Flapping (continuous churn of scale-up and -down events) is a typical challenge for any auto-scaling system. Here are a few highlights from our design made to handle this challenge:
- We support a scale-down cool-off time to prevent two consecutive scale-down actions within a certain amount of time. This value is configurable by service owners.
- We validate incoming scaling signals to guard against any malicious, delayed, or duplicated scaling notifications. This is achieved through qualifying the alarm name, maintaining the last alarm time, and examining the scaling configuration before every scaling action.
- Conservative scaling down is based on historical statistics for scale-down alarms so that they’re less susceptible to triggers and never occur during peak hours.
Rollout Story
We’ve rolled out the Step Functions Autoscaler in production for 85% of our transaction ordering and have already seen positive results in the first few months.
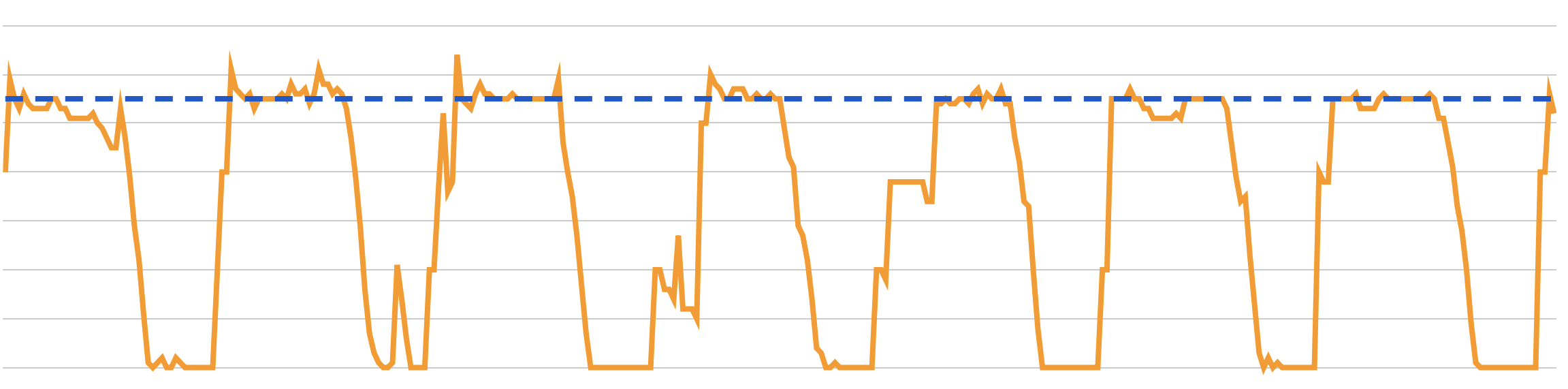
Figure 5: Graph showing number of activity workers for a given activity in last 7 days. Blue line represent the static count of workers before Autoscaler integration.
The above graph shows the instances of number changes for a production activity in a one-week range. The blue line is the instance number we would have without the Autoscaler and the orange line is with autoscaling. You can clearly see that there are periods where an activity could use fewer instances, and we’ve seen a ~34% savings in compute cost per activity per week, even with a very conservative scaling down.
We’ve enabled autoscaling for ~11 Step Functions activities which processed ~2 million tasks within one week. The entire rollout took about 2 weeks, not including downtime for the activities. Below are some suggestions and lessons learned as part of this rollout.
-
Revisit historical data for setting cloudwatch alarm threshold We used historical data for the initial values of scale-up and scale-down thresholds, and adjusted them accordingly during the rollout phase. Note: there will be a non-zero activity wait time (ActivityScheduleTime metric) even during off-peak hours, so a scale-down alarm threshold should be set accordingly.
-
Gradually reach the ideal minimal instance count with large scale-up increment steps For a safe rollout, we kept the minimum and maximum instance bounds close in the beginning and gradually widened the gap throughout. High scale-up gradients can avoid degradation during burst traffic, while instance count is kept at a minimum.
-
Be aggressive on scaling up and conservative on scaling down We used cool-down times, small scale-down gradients, and larger evaluation periods for conservative scale-downs, as opposed to large scale-up gradients and smaller evaluation periods for aggressive scale-ups.
Monitoring
Among Step Functions cloudwatch metrics, close monitoring of activities and workflow metrics like ActivityScheduleTime, ActivitiesTimedOut and ExecutionsTimedOut, helped us during the rollout phase.
As for next steps, we look forward to rolling out Autoscaler for other Step Functions use cases at Yelp. We’re also exploring proactive scaling strategies based on heuristics like time of day, historical trends, ad-hoc demands, etc.
Join us to build a Commerce Platform at Yelp
We are building a comprehensive and APIs driven Commerce Platform that enables teams at Yelp to build Subscription and Transaction products. If you are curious to learn more, Apply here!
View Job