Architecting Restaurant Wait Time Predictions

-
Shweta Joshi, Machine Learning Engineer
- Dec 12, 2019
Is there a restaurant you’ve always wanted to check out, but haven’t been able to because they don’t take reservations and the lines are out the door?
Here at Yelp, we’re trying to solve problems just like these and delight consumers with streamlined dining experiences. Yelp Waitlist is part of the Yelp Restaurants product suite, and its mission is to take the mystery out of everyday dining experiences, enabling you to get in line at your favorite restaurant through just the tap of a button.
For diners, in addition to joining an online waitlist, Yelp Waitlist provides live wait times and queue updates. For restaurants, it facilitates table management and reduces stress and chaos by the door by allowing guests to sign up remotely. The flow is simple: diners see the current wait times at a Waitlist restaurant and virtually get in line right from the Yelp app.
If you want to know more about the product, check out this related post!
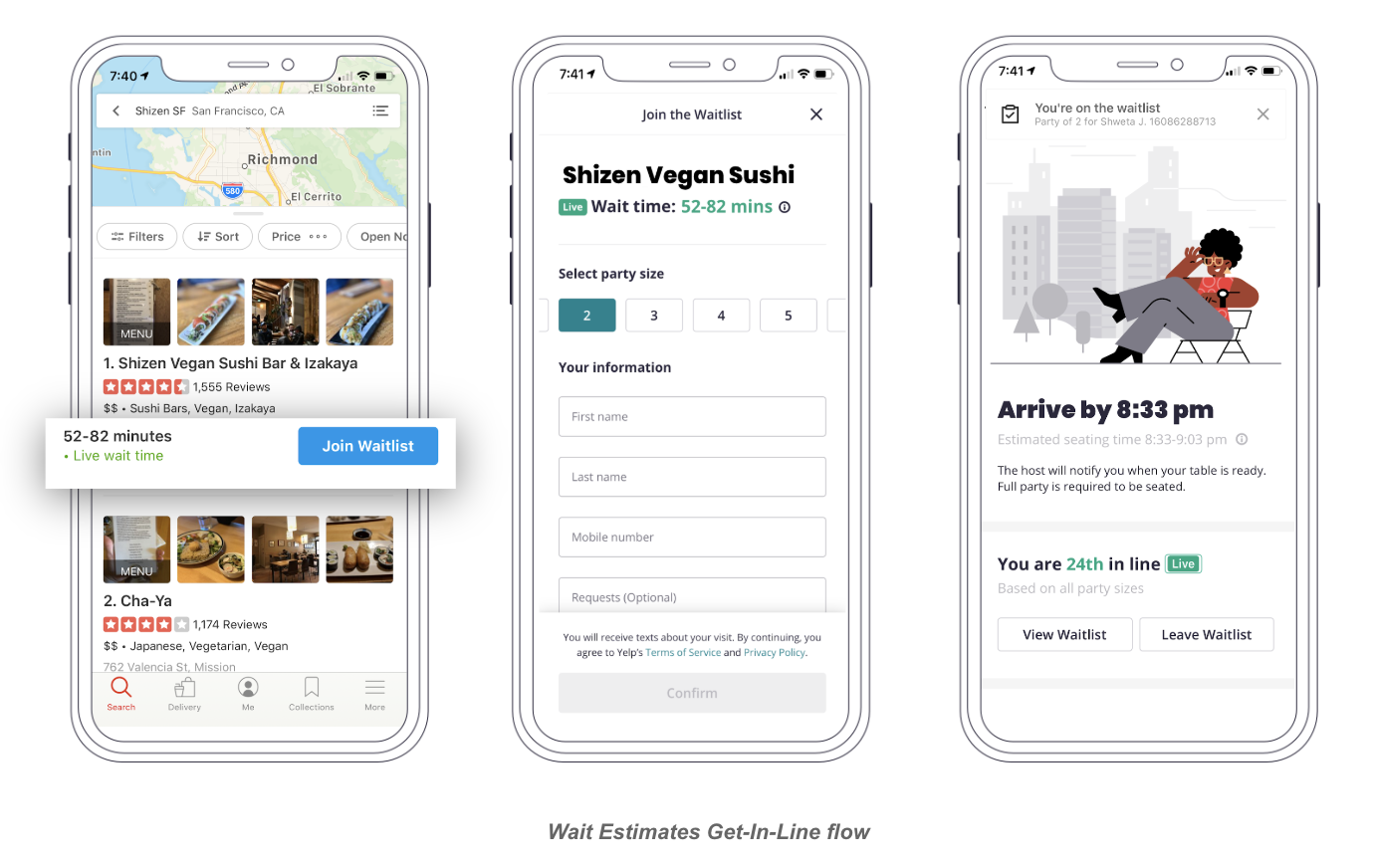
Wait estimates are modeled as a machine learning problem. When you request to be seated at a restaurant through Waitlist, a machine learning model is alerted behind the scenes to generate a prediction. The ability of this model to provide reasonable wait estimates is what makes the online waitlist possible, so you have some bit of AI to thank the next time you enter a line from the comfort of your home.
The prediction endpoint is part of a larger system that enables the generation of the estimated time. This blog post is aimed at describing the Waitlist machine learning system that bridges hungry diners to their tasty food.
The System
As you can imagine, the system needs to be as up to date as possible with the state of the restaurant (e.g., how many people are currently in line), and the many other contextual factors that determine an estimate as accurately as possible. For example, you cannot expect the wait time to extend beyond the closing time of the restaurant. Additionally, there are certain latency requirements to serve a high volume of QPS.
The system can be broken down into three components:
- The offline training pipeline where model iteration, data-wrangling, and ETLs happen.
- Online serving which tracks the current state of the restaurant and responds to requests.
- Analytics providing model performance reports and analyses.
We chose to use XGBoost as the model to generate wait estimates. Offline training happens via Spark and an optimized XGboost Java Library that helps us meet latency requirements is used online.
We faced two main challenges while architecting the machine learning system:
- The requirement of serving users live predictions from a Spark ML model with an online service in Python.
- The cold start problem when adding new businesses to the product.
Most of the system was initially designed to make the first challenge possible. We slowly added components to enable training and prediction with more features once we felt confident in the system’s ability to work seamlessly on its own. The second challenge was addressed by the use of XGboost, which can make predictions with partial feature-sets. Though these predictions may not be very accurate at first, retraining helps improve them over time.
Below is a simplified view of the system:
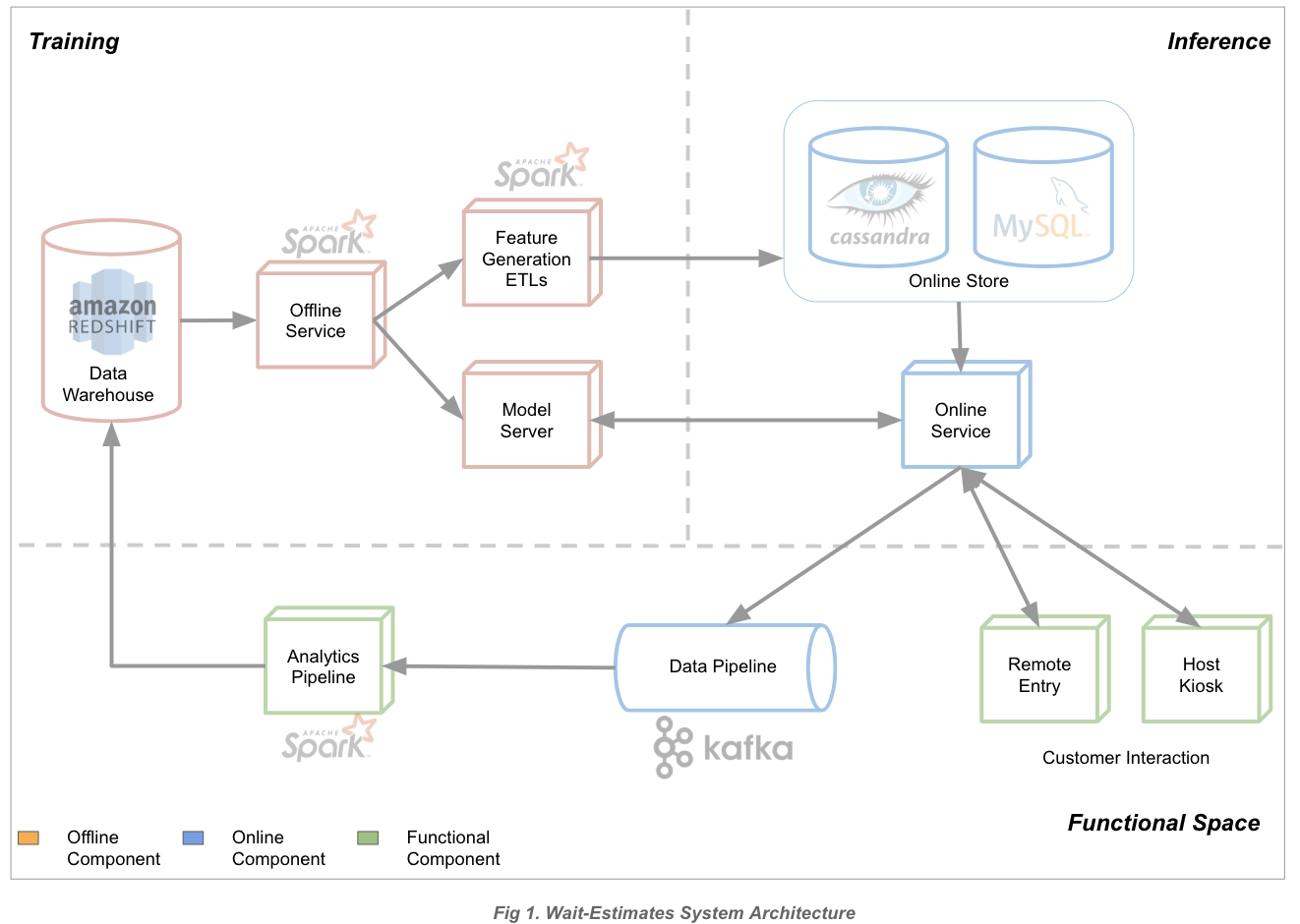
The various components in the above diagram are:
- Data Warehouse: Source of data for training, backed by Redshift.
- Offline Service: Service responsible for training the model. This is written in Python and uses Spark for model training due to the quantity of data involved (tens of millions of instances after sanitization).
- Feature ETLs: Spark-based ETLs for generating additional features. These are non-time-sensitive features which are shared both online and offline.
- Model Server: In-house Java service which stores the trained model and is optimized for high-throughput traffic.
- Online Stores: Available features generated from Spark-ETL, as well as up-to-date restaurant data. This encompasses:
- Cassandra for storing results from Spark-ETLs
- MySQL for storing the restaurant’s state
- Online Service: Service responsible for generating predictions in real time and making calls to the online stores and model server to do so. This service is written in Python.
As hinted above, we rely heavily on Spark for building models, as well as for deriving additional features. It’s important to note, however, that the online service does not make use of Spark, which can result in different data access and manipulation patterns before being fed into the model to make a prediction.
A lot of care goes into ensuring that the set of features we compute offline match those we compute online. A theoretical example of a mismatched online/offline feature would be different orderings for one-hot encoded feature columns, which, despite having identical raw data, can result in different feature vectors.
Figure 2 (below) breaks down the model development, evaluation, and launch pipelines:
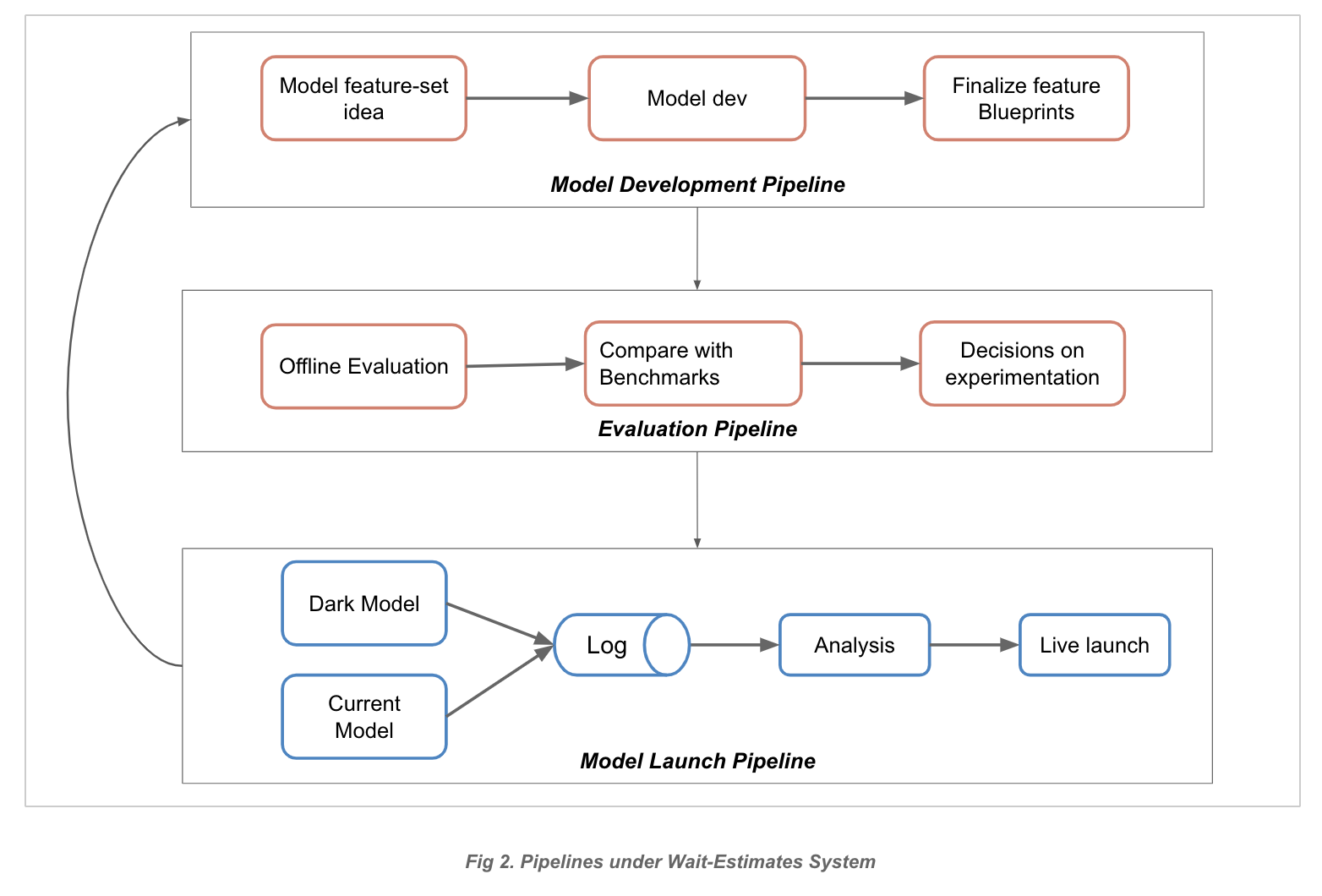
Model development pipeline:
At this stage, the model flows from human intuition/ideation to reality. This encompasses:
- Feature-extraction ETLs
- Feature-set blueprints: Feature definitions intended to enforce online/offline consistency (e.g., what subset of features this particular feature-set contains, its data types, etc.)
Evaluation pipeline:
This ensures that the newly trained model obtains an acceptable performance with regard to business metrics. This pipeline is a combination of automation and human decision making. For example, a metric could track the percentage of diners who waited more than five minutes beyond their quoted estimate.
The steps for evaluation include:
- Running an evaluation batch for the freshly trained model.
- Comparing performance against previous benchmarks.
- Evaluating if the new model is a viable candidate for experimentation/release. (Unfortunately not all candidates are viable; this can be attributed to the probabilistic nature of machine learning projects.)
- The models that pass this stage promise superior performance compared to the status quo model.
Experimentation/ Model-Launch pipeline
At this stage, we’re convinced of the model’s promise and want to experiment with it in the real world. To maintain confidence that the model will operate in production as it did in offline evaluation, we promote the model to “dark-launch” mode.
To do this, we need to be able to reproduce the feature-set in the online service. This means:
- Each incoming user request contains a partial feature-set.
- The rest of the features are pulled from online data stores.
- The feature-set is guaranteed to maintain the same format as the training data (thanks to feature-blueprints).
Once we have the ability to make predictions from the online service, we can proceed to the dark-launch phase. Here, we:
- Surface our candidate model as a ghost/dark model.
- Enable the model to see live incoming requests and produce estimates for these requests (without surfacing them to the user).
- Use the event logs generated from the experiment launch to measure the performance of all models across all samples.
We’ve seen several benefits from dark-launching our model:
- Comparing performance across different cohorts of businesses without affecting estimates.
- Weeding out any differences in online and offline model-pipelines. Since both perform their own set of computations, etc., there’s plenty of scope for mistakes and we can ensure that offline and dark-launch give identical prediction estimates for the same candidate.
- Checking the latency of the new model and ensuring we don’t violate any SLOs.
At any given time, we can have several models launched live, several dark-launched, and several under development.
We can typically verify within a few days’ time if the dark-launched model is working as expected; if not, we can begin to investigate any discrepancies. If the results are as expected, we can slowly start rolling out the new model. This slow rollout is intended to capture feedback loops that we’re not exposed to during dark-launch.
What’s a Feedback Loop?
Whenever we surface an estimate to the user, we set an expectation of the time they’ll be seated, thereby affecting when the user shows up to the restaurant. If, for instance, this causes the user to arrive at the restaurant after their table is actually available, they may have a longer overall wait time (our label) than if we’d given them a shorter estimate. These instances are tracked in our logs and we try our best to reduce such inaccuracies. The feedback loop here happens when our label data is influenced by our prediction.
Factors like this add sensitivity to our system, which underscores the importance of providing accurate wait estimations.
Measuring Success
Within this problem area are a variety of metrics we can track, and choosing the right ones is always a challenge. We need to cater to the needs of not only the users (by ensuring they wait only as long as expected), but also the restaurant and its staff (not sending enough people to occupy empty tables vs. sending too many people at the same time which puts pressure on the hosts).
We can observe a few of these metrics using data streamed into our logs. A few others can be gauged through user-feedback surveys (which in itself has the propensity to be biased), and whatever else that cannot be observed, we hypothesize. We’re constantly trying to collect as much data as possible to improve the coverage of each quantitative and qualitative metric.
Measuring success is not trivial, especially given that the set of restaurants we serve is constantly growing and providing more opportunities to observe new behavioral patterns. With each model that we build and deploy, we learn a little more about our system, helping us better measure success. So far this strategy has worked well for us.
Conclusion
Wait-time estimation is a unique problem we could only begin to address because of the state-of-the-art tooling and support from the wonderful people at Yelp! We continue to make updates to the algorithms and migrate our system to use more efficient tooling to make our estimates as accurate as possible so that you - our customer - don’t have to wait longer than you need at your favorite restaurant.
Acknowledgements
Huge thanks to my indispensable team for all their contributions: Chris Farrell, Steve Thomas, Steve Blass, Aditi Ganpule, Saeed Mahani, Kaushik Dutt, and Sanket Sharma.
Become a Software Engineer at Yelp
Passionate about solving problems with Machine Learning?
View Job