Whose Code is it Anyway?

-
Luis Pérez, Software Engineer; Mitali Parthasarathy, Engineering Manager
- Jan 13, 2021
Improving Code Ownership at Yelp
In this prior blog post, Kent talked about how the Engineering Effectiveness (EE) organization was created at Yelp to reduce communication complexity between core teams and product teams. Core teams need to communicate infrastructure changes, manage the deprecation of libraries and tools, and evangelize new tooling to other teams at a regular cadence. EE has been investing in building tools that can communicate these changes and provide insights into what might make product teams more effective in shipping code quickly and safely.
In order to measure the engineering effectiveness of Yelp, we need to measure the effectiveness of its organizations and the teams that make up those organizations. But how do we know what a team is responsible for? We needed a way to assign an owner to something (let’s call this an entity) that we want to measure. Once an entity has an owner, we can collect metrics on that entity and derive the health score (i.e., effectiveness) for that owner. These metrics can then be aggregated by team, organization, or even the entire Engineering division, so that we can identify areas that we can collectively improve. And this is how the Ownership microservice was born.
Who is an Owner?
Until now we have had different ways of defining an owner at Yelp. It could be a single engineer, engineering team, or engineering org. However, these definitions of ownership can be vulnerable to reorganizations (engineers moving teams or companies) or creative naming resulting in fictional teams owning code (the owner named “Super Friends plus Julia” was hard to track down to a real team!). Eventually, we settled on requiring that owners are canonical engineering teams (more on how we keep track of canonical teams later). When teams split, merge or get renamed, we expect the Ownership information to be updated to reflect the new teams that were formed.
Why does Yelp value Ownership?
Apart from being able to measure the effectiveness of a team, we generally think it is a good idea to know who owns certain code or infrastructure. Here are some reasons behind our thinking:
Better for Planning
Decision-making at Yelp happens in a distributed and decentralized manner. Teams are responsible for their own short and long term planning. Knowing what services a team is accountable for allows that team to better plan their roadmap for maintaining those services. They can choose which bugs to fix, what features need to be built and what services can be deprecated. Teams that are dependent on these services also get a good understanding of what they can expect and when.
Better for Triaging Issues
Alerting the right team to triage an incident as quickly as possible is critical to maintaining our uptime SLAs. Our monitoring and alerting systems can hook into the Ownership service to automatically alert the right team when an incident is reported. We also have Slack integrations for ad-hoc issue triage.
Better for Collaboration
As Yelp gets larger, it’s no longer feasible for everyone to memorize the core competencies of other teams. An engineer might need to get quickly ramped up on another team’s area of expertise to contribute a bug fix or feature that is blocking them. Having clear ownership helps to easily identify experts on teams and collaborate with them which exemplifies one of our core values of ‘playing well with others’.
Avoid Duplication of Effort
Prior to the development of the Ownership service, several teams across Yelp independently were developing their own specific ways to track ownership for org-wide migrations or infrastructure updates that they were responsible for. The Ownership service was implemented to combine all of these small independent efforts and reduce the duplication of work by individual teams.
Keep things from falling through the cracks
We have many systems running in production that don’t need constant maintenance because they run smoothly on their own, but without clear ownership, historical context and key information can get lost along the way. To avoid this, Ownership allows us to make sure that these types of systems don’t get dropped when, for example, the original developers move teams or leave the company.
What can be owned?
Pretty much anything - especially anything where knowing whom to contact is important! We currently track the ownership of a wide range of entities: from API endpoints to Debian packages to automated tests. The most common entity that can be owned is a Git repository. Code lives in repositories and we can assign the entire repository to an owner by creating a YAML file at the root of the repository named OWNERS.
Here’s an example of an OWNERS file for the Ownership service (very meta!):
teams:
- Developer Insights & Automation
Ownership can also be assigned on a directory level by creating the OWNERS file for each directory. This is useful in the case of monorepos (for example: our Android or iOS apps). We originally had more information in this file like team members, Slack channels, Jira projects, etc., but we now query our HR software for that in order to centralize where information comes from and maintain its accuracy. We also created Git pre-receive and pre-commit hooks that will check for the presence of (and validate!) an OWNERS file to ensure that we are always assigning canonical owners to repositories. This validation will also try to suggest potential canonical teams based on a team lookup of the developer pushing any invalid ownership change.
We can also assign ownership to Slack channels, Jira projects, and PagerDuty schedules and escalation policies which helps with having the right process in place to reach out to an expert or alert the right team during an incident.
Ownership Ecosystem
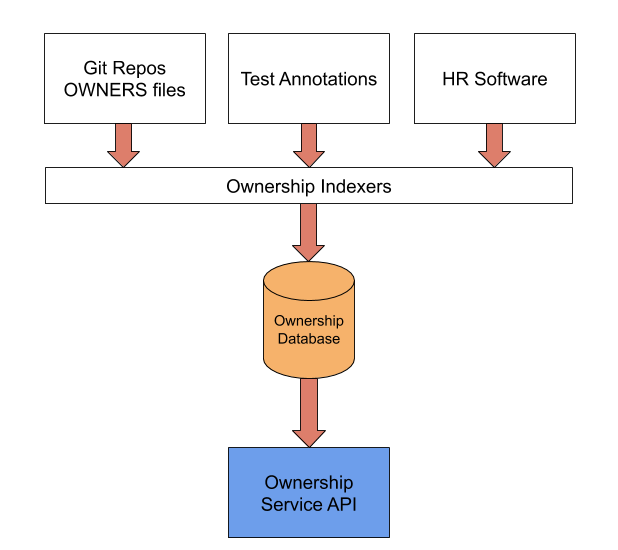
Overview of how Ownership works
The Ownership service provides APIs to create, update and delete owners and entities. Entities can also be assigned one or more owners. Indexers are batch jobs that run periodically to detect entities and update their ownership in the service. These jobs collect information from all the sources of ownership information and store them in the database. For example, we have a job that reads OWNERS files and populates the ‘Git repository’ entity along with its owner into the Ownership database. Another example is the indexer that pulls data from our HR software and stores team information in the database.
We also have a UI to view and edit general information about entities and owners, and automate the process of executing ownership changes related to team changes.
How do we use Ownership?
Now that we are able to attribute entities to a team, we can track the health of the team by auditing these entities. We use Ownership to power the EE Metrics tool that can surface a number of audits in the areas of developer velocity, reliability and code quality pertaining to each team. More about how EE Metrics works will be in a future blog post!
As more tools start adopting the Ownership service, we discover more use cases for entities that would be valuable to own. One example is tracking a team’s on-call burden by associating a PagerDuty escalation policy with an engineering team. Another use case is to track the outstanding action items after an incident in the form of JIRA tickets. The Ownership service can be easily extended to create a new indexer to ingest new entities that we want to audit.
Anyone can use our web frontend to look up ownership information:
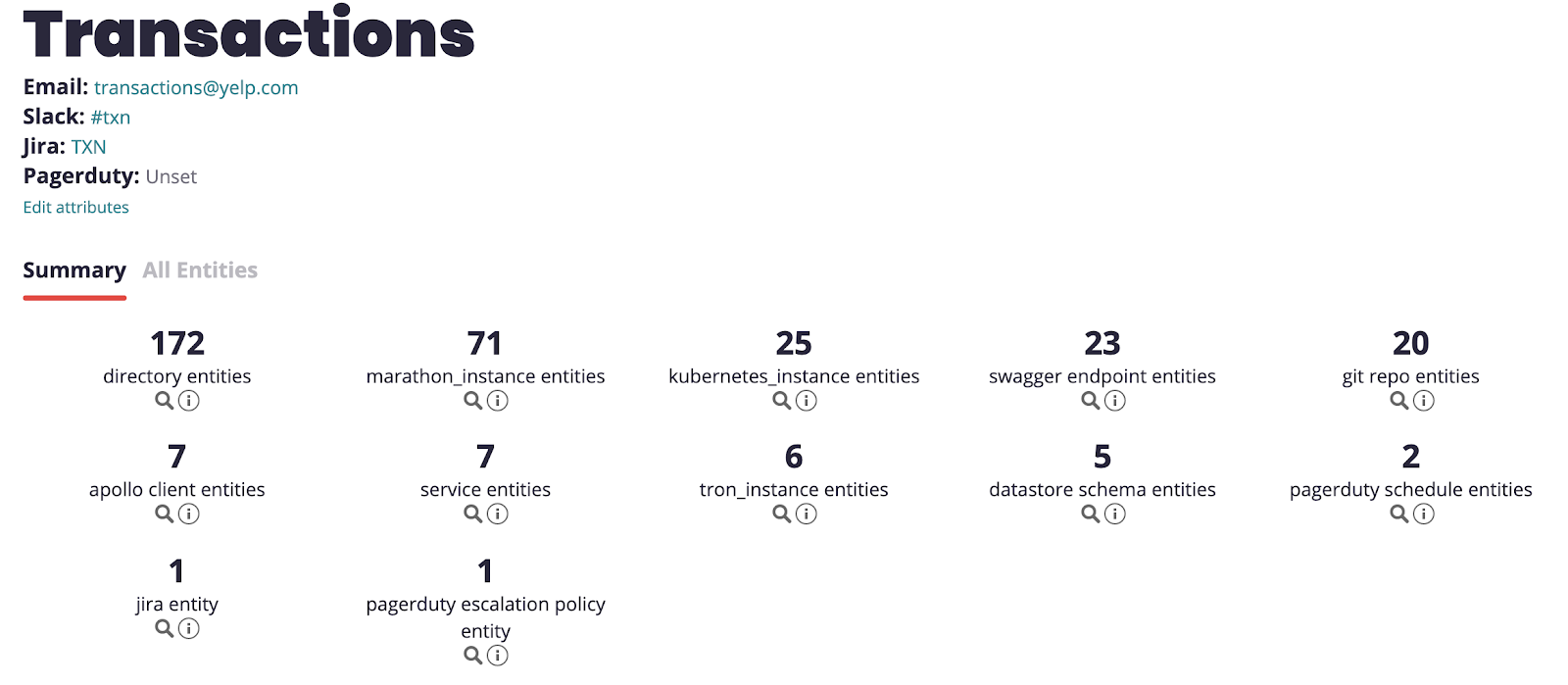
Example of an ownership information page
Alternatively, a developer can also use our API to quickly look up an owner’s information for use-cases that aren’t conducive to a web UI: e.g., automatically adding reviewers to a code review, automated Slack messaging, etc.
Keeping Ownership Updated
One of the challenges with Ownership is keeping it updated. Entity ownership is not static and there are times when the team responsible for an entity can change, for example, due to an engineering-wide reorganization or split of a single team across functional lines. This entropy has historically made it difficult to maintain an accurate source of truth for ownership.
That’s why we’ve created a web frontend to the Ownership service that allows managers and leads to not only visualize what their team currently owns, but also to easily transfer entities to other teams.
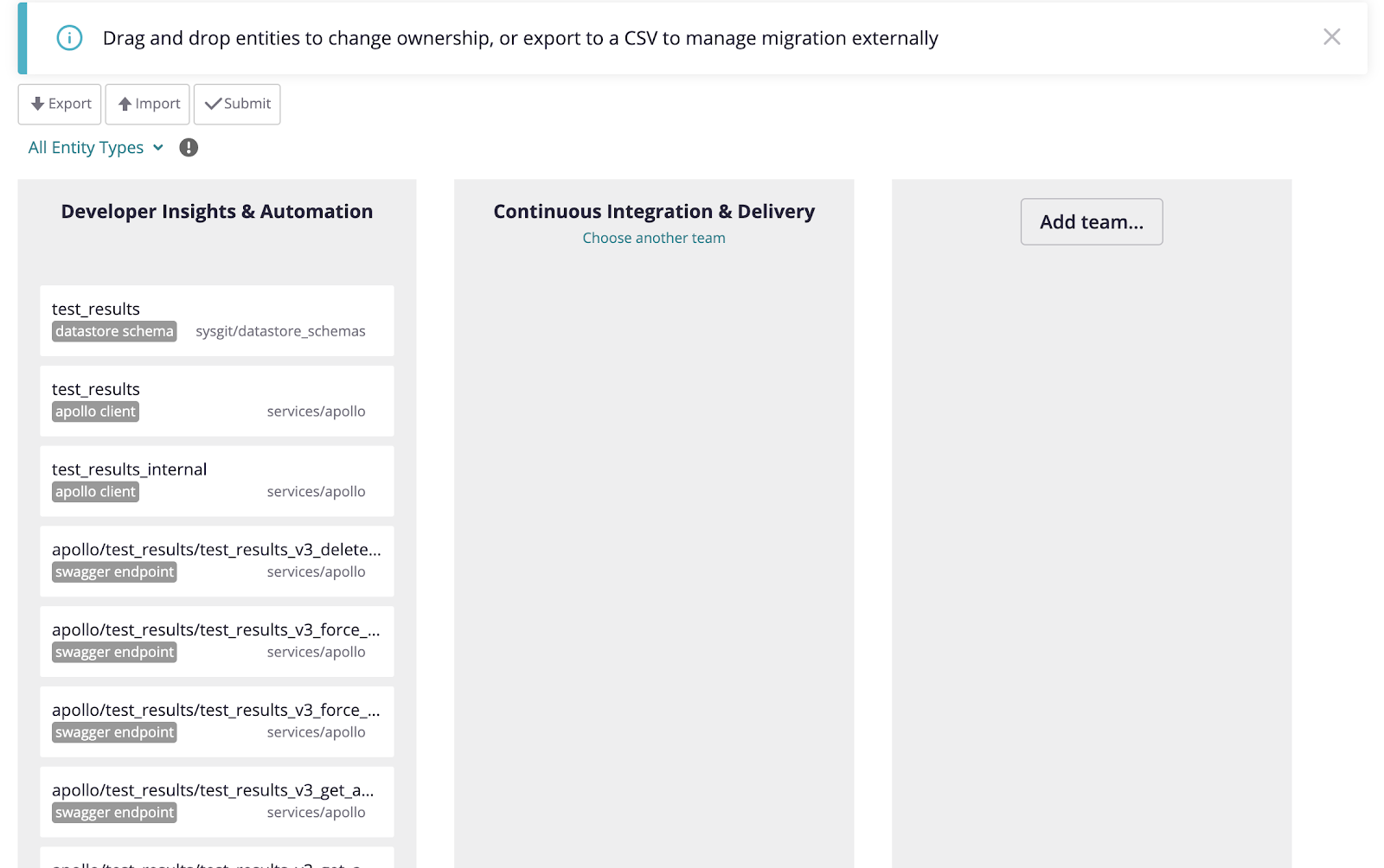
Example usage of migration UI
Additionally, we periodically validate that certain metadata about a team are still valid (e.g., Slack channels haven’t been archived, Jira projects aren’t read-only, etc.) and automatically ticket managers to resolve any issues found.
Towards the future!
We’re heartened by all the internal usages of Ownership (ranging from Slack bots that query Ownership to automated Pull Requests using Ownership to assign code reviewers) and are excited to see any and all future applications of Ownership to come. Teams are happy to have a single source of truth and the ability to easily update ownership information by themselves.
Acknowledgements
We’d also like to thank the following people for helping us make Ownership a reality:
- Anja Berens (pharaun), Software Engineer
- James Flinn, Software Engineer
- Jonathan Chu, Software Engineer
- Kyle Deal, Software Engineer
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job