One year later: building Trust Levels during COVID

-
Jeffrey Butterfield and Ivy Chen, Software Engineers
- Apr 29, 2021
From its devastating toll on local economies to its impact on the little things like handshakes and hugs, the COVID-19 pandemic seemed to leave nothing unchanged. Local businesses were especially impacted and forced to make big changes, many overhauling their operations overnight in order to adapt to the new normal.
Businesses turned to Yelp to communicate operational changes brought on by the pandemic. They kept their communities in the know by updating the COVID-19 section on their business pages, which was launched at the beginning of the pandemic. They indicated new health and safety precautions, such as wearing masks and enforcing social distancing. They updated their hours, scaled back sit-down dining, pivoted to support takeout and delivery, and even introduced virtual service offerings to remain accessible to their communities.
Given the surge in businesses updating their Yelp pages with COVID-19 related changes, we knew it would be important to measure how confident we are that a given piece of business information is still accurate. To address this, Yelp’s Semantic Business Information team built a new internal system called Trust Levels. In this blog post, we will define Trust Levels, take a look at each part of the new system, and end with an example that ties all the pieces together.
Defining Trust Levels
At Yelp, we call our business information “business properties.” Business properties include anything that we can describe about a business, such as business address, if the business is women-owned, if the business can repair appliances, etc. The numerous business properties found on each Yelp page can share special insights about businesses from retail and restaurants to home and local services.
Usually business owners can indicate the business properties on their business page. Consumers are also able to contribute information about a business, which can also be collected through our survey questions answered by people who have checked in or visited that business. Our User Operations team reviews changes to ensure quality and accuracy, and can modify the information as well. However, determining how confident we can be about any given piece of information became especially important as businesses repeatedly had to update how they operate due to changing local government policies.
In order to define our confidence levels, we first created a unified vocabulary that could be used across engineering and Product teams, to avoid each team creating its own definition of trust. We created Trust Level labels from Level 1 (L1), which means we are highly confident that the data is both accurate and current, to Level 4 (L4), which means we do not have strong or recent signals to determine accuracy. These levels, which we designed to be simple and easy to refer to, can then be used by various teams without needing to do their own calculations. For example, if a front-end team wants to only display information of the highest confidence level, they can do so by fetching the information and Trust Level from the backend and only displaying it if the Trust Level is L1.

Calculation
Once we defined this shared vocabulary, we set out to calculate a Trust Level for each of the tens of millions of business property values on our platform. To start, we utilized one of our existing systems that tracks historical business data. The system logs all business changes to a dedicated Kafka stream for offline use cases. Each record contains a source type (business owner, external partner, etc.), source ID (which particular source provided the data), source flow (which feature or callsite the update came through), and timestamp. All of these fields are essential indicators when it comes to determining how confident we are that a given business property is correct.
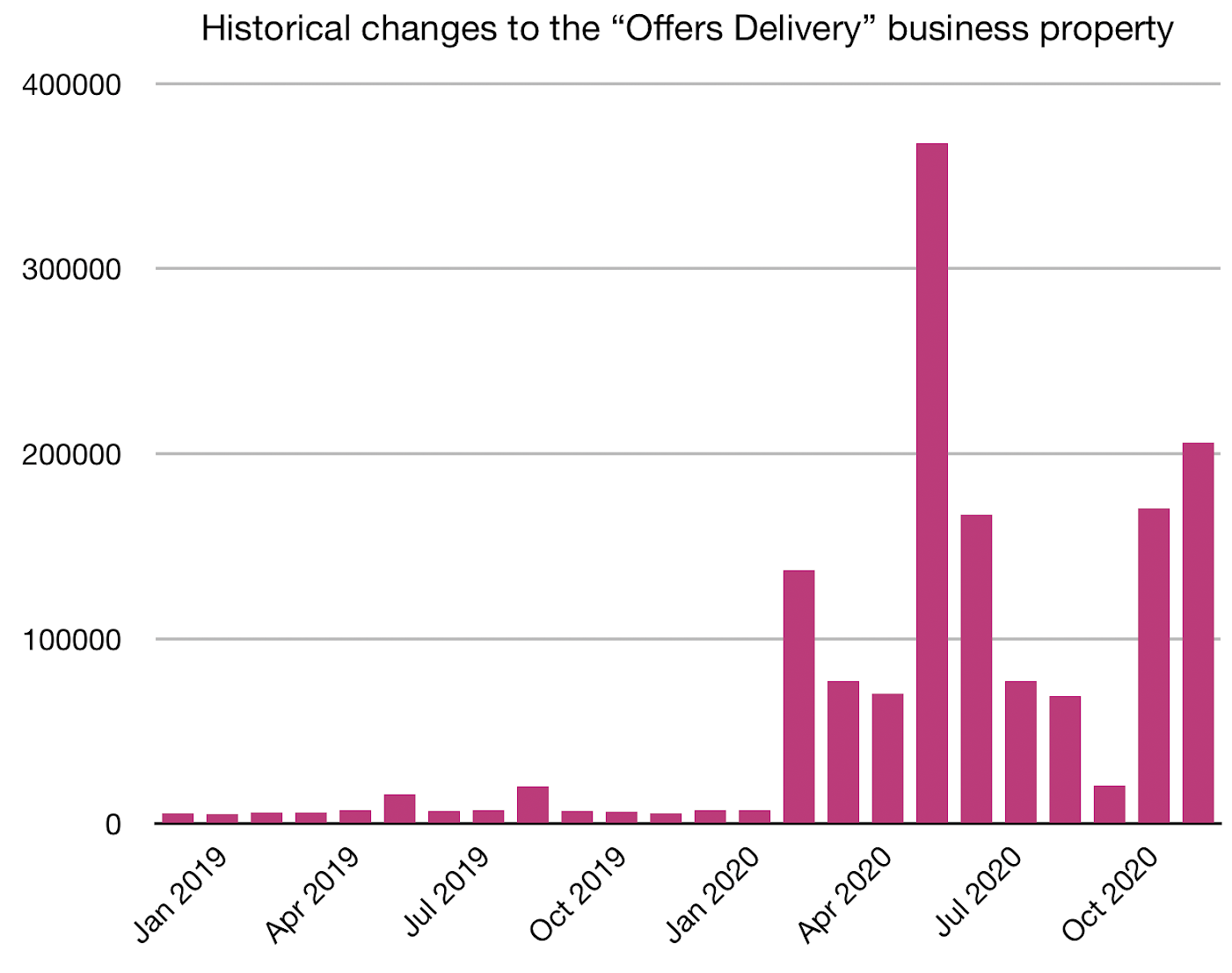
We also realized our property ingestion APIs could be improved to capture another important signal around data freshness. A lot of incoming updates we receive are “non-updating updates” — those with values that match what we already have on file. Previously, most of our ingestion flows discarded these as redundant, so we modified them to instead emit logs to a new, dedicated stream for verification events. Not all verifications are equivalent, so we made sure to include the same source-related fields described above in the Kafka stream with each event, preserving context about the verification that might be useful to us later.
Equipped with historical updates and verifications, we wrote a Spark ETL job to periodically pull these logs from S3, join them on business_id and business property, and then execute a series of rules to decide which Trust Level to assign to that pair. While we won’t detail the actual algorithm here, signals of recency and source type ended up being the biggest determiners of a given business property’s Trust Level.
Storage
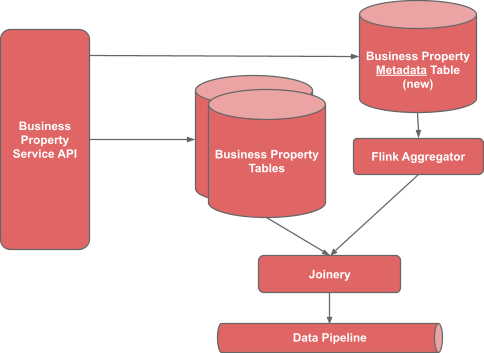
After calculating each Trust Level value, we needed a place to store them. Trust Levels are data describing properties, so it made sense to store these values alongside other business property metadata. A metadata table was considered multiple times in the past as we constantly fielded questions about when a property value was created, what time it was last updated, what source type updated the value, or from what flow the value was updated. Instead of running ad hoc queries and pulling together information from multiple datastores, we centralized the metadata in a new table to make it easier to access and eventually expose Trust Levels.
We called this table business_property_metadata and gave it the following schema:

Here’s an example row of the business_property_metadata table:

We chose Cassandra over MySQL as the underlying datastore for this new table, and while our rationale for this could be a blog post of its own, here are the main reasons.
We knew the table would hold tens of millions of rows, and we could safely assume clients of the data would be accessing it using the primary key (business_id, business_property_name). Cassandra provides good read and excellent write performance for data at this scale when rows are always queried on this key, which Cassandra uses in part as a partition key to distribute a table’s data to different nodes.
MySQL, which is used extensively throughout Yelp, offers different benefits that were less important for this particular use case. We don’t anticipate needing efficient joins of this metadata with other data entities, nor do we foresee the need for strict transaction mechanisms or strong consistency guarantees around these fields. Cassandra’s eventual consistency semantics are enough for this type of business information.
As a final note on storage, our metadata table is easily extendable. We have already included a column, provenance, that captures different fields around the data’s source in case our downstream consumers need access to that information. In the future, we will be able to add more types of metadata to the table as use cases arise.
Serving Trust Levels (Online and Offline)
The final step in enabling our Trust Levels was ensuring that the data was accessible for various teams to use. To do this, we created new dedicated REST API endpoints for querying and writing to our metadata table. We also backfilled our metadata table with historical data that we already had and calculated Trust Levels for those properties. We then migrated existing calls around business properties to our new API endpoints in order to write live updates to our metadata table. Now, with our metadata table filled with values, internal clients can access Trust Levels and other metadata through our online APIs.
For offline access, we already had existing data streams of our business property data published to Yelp’s Data Pipeline and used by teams such as Search and Ads. We needed to make sure that the new metadata information was included alongside the property data in our data pipeline, while also ensuring that the data was easy to consume for our downstream clients.
In order to accomplish this, we first aggregated our data from the new metadata table along with other currently consumed tables, using a Yelp stream processing service called Flink Aggregator. The aggregator transforms the data stream to be similarly keyed by business_id, since metadata uses a different primary key (business_id, business_property_name). We then combine these streams using Joinery to produce one data stream that shows the entire current value of that business including metadata. This allows our downstream clients to utilize the same data stream with only slight modifications on their side to read the metadata — including Trust Levels — as well.
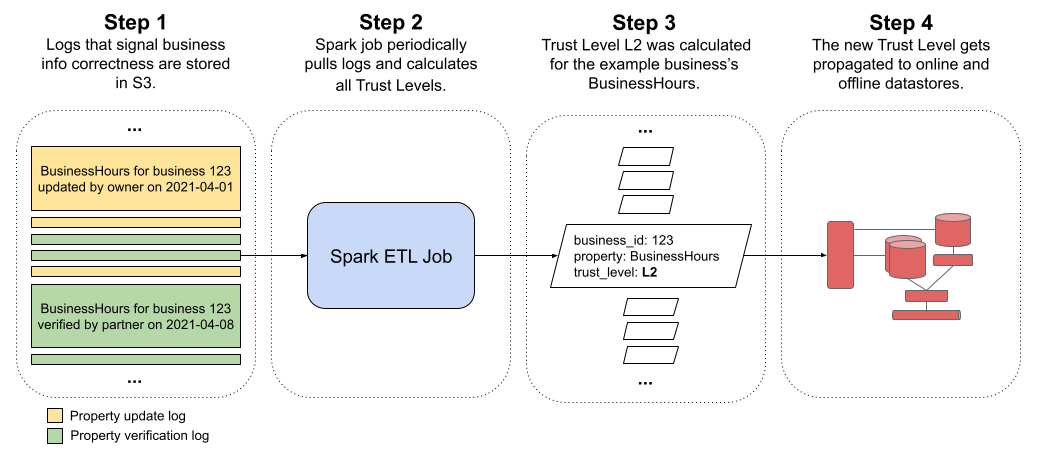
Example: Business Hours
To conclude, let’s connect all the steps described above by walking through an example for a business property that was updated a lot during COVID: Business Hours. Assume there is a business where the business owner last updated their hours two weeks ago, followed by a verification event from a data partner submitting the same hours one week ago. The following diagram illustrates the entire Trust Levels flow for this particular business property.
Anyone at Yelp can now use this authoritative confidence label however they need it. A front-end team could use it to power new UI components indicating recently updated hours. A Search engineer could experiment with incorporating it as a feature in a ranking model. A data scientist could analyze if accurate business hours data is correlated with higher user engagement. Whatever it is, the Trust Levels data is ready for them, and becomes another tool we use to build helpful features for consumers and business owners during these unprecedented times.
Acknowledgements
- We would like to thank Devaj Mitra, Surashree Kulkarni, Abhishek Agarwal, Pravinth Vethanayagam, Jeffrey Butterfield (author), Maria Christoforaki, Parthasarathy Gopavarapu, our Semantic Business Information team, our Database Reliability Engineering Team, and our Data Streaming teams who all helped make Trust Levels a reality.
- Thanks to Venkatesan Padmanabhan and Joshua Flank for technical reviewing and editing of this post.