Moderating Promotional Spam and Inappropriate Content in Photos at Scale at Yelp

-
Marcello Tomasini and Jeraz Cooper, Software Engineers
- May 12, 2021
The trust of our community of consumers and business owners is Yelp’s top priority. We take significant measures to maintain this trust through our state of the art review recommendation algorithms in order to maintain the integrity and quality of the content on our site. Albeit popular, review text is only one of the many types of user-generated content at Yelp. Photos are also a key piece of content and they are increasingly becoming an attack vector for spammers and inappropriate or other unwanted behavior. In this blog post we show how we built a scalable photo moderation workflow leveraging Yelp’s in-house real-time data streaming and processing pipeline, simple heuristics, and deep learning models in order to deal with hundreds of thousands of photo uploads per day.
Motivation
Yelp’s mission is to connect people with great local businesses. Local businesses are often small in size and might not have the resources to quickly identify and flag the content generated on their pages, especially if it is disruptive or deceiving, which could result in an impact in trust for both the business and its customers. Trust is deeply embedded in two Yelp values:
- Protect the source: community and consumers come first.
- Authenticity: tell the truth. Content found on Yelp should be reliable and accurate.
Yelp takes pride in its mission and values and it constantly strives to develop and improve the systems to protect business owners and users.
So we addressed two types of photo content spam: promotional and inappropriate.
Promotional spam is an inappropriate commercial message of extremely low value which tries to disguise itself as business owner content and often leads the user to being scammed (e.g. by showing a fake customer support number). We consider this a type of deceptive spam because it erodes the trust the users have on our platform.


Examples of promotional spam.
Inappropriate spam is content that can be interpreted as offensive or unsuitable in the specific context where it appears. Context is especially relevant for this type of spam as inappropriate content covers a broad range of situations where the classification can be fairly ambiguous depending on where the content appears or which content policy applies (Yelp Content Guidelines). We consider this a type of disruptive spam because it can be abusive and offensive if not outright disturbing. Examples of this type of spam are suggestive or explicit nudity (e.g., revealing clothes, sexual activity), violence (e.g., weapons, offensive gestures, hate symbols), drugs/tobacco/alcohol, etc.
Challenges
Users and business owners upload hundreds of thousands of photos every single day.
At this scale, the infrastructure and the resources required for real-time classification are a considerable challenge due to tight response time constraints required to maintain a good user experience. Additionally, processing photos using neural networks requires expensive GPU instances. Real-time classification is also not an ideal choice in an adversarial space because it provides immediate feedback to an attacker trying to circumvent or reverse engineer our systems. Having an indeterminate delay between content upload and moderation significantly increases the time cost for an attacker to reverse engineer the system. Conversely, unwanted content should be moderated as quickly as possible to protect our users and since spam tends to be generated in waves, if we fail to swiftly remove it we will likely end up with large swathes of unsafe content on the platform.
There are also challenges specifically related to the machine learning (ML) algorithms used to process image data. Promotional and inappropriate spam is fairly rare on Yelp which creates the problem of extremely unbalanced data, making training and evaluating ML algorithms a lot more challenging. While we can use smart sampling techniques to produce balanced datasets for training purposes, evaluation in production is highly skewed on trying to minimize false positives, which in turn affects the recall of spammy content. Another concern that we need to address is the context of a photo, especially for inappropriate content (e.g. a photo of a lingerie model in a lingerie shop is perfectly fine but it is not if it is on a restaurant business page), and an adversarial space which requires the ability to react quickly to evolving threats and constantly keep our models up to date.
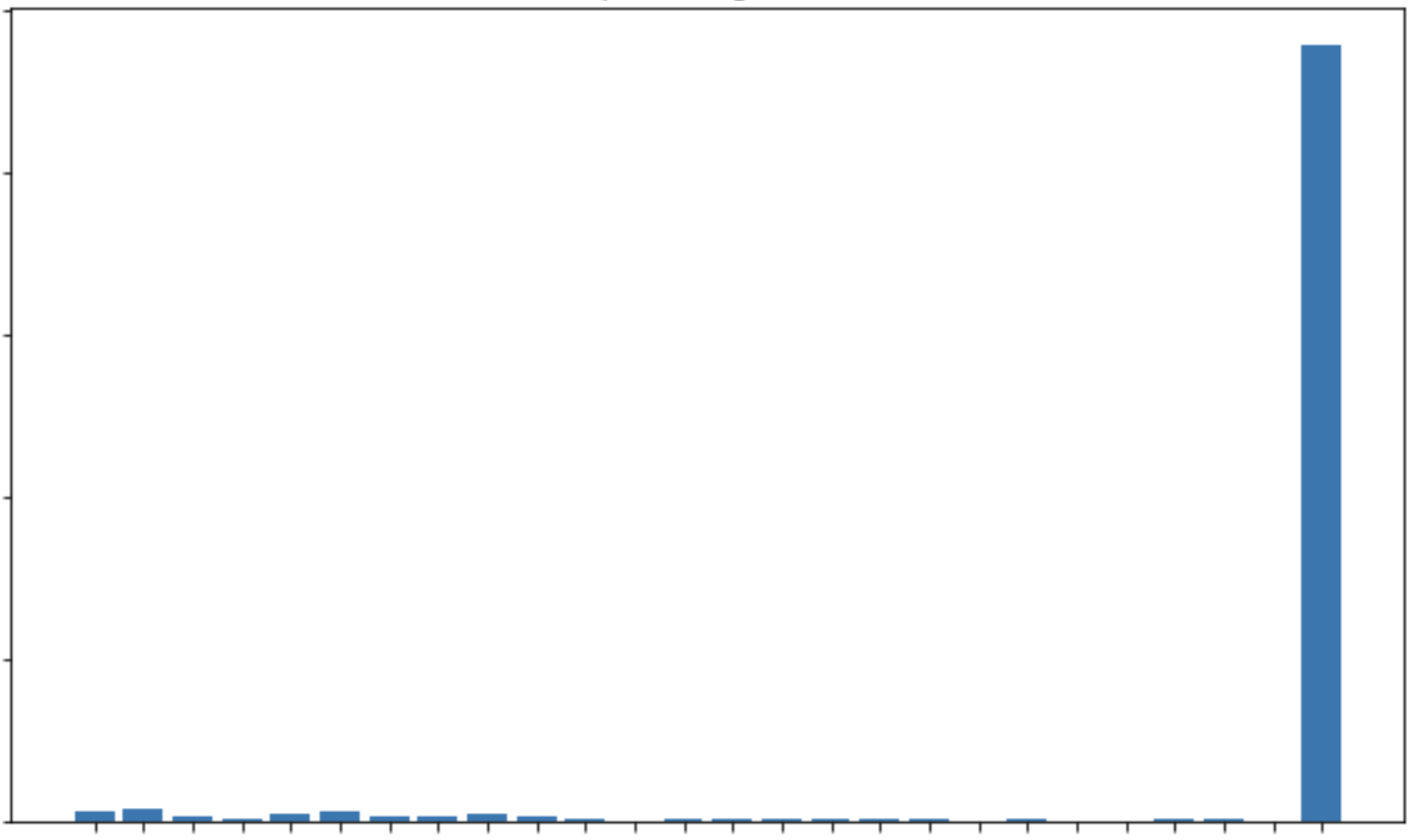
Distribution of content types, the far right bar is "good" content.
Solution Design
As we mentioned above, any moderation of user-generated content has to work in an adversarial space. Hence, we decided to not use any out-of-the-box or third party solutions which we considered vulnerable to an attacker reverse engineering because they are publicly available and therefore attackers can experiment with them and learn to bypass them before attacking Yelp. In this case, rolling out our own custom system plays security through obscurity to our advantage by buying us time against attackers which in turn allows us to remain ahead of the game.
Moreover, we discussed the issue in ML when dealing with class imbalance. In our solution we focused on precision while maintaining good recall. Precision and recall are inversely proportional but we prefer a “do no harm” approach where we minimize the false positive instances which would lead to removing valid content. This is incredibly important for businesses that have little content on their pages and for which removing a valid photo would have a non-negligible effect. A high precision solution also minimizes manual work for our content moderation team. This helps to deal with the continuous growth of Yelp since manual moderation does not really scale well and reduces the exposure to inappropriate content which can be psychologically taxing and potentially a liability.
Finally, while designing the system, we tried to leverage existing Yelp technologies and systems as much as possible to minimize engineering development cost and maintenance burden.
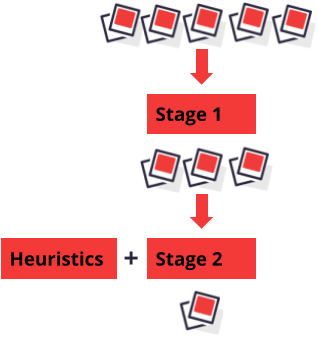
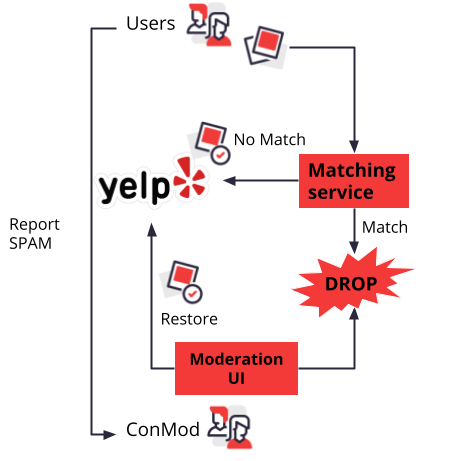
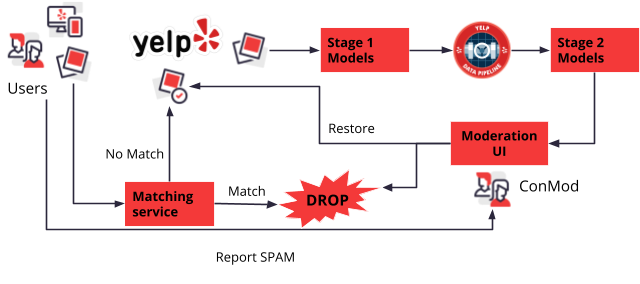
After considering the challenges in infrastructure, ML, and the adversarial space we settled for a multi-stage multi-model approach where there are two stages and different models for each stage and type of spam. The first stage is used to identify the subset of photos that are most likely to contain spam; the models in this stage are tuned to maximize spam recall while filtering out most of the safe photos. Essentially, this step changes the label distribution of the data fed into the second stage and in doing so it significantly reduces ham/spam class imbalance and removes many potential false positives (consider the following: we do not perform inference on a large subset of photos in the second stage, and the final set of false positive is only limited to the false positives generated by the second stage, which may or may not intersect with the false positives generated in the first stage). The second stage is where the actual classification of the content happens; the models in this stage are tuned for precision because we aimed to send only a small amount of content to the manual moderation queue and we wanted to keep false positives to a minimum. Moreover, we have a set of heuristics playing alongside ML models which speed up the whole pipeline and are quickly tunable so that we can react in a small amount of time to a new threat our models are not capable of handling which give us the time to update our models while keeping users protected. Finally, we created a Review Then Publish (RTP) moderation workflow UI where images that are identified as spam are hidden from the users and sent to our content moderation team for manual review. Yelp’s content moderation team then can decide to either restore a photo if it is a false positive or allow the photo to remain hidden if it’s malicious.
In the next sections we will dive into the details of what this solution looks like for each type of spam.
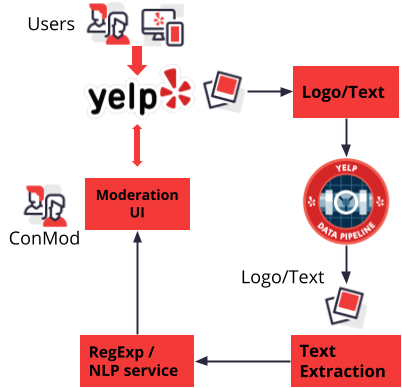
Promotional Spam
Most of the promotional spam is characterized by fairly simple graphics containing a bunch of text that is used to deliver the spam message. Therefore, the image-spam identification models used in the first stage try to identify photos containing text or logos; these models are mostly heuristic based and are very resource efficient. In the second stage, we extract the text from the photos using a deep learning neural network. The spam classification is then performed on the text content leveraging a regular expression and NLP service. The fast path provided by the regular expressions allows for an efficient recall of most egregious cases and provides the capability to quickly react to content that is not being captured by the NLP models.
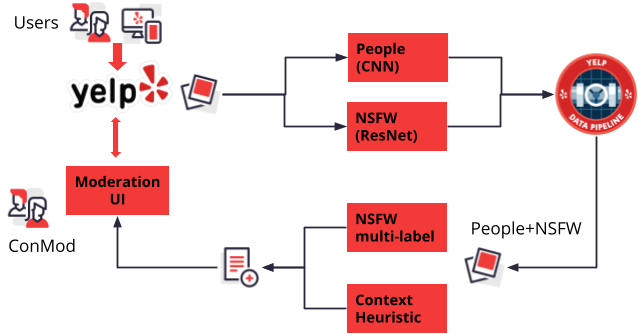
Inappropriate Spam
Inappropriate spam is much more complex than promotional spam because it covers a broad range of content. The classification is also heavily dependent on the context where it appears. In order to maximize recall, the first stage comprises two models: a thin ResNet trained on a binary classification task to identify inappropriate content in photos based on Yelp’s policies, and a deep CNN model trained on a binary classification task to identify photos containing people. This second model has been added specifically to maximize recall since many instances of inappropriate content involve people. The second stage combines a deep learning model trained on a multi-label classification task, where the output is a set of labels and associated confidence scores. The model is then calibrated for precision based on confidence scores and a set of context heuristics (e.g. the business category) that take into account where the content is being displayed.
Dealing with Spam Waves and Adversarial Actors
So far we covered mostly the ML aspects of the system and just briefly mentioned how heuristics can be used to quickly enhance the system to adapt to the changing threats coming from adversarial actors. Spam often hits websites in waves of very similar content that is generated from fake accounts piloted by bots. Hence, we have a workflow and a couple of infrastructure improvements specifically to address that. Photos flagged as spam are tracked by a fuzzy matching service. If a user tries to upload an image and the image matches a previous spam sample it is automatically discarded. On the other hand, if there is no similar spam match it goes through the pipelines mentioned above and it could end up in the content moderation team queue. While awaiting moderation the images are hidden from the users so that they are not exposed to potentially unsafe content. The content moderation team can also act on entire user profiles instead of just a single piece of user content. For example, if a user is found to be generating spam, its user profile is closed and all associated content is removed. This sensibly improves spam recall because we need to catch only one image from a user to be able to remove all unwanted content generated by the spam bot profile. Finally, the traditional user reporting channel exists which provides us with feedback to monitor the effectiveness of our systems.
Final Remarks
In this blog post we covered some of the solutions Yelp developed to process hundreds of thousands of photos per day using a two stage processing pipeline powered by state of the art ML models. We also implemented a RTP moderation workflow so that problematic content is hidden from users until moderation happens. Finally the system provides us with the flexibility to quickly respond to adversarial actors, fake accounts, and spam waves.
Trust & Safety is taken very seriously at Yelp and we are proud of the work we do to protect our users and business owners. As a result, Yelp is one of the most trusted review platforms on the web.
Acknowledgement
- Thanks to Jeraz Cooper for mentoring, countless code reviews, and enabling the photo support in the moderation UI.
- Thanks to Jonathan Wang for the insights on the inappropriate spam model.
- Thanks to Pravinth Vethanayagam and Nadia Birouty for consulting on system design and people and logo classifiers.