Nrtsearch: Yelp’s Fast, Scalable and Cost Effective Search Engine

-
Sarthak Nandi, Software Engineer and Umesh Dangat, Group Tech Lead
- Sep 21, 2021
Search and ranking are part of many important features of Yelp - from looking for a plumber to showing relevant photos of the dish you search for. These varied use-cases led to the creation of Yelp’s Elasticsearch-based ranking platform, allowing real-time indexing, learning-to-rank, lesser maintenance overhead, and enabling access to search functionality to more teams at Yelp. We recently built Nrtsearch, a Lucene-based search engine, to replace Elasticsearch.
Why Replace Elasticsearch?
Our Elasticsearch-based ranking platform had been working well with a wide variety of applications deployed on it. But as we onboarded more use-cases, Elasticsearch costs didn’t scale as well as we wanted them to. This is mainly due to:
- Document based replication - a document is indexed individually by every replica in Elasticsearch. We eventually need to scale out across replicas and not just vertically scale up the nodes, but scaling out replicas requires more CPU for indexing.
- With the shard distribution for multiple indices controlled by Elasticsearch, we would often end up with hot/cold nodes where CPUs on one node would be underutilized while some nodes ended up with shards that receive the majority of traffic. We had to ensure an even spread of shards to avoid this.
- Difficult to autoscale - Elasticsearch needs to migrate shards to new nodes from the existing nodes serving search traffic, making it harder to scale up in realtime. As a result, we always provision for peak capacity. Requiring an even spread of shards also requires scaling up or down in multiples of the number of shards and replicas in each index, further making autoscaling more complicated.
When we presented at Berlin Buzzwords about the Evolution of Yelp’s Ranking Platform, we attended a talk by Michael Sokolov and Mike McCandless about how Amazon used Lucene for e-commerce search at Amazon. There were two specific Lucene features mentioned in the talk that caught our attention:
- Near-real-time (NRT) segment replication - Lucene writes indexed data into segments, which are immutable and allow being searched over independently. A node acting as a primary can do all the indexing and the replica nodes can just pull these segments from the primary instead of re-indexing the document.
- Concurrent searching - Lucene can search over multiple segments in an index in parallel, taking advantage of multi-core CPUs. Thus, instead of parallelizing a search over multiple shards, we can parallelize it over multiple Lucene segments.
We decided to investigate further into Lucene-based replication since Elastic did not have plans to support this in Elasticsearch in the near future.
Design Goals
While NRT segment replication and concurrent search were the main features we wanted in our search engine, we also needed to maintain feature parity with existing systems. In addition, we required some features to fully support autoscaling. These were the design goals we set for our new system:
- Built on Lucene - this would let us reuse our custom native Java code with features like ML-based ranking, analysis, highlighting, and suggestions with minimal changes apart from providing near-real-time segment replication and concurrent search
- Minimal overhead on nodes serving search requests due to indexing and segment merges
- Optimize the system for search, not analytics
- Store a primary copy of the index in external storage (like Amazon S3) and not on local node storage so that nodes can be stopped and started without having to back up local instance storage
- Node startup must be fast and not require any rebalancing like Elasticsearch, so that new nodes can initialize quickly when there is increased load
- Stable extension API with proper interfaces allowing to distribute extensions that do not need to target a particular version. Most features (e.g., custom analysis, ML ranking support) are expected to be implemented within Java modules
- Point in time consistency for applications that need it
We also anticipated some other challenges as we built Nrtsearch. We use Kubernetes at Yelp to helps us solve these challenges outside Nrtsearch:
- Replacing a crashed primary - We decided not to build any functionality to handle crashed primaries in Nrtsearch and instead build this into our Kubernetes operator if needed.
- Load-balancing - Nrtsearch will not provide any server-side load-balancing to balance the load among the replicas. A replica that receives a query will execute it and return the response, so we need to divide the traffic equally among all replicas. We planned to rely on load-balancing in our service mesh, but we eventually also added round-robin load balancing to the Nrtsearch Java client library.
- We decided to not add a transaction log to Nrtsearch and require clients to call commit periodically to make recent changes durable on disk. This means that, in the event of a primary node crash, all indexed documents since the last commit would be lost. Our Flink-based indexing system automatically creates a checkpoint and calls commit in Nrtsearch after a specified time duration or a specific number of documents. If there is a failure due to a primary node crashing or restarting, it would revert to the previous checkpoint and resend the indexing requests since that checkpoint.
Implementation
We decided to base our search-engine off of Mike McCandless’ open-source Lucene Server project since it is built on Lucene, uses near-real-time segment replication with indexing on primary and search on replicas, and has APIs for indexing and searching documents. The project uses Lucene 6.x, so we first upgraded to Lucene 8. We then replaced the REST/JSON-based API with gRPC/protobuf to improve serialization/deserialization performance. We also used gRPC for the NRT segment replication between primary and replicas as Lucene leaves the decision to API implementers. While gRPC is excellent for communication between micro-services, we still have some existing REST clients and Swagger-based services. gRPC also makes it harder for humans to directly query the service. We used grpc-gateway to add a REST API to handle these concerns. The gateway runs externally to Nrtsearch so services can still talk to it using gRPC. We also leveraged concurrent search to search over multiple segments in parallel and added doc value support for lookups.
We made some changes to the initial planned design around NRT segment replication. Instead of the primary writing segments to disk and then uploading segments to an external store like Amazon S3, we decided to use a persistent storage volume (like Amazon EBS). As a result, if a primary node restarts and moves to a different instance, we don’t need to download the index to the new disk; instead, we only need to attach the EBS volume, allowing the primary node to start up much faster and reducing the indexing downtime. We call the backup endpoint occasionally on the primary to backup the index to S3. When replicas start, they download the most recent backup of the index from S3 and then sync the updates from the primary. When the primary indexes documents, it publishes updates to all replicas, which can then pull the latest segments from the primary to stay up to date. Note that the communication between primary and replicas uses gRPC as well. This is how the architecture looks like:
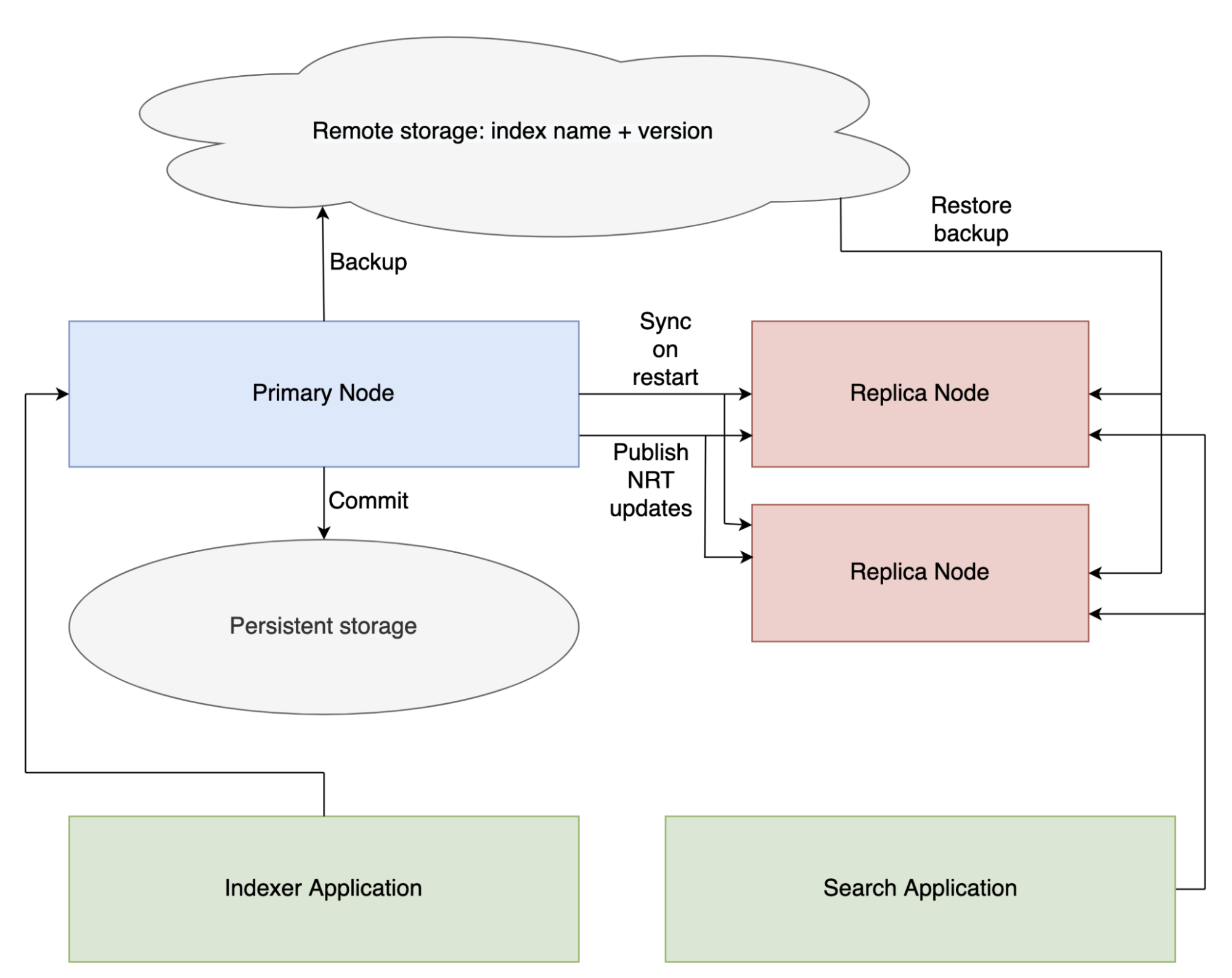
NRT Architecture
As we deployed Nrtsearch for heavier use-cases, we kept adding more features to support them. This included features like facets, nested fields, and plugin support for various purposes like ranking, highlighting, analyzing, and adding custom field types to have parity with Elasticsearch features. We also added several features to improve performance, such as virtual sharding, which makes the distribution of segments to threads for concurrent search more even, parallel fetch of document fields to improve timings for large recall, segment level search timeout, and index warming on replicas. We have also added several index, node, JVM and process-related metrics in Nrtsearch to provide observability and to help debug any issues.
At Yelp we use Kubernetes underneath Paasta (our platform as a service) for running services, and since we are also migrating datastores to it it made sense to run Nrtsearch on Kubernetes as well. However, since Nrtsearch requires some special handling (e.g., restoring indices from S3 on startup and using the same EBS volume across primary restarts), we created a Kubernetes operator for Nrtsearch. The operator takes care of building the configuration for a node, creating a Kubernetes service that is used for communication between primary and replicas, creating the primary and replica statefulsets, and registering the pods for service discovery. We also use the horizontal pod autoscaler offered by Kubernetes to autoscale the replicas according to the load. Since the replicas download the most recent backup from S3, they are quick enough to start. This also lets us run the replicas on pools of cheaper spot instances instead of reserved instances.
Migrating Existing Workflows
We have migrated several search use-cases to Nrtsearch over the past year. We started with a feature that has relatively low traffic and requires a small index, and then moved on to larger and more complex use-cases. Most of our search use-cases go through Apollo, a proxy for Elasticsearch clients. For these clients, we only needed to make changes in Apollo to make the requests go to Nrtsearch.
We did phased rollouts to avoid causing an outage due to any unforeseen issues. We started with a 1% dark-launch, which is where we sent traffic to both Elasticsearch and Nrtsearch but only returned results from Elasticsearch. While monitoring the system for stability, we steadily increased the dark-launch to 100%. A 100% dark-launch confirmed that the performance of the new system was up to the mark. We also compared the results from Elasticsearch and Nrtsearch to make sure that there were no differences due to the migration. After making sure that the results hadn’t changed and the new system was performant, we started live-launching, again in a phased manner going from 1% (or even 0.1% in some cases) to 100%, while ensuring that the metrics did not deteriorate in the process.
We also used evals to check for differences in responses. The eval tool takes a set of requests and sends them to two different endpoints, which may return the same or different results. The tool can then find the differences and help us identify what component in the scoring caused a difference in the final score.
We had one more complexity related to migrations: existing custom Elasticsearch plugins that we had built over the years. We have plugins for discovering Elasticsearch nodes, custom analysis plugins, and a maptype plugin for fast doc-value lookups and custom scoring plugins. We needed to migrate the analysis, scoring and maptype plugins to Nrtsearch to have the same results and scores as Elasticsearch. While we had to create the required plugin interfaces in Nrtsearch, using Lucene made migrating the plugins easier. An additional benefit of Nrtsearch here is that rolling restarts of a cluster to use a new plugin version is quicker since it doesn’t involve any shard movement. In addition, for use-cases where the data is spread among multiple clusters, we can restart a node in every cluster at the same time whereas, for Elasticsearch, we used to restart only one node at a time and required a special tool to do it automatically in a reliable manner.
These are some of the high-level details of how we migrated existing workflows to Nrtsearch, but watch this space for more detailed posts about our migrations to Nrtsearch!
Wins
We improved our 50th, 95th and 99th percentile timings by 30-50% after migrating to Nrtsearch. These improved timings are even more impressive considering we reduced our infrastructure costs by migrating to Nrtsearch – as much as 40% for some use-cases. This was a result of running on a shared pool of spot instances and autoscaling according to our fluctuating traffic patterns. Thanks to autoscaling, we no longer needed to maintain excess nodes to handle traffic peaks or region failovers.
To illustrate some of the benefits of migrating to Nrtsearch, below are timing charts with Elasticsearch timings in blue and Nrtsearch timings in green that show the performance gains.
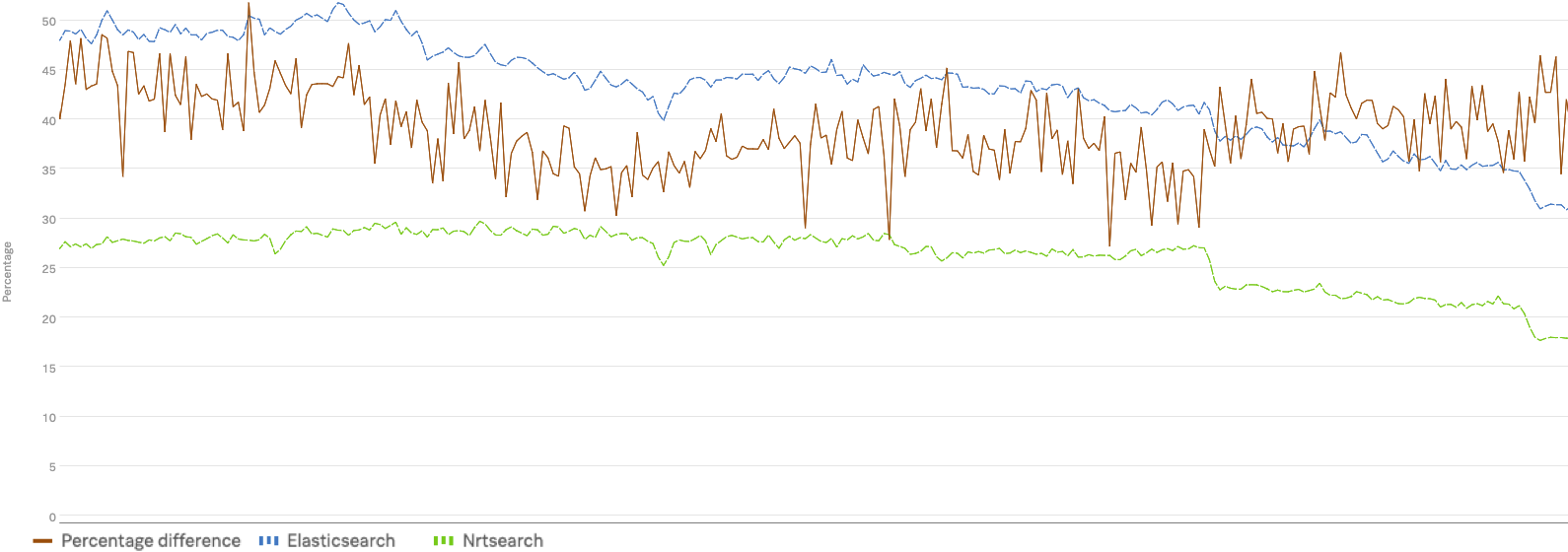
P50
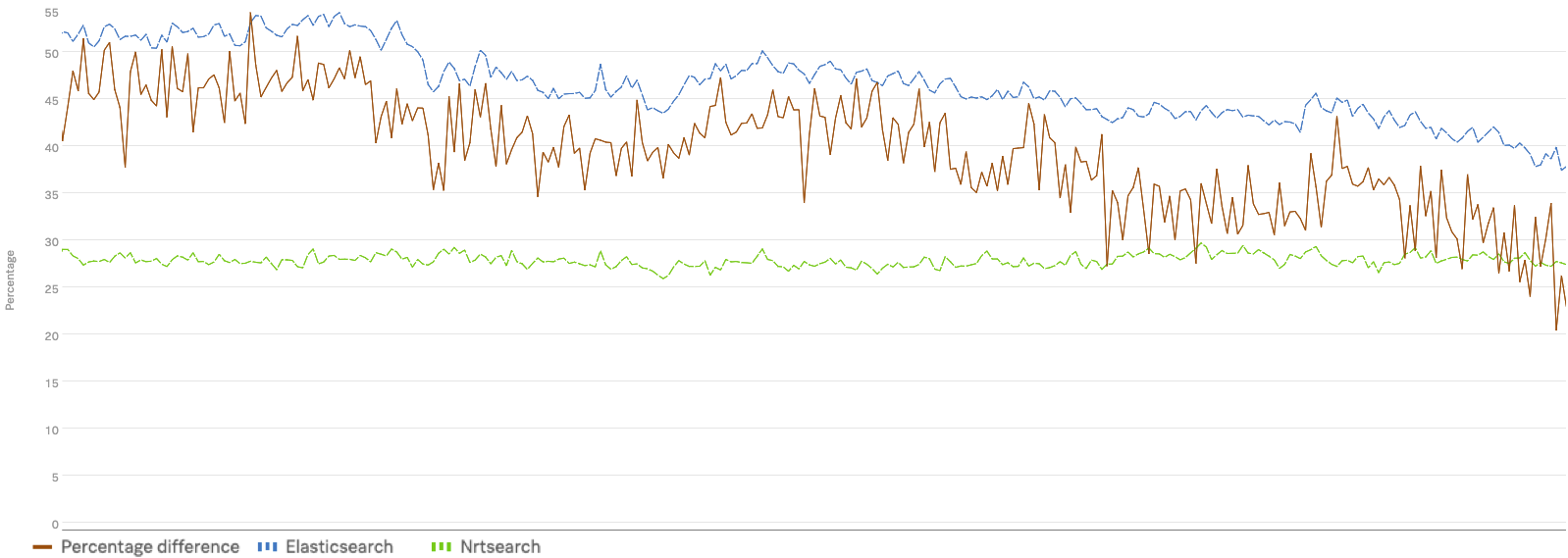
P95
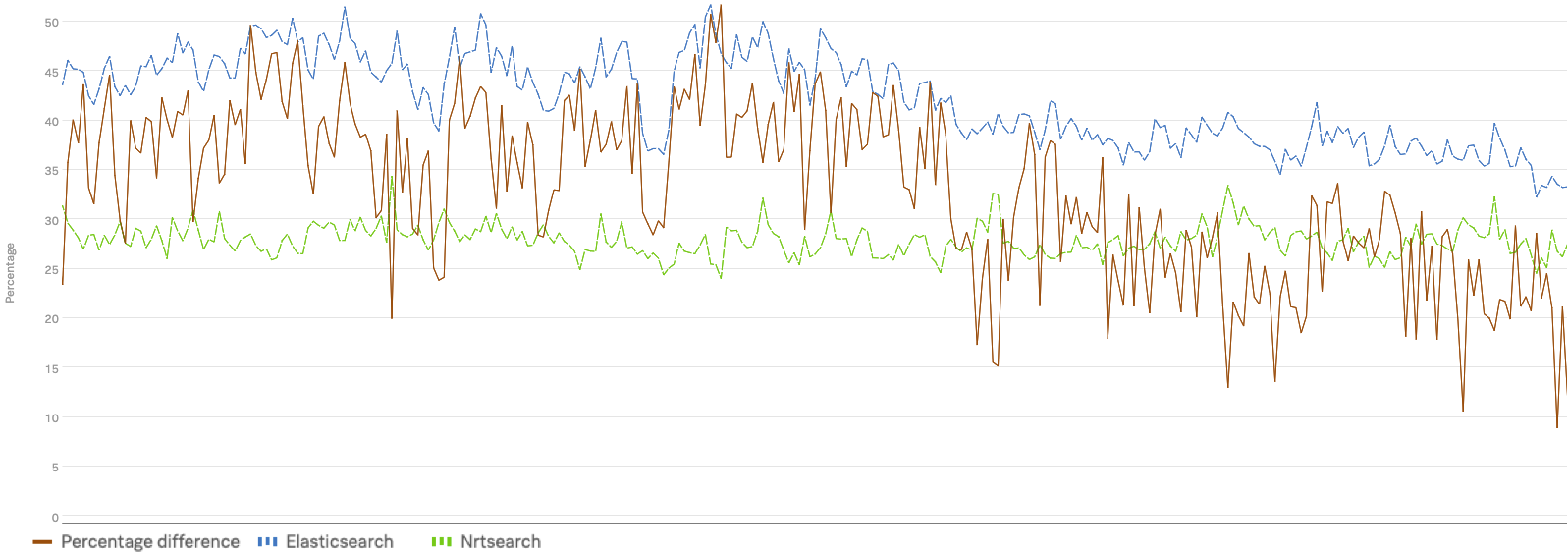
P99
Learnings
The path to the timing improvements illustrated above was long and involved lots of debugging, profiling, and tweaks. These included:
- caching compiled scripts,
- virtual sharding to evenly distribute segments to search threads,
- parallel fetch to aid high-recall use-cases,
- warming queries, and
- syncing the replica with a primary before the index itself has fully started to avoid high timings at startup.
Performance issues are tricky to troubleshoot since the cause of the highest degradation will dwarf any other underlying issues until it’s resolved. As a result, improving Nrtsearch’s performance required several iterations to find and address the various root causes, which took more time than we had planned for in our migration.
Another learning was around geosharding. We already split our Elasticsearch indices according to geographic locations in documents, so searches in specific geographic areas could scan through fewer documents. We planned to create smaller geoshards for Nrtsearch to have smaller indices and quicker bootstrap timings for replicas, but our largest geoshards also turned out to be extremely dense. Since some searches can cover areas that are tens of square miles large, this would make it hard to keep searches within one geoshard without duplicating a significant portion of these dense geoshards. We eventually made the backup and restore functionality faster by streaming the compressed file and uncompressing the stream instead of downloading the entire file and then uncompressing it. We also tried multiple implementations of compression libraries starting with gzip and eventually using LZ4. This made the replica bootstrap fast enough for our requirements, but we still need to be careful about increasing index sizes.
Future Work
We have already open sourced Nrtsearch while we continue to make improvements to it. We have planned the migration of several other use-cases that require features like search suggestions and highlights. We also plan to expose more Lucene queries via our search DSL and add support for ranking via MLeap, which is a serialization format and execution engine to make ML models portable without affecting performance. To tackle some use-cases where the index is not geoshardable, we plan to create a scatter-gather functionality externally to Nrtsearch where a service will query multiple clusters and then combine the results to address these requirements.
Acknowledgements
Several people from different teams at Yelp have contributed to make Nrtsearch a success, but we want to especially thank Andrew Prudhomme, Erik Yang, Jedrzej Blaszyk, Karthik Alle, Samir Desai, and Tao Yu for their contributions to Nrtsearch. We would also like to thank Mike McCandless for his initial feedback on our prototype and encouraging the overall segment-based replication design.
Become a Data Backend Engineer at Yelp
Do you love building elegant and scalable systems? Interested in working on projects like Nrtsearch? Apply to become a Data Backend Engineer at Yelp.
View Job