Kafka on PaaSTA: Running Kafka on Kubernetes at Yelp (Part 1 - Architecture)

-
Lennart Rudolph, Software Engineer
- Dec 15, 2021
Yelp’s Kafka infrastructure ingests tens of billions of messages each day to facilitate data driven decisions and power business-critical pipelines and services. We have recently made some improvements to our Kafka deployment architecture by running some of our clusters on PaaSTA, Yelp’s own Platform as a Service. Our Kubernetes (k8s) based deployment leverages a custom Kubernetes operator for Kafka, as well as Cruise Control for lifecycle management.

Kafka on PaaSTA on Kubernetes
Architectural Motivations and Improvements
In the past, all of our Kafka clusters ran on dedicated EC2 instances on AWS. Kafka was deployed directly on these hosts and configuration management was highly reliant on our centralized Puppet repository. The deployment model was somewhat cumbersome and creating a new cluster took over two hours on average. We set out to develop a new deployment model with the following goals in mind:
- Reduce the dependency on slow Puppet runs.
- Promote adoption of PaaSTA internally and leverage its CLI tools to improve productivity.
- Improve maintainability of our lifecycle management system.
- Simplify the process of performing OS host level upgrades and Kafka version upgrades.
- Streamline the creation of new Kafka clusters (aligned with how we deploy services).
- Expedite broker decommissions and simplify recovery process when hosts fail. Having the ability to re-attach EBS volumes also allows us to avoid unnecessarily consuming network resources, which helps save money.
Yelp had previously developed practices for running stateful applications on Kubernetes (e.g. Cassandra on PaaSTA and Flink on PaaSTA), so PaaSTA was a natural choice for this use case.
The new deployment architecture leverages PaaSTA pools–or groups of hosts–for its underlying infrastructure. Kafka broker pods are scheduled on Kubernetes nodes in these pools, and the broker pods have detachable EBS volumes. Two key components of the new architecture are the Kafka operator and Cruise Control, both of which we will describe in more detail later. We deploy instances of our in-house Kafka Kubernetes operator and various sidecar services on PaaSTA, and one instance of Cruise Control is also deployed on PaaSTA for each Kafka cluster.
Two crucial distinctions between the new architecture and the old architecture are that Kafka now runs within a Docker container, and our configuration management approach no longer relies on Puppet. Configuration management is now in accord with the PaaSTA-based configuration management solution in which Jenkins propagates YAML file changes whenever they are committed to our service config repository. As a result of this architectural overhaul, we’re now able to leverage existing PaaSTA CLI tooling to see the status of clusters, read logs, and restart clusters. Another major benefit is that we’re now able to provision new Kafka clusters by providing the requisite configuration (see below), and this approach has allowed us to halve the time taken to deploy a new Kafka cluster from scratch.
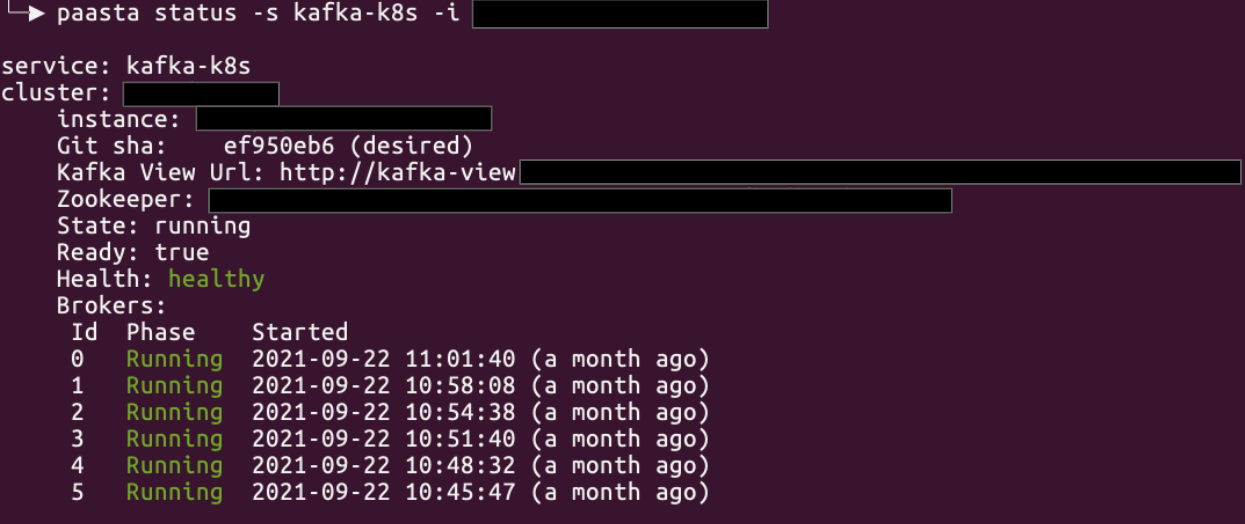
PaaSTA Tooling Example
example-test-prod:
deploy_group: prod.everything
pool: kafka
brokers: 15
cpus: 5.7 # CPU unit reservation breakdown: (5.7 (kafka) + 0.1 (hacheck) + 0.1 (sensu)) + 0.1 (kiam) = 6.0 (as an example, consider that our pool is comprised of m5.2xlarge instances)
mem: 26Gi
data: 910Gi
storage_class: gp2
cluster_type: example
cluster_name: test-prod
use_cruise_control: true
cruise_control_port: 12345
service_name: kafka-2-4-1
zookeeper:
cluster_name: test-prod
chroot: kafka-example-test-prod
cluster_type: kafka_example_test
config:
unclean.leader.election.enable: "false"
reserved.broker.max.id: "2113929216"
request.timeout.ms: "300001"
replica.fetch.max.bytes: "10485760"
offsets.topic.segment.bytes: "104857600"
offsets.retention.minutes: "10080"
offsets.load.buffer.size: "15728640"
num.replica.fetchers: "3"
num.network.threads: "5"
num.io.threads: "5"
min.insync.replicas: "2"
message.max.bytes: "1000000"
log.segment.bytes: "268435456"
log.roll.jitter.hours: "1"
log.roll.hours: "22"
log.retention.hours: "24"
log.message.timestamp.type: "LogAppendTime"
log.message.format.version: "2.4-IV1"
log.cleaner.enable: "true"
log.cleaner.threads: "3"
log.cleaner.dedupe.buffer.size: "536870912"
inter.broker.protocol.version: "2.4-IV1"
group.max.session.timeout.ms: "300000"
delete.topic.enable: "true"
default.replication.factor: "3"
connections.max.idle.ms: "3600000"
confluent.support.metrics.enable: "false"
auto.create.topics.enable: "false"
transactional.id.expiration.ms: "86400000"The New Architecture in Detail
One primary component of the new architecture is the Kafka Kubernetes operator which helps us manage the state of the Kafka cluster. While we still rely on external ZooKeeper clusters to maintain cluster metadata, message data is still persisted to the disks of Kafka brokers. Since Kafka consumers rely on persistent storage to be able to retrieve this data, Kafka is considered a stateful application in the context of Kubernetes. Kubernetes natively exposes abstractions for managing stateful applications (e.g. StatefulSets), but Kubernetes has no notion of Kafka-specific constructs by default. As such, we needed additional functionality beyond that of the standard Kubernetes API to maintain our instances. In the parlance of Kubernetes, an operator is a custom controller which allows us to expose this application-specific functionality.
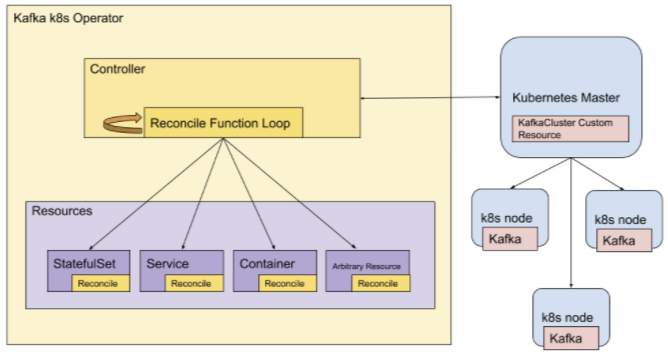
Kafka Operator Overview
The operator is in charge of establishing when Kubernetes needs to perform an action on the cluster. It has a reconcile loop in which it observes the state of custom cluster resources and reconciles any discrepancies by interacting with the Kubernetes API and by calling APIs exposed by another key architectural component: Cruise Control.
Cruise Control is an open-source Kafka cluster management system developed by LinkedIn. Its goal is to reduce the overhead associated with maintaining large Kafka clusters. Each Kafka cluster has its own dedicated instance of Cruise Control, and each cluster’s operator interacts with its Cruise Control instance to perform lifecycle management operations such as checking the health of the cluster, rebalancing topic partitions and adding/removing brokers.
The paradigm used by Cruise Control is in many ways similar to the one used by the operator. Cruise Control monitors the state of the Kafka cluster, generates an internal model, scans for anomalous goal violations, and attempts to resolve any observed anomalies. It exposes APIs for various administrative tasks and the aforementioned lifecycle management operations. These APIs serve as a replacement for our prior ad hoc lifecycle management implementations which we used for EC2-backed brokers to perform conditional rebalance operations or interact with AWS resources like SNS and SQS. Consolidating these into one service has helped to simplify our lifecycle management stack.
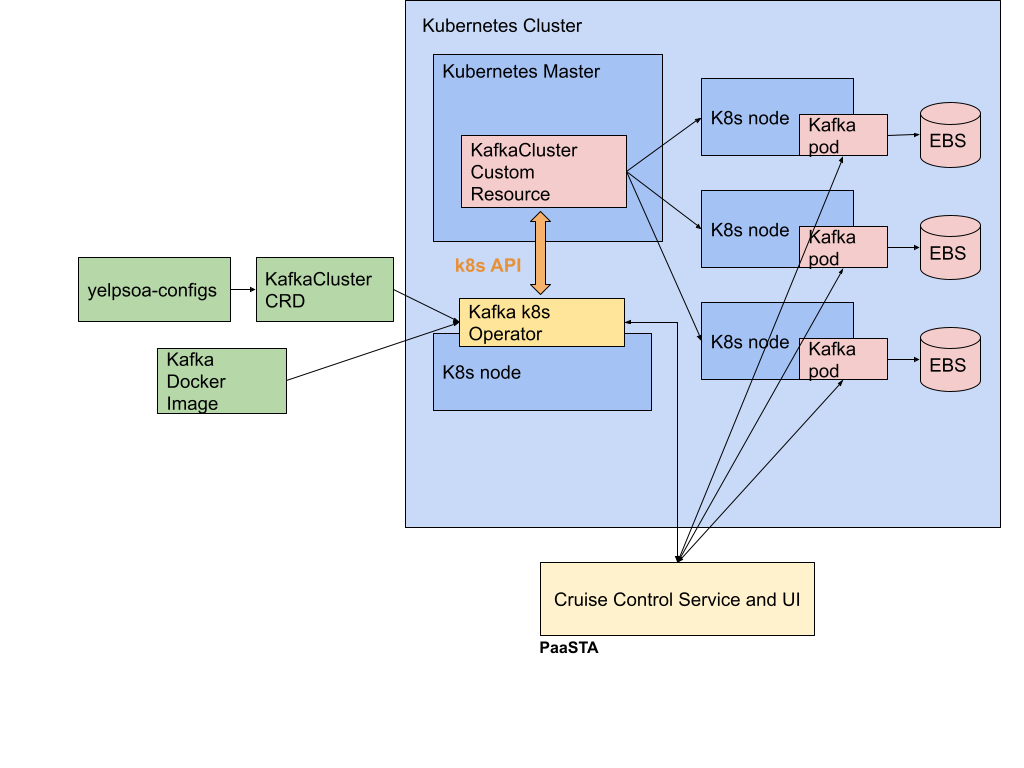
Cluster Architecture
Putting these components together, we arrive at a cluster architecture in which we define a Custom Resource Definition (CRD) through our internal config management system and couple it with a custom Kafka Docker image. The Kafka Kubernetes operator uses the config, CRD, and the Docker image in its interaction with the Kubernetes API to generate a KafkaCluster Custom Resource on a Kubernetes master. This allows us to schedule Kafka pods on Kubernetes nodes, and the operator oversees and maintains the health of the cluster through both the Kubernetes API and the APIs exposed by the Cruise Control service. Humans can observe the cluster and interact with it through the Cruise Control UI or PaaSTA CLI tools.
Finally, we’d like to illustrate the overall flow of operations with an example scenario. Consider the case of scaling down the size of the cluster by removing a broker. A developer updates the cluster’s config and decrements the broker count, which in turn updates the Kafka cluster’s CRD. As part of the reconcile loop the operator recognizes that the desired cluster state differs from the actual state represented in the StatefulSet, so it asks Cruise Control to remove a broker. Information about the removal task is returned by the Cruise Control API, and the operator annotates the decommissioning pod with metadata about this task. While Cruise Control performs the process of moving partitions away from the broker to be decommissioned, the operator routinely checks the status of the decommission by issuing requests to Cruise Control. Once the task is marked as completed, the operator removes the pod and the internal state of the cluster spec has been reconciled.
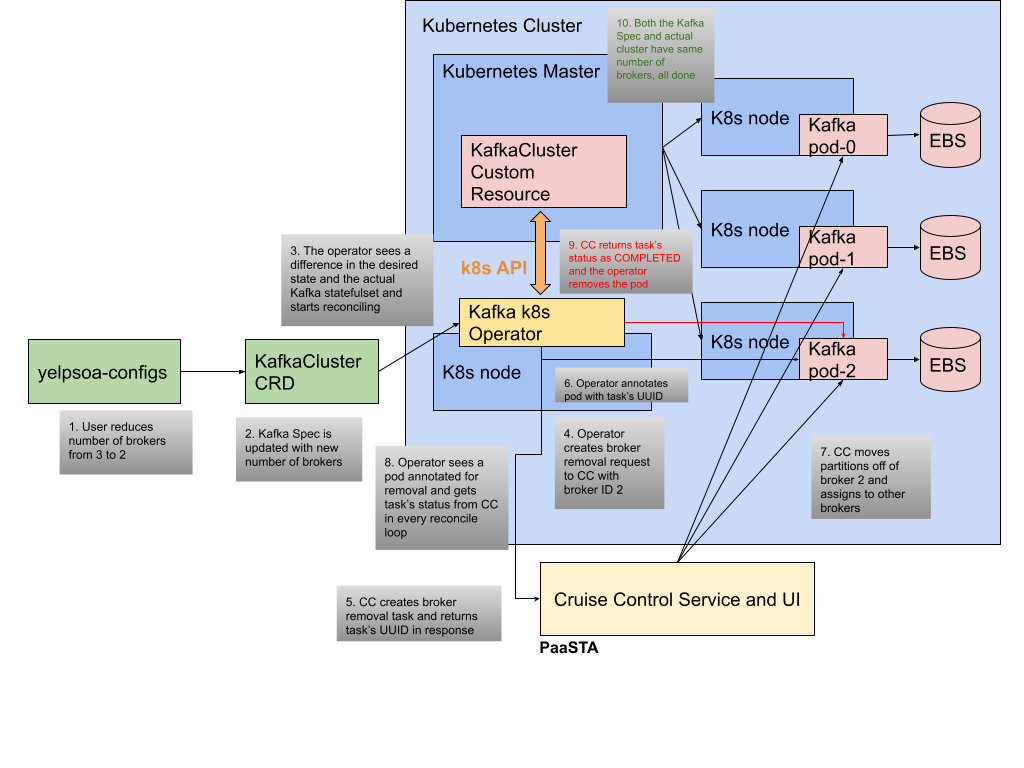
Scale Down Scenario
What comes next?
After designing this architecture we built tooling and constructed a process for seamlessly migrating Kafka clusters from EC2 to PaaSTA. As of this post we have migrated many of our clusters to PaaSTA, and we’ve deployed new clusters using the architecture detailed here. We’re also continuing to tune our hardware selection to accommodate different attributes of our clusters. Stay tuned for another installation in this series where we will share our migration process!
Acknowledgements
Many thanks to Mohammad Haseeb for contributing to the architecture and implementation of this work, as well as for providing the architecture figures. I would also like to thank Brian Sang and Flavien Raynaud for their many contributions to this project. Finally, I’d like to thank Blake Larkin, Catlyn Kong, Eric Hernandez, Landon Sterk, Mohammad Haseeb, Riya Charaya, and Ryan Irwin for their insightful review comments and guidance in writing this post.
Principal Platform Software Engineer (Data Streams) at Yelp
Want to build next-generation streaming data infrastructure?
View Job