Kafka on PaaSTA: Running Kafka on Kubernetes at Yelp (Part 2 - Migration)

-
Lennart Rudolph, Software Engineer
- Mar 3, 2022
In a previous post we detailed the architecture and motivation for developing our new PaaSTA-based deployment model. We’d now like to share our strategy for seamlessly migrating our existing Kafka clusters from EC2 to our Kubernetes-based internal compute platform. To help facilitate the migration, we built tooling which interfaced with various components of our cluster architecture to ensure that the process was automated and did not impair clients’ ability to read or write Kafka records.
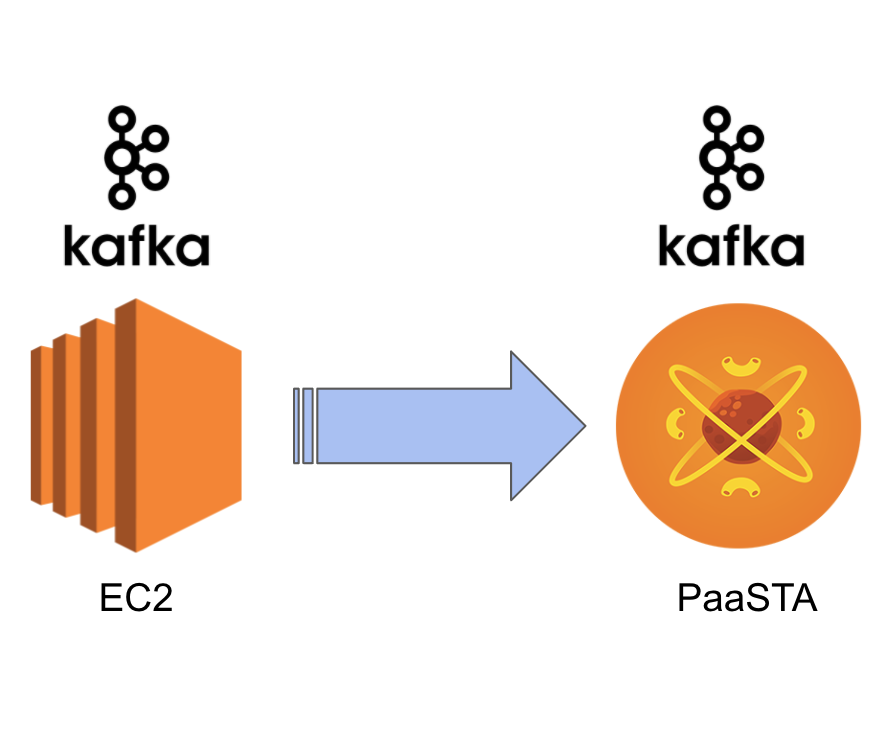
Migrating Kafka on EC2 to Kafka on PaaSTA
Background
In the status quo implementation, EC2-backed Kafka brokers within a cluster were associated with an auto scaling group (ASG). Attached to each ASG was an Elastic Load Balancer (ELB) which facilitated all connections to the cluster and acted as an entrypoint. Several auxiliary services and jobs also accompanied each cluster, but most of these were already deployed on PaaSTA. However, some important management systems ran directly on Kafka servers as cron jobs. Of particular importance for this redesign were the cluster rebalance algorithm and the topic auto partitioning algorithm. The rebalance algorithm attempts to evenly distribute partitions and leaders across the brokers of the cluster, while the auto partitioning algorithm automatically sets topic partition counts based on throughput metrics. Since we were already planning on incorporating Cruise Control in our architecture, now was a good time to migrate to a new rebalancing algorithm.
Thus, the three critical components we focused on replacing during this migration were the cluster entrypoint, the cluster balancing algorithm, and the topic auto partitioning algorithm. We didn’t need to look far for a replacement to the ELB since PaaSTA natively provides load balancing capabilities through Yelp’s service mesh, which makes it simple to advertise the Kafka on Kubernetes containers which compose a cluster. In the status quo EC2 scenario we also ran a custom rebalance algorithm on Kafka hosts, but this was ultimately replaced by Cruise Control (see part 1 for more details on this service) which exposed comparable functionality. Finally, our Puppet-based cron job running a topic auto partitioning script was replaced with a similar Tron job running on PaaSTA. Below is a table providing an overview of the different components across the deployment approaches.
| Component | EC2 | PaaSTA |
|---|---|---|
| Cluster Entrypoint | ELB | Yelp’s service mesh |
| Cluster Balance | rebalance algorithm in kafka-utils | Cruise Control |
| Topic Auto Partitioning | cron job (Puppet-based) | Tron job |
Since we would not be migrating all of our clusters simultaneously, we wanted to avoid the need to make significant changes to our Kafka cluster discovery configuration files. For additional context, at Yelp we use a set of kafka_discovery files (generated by Puppet) which contain information about each cluster’s bootstrap servers, ZooKeeper chroot, and other metadata. Many of our internal systems (such as Schematizer and Monk) rely on the information in these files. This migration strategy entailed updating only the broker_list to point to the service mesh entrypoint, thereby retaining compatibility with our existing tooling. We did take this migration as an opportunity to improve the propagation method by removing Puppet as the source of truth and instead opted to use srv-configs (the canonical place for configurations used by services). An example discovery file is shown below:
>> cat /kafka_discovery/example-cluster.yaml
---
clusters:
uswest1-devc:
broker_list:
- kafka-example-cluster-elb-uswest1devc.<omitted>.<omitted>.com:9092
- kafka-example-cluster-elb-uswest1devc.<omitted>.<omitted>.com:9092
zookeeper: xx.xx.xx.xxx:2181,xx.xx.xx.xxx:2181,xx.xx.xx.xxx:2181/kafka-example-cluster-uswest1-devc
local_config:
cluster: uswest1-devc
...
Migration Strategy Overview
At a high level the goal of the migration was to seamlessly switch from using EC2-compatible components to using PaaSTA-compatible components without incurring any downtime for existing producer and consumer clients. As such, we needed to ensure that all the new components were in place before migrating any data from EC2-based brokers to PaaSTA based-brokers. We also wanted to minimize the amount of engineering time required for the migrations, so we implemented some tools to help automate the process. Finally, we needed to ensure that this process was thoroughly tested and rollback-safe.
The first step of the migration process was to set up a PaaSTA-based load balancer for each of our Kafka clusters, which could also be used to advertise EC2-based brokers. This exposed two distinct methods of connecting to the Kafka cluster: the existing ELB and the new service mesh proxy which would be used for the PaaSTA-based brokers during and after the migration. This entailed updating the aforementioned kafka_discovery files to include the alternate connection method, and we also devised a new way to propagate these files with a cron job rather than rely on Puppet. As alluded to in the prior post, reducing our reliance on Puppet helped us halve the time to deploy a new Kafka cluster since we could alter and distribute these configuration files much more quickly. After this was done we also invalidated any related caches to ensure that no clients were using the outdated cluster discovery information. Below is a set of figures illustrating this process during the migration:
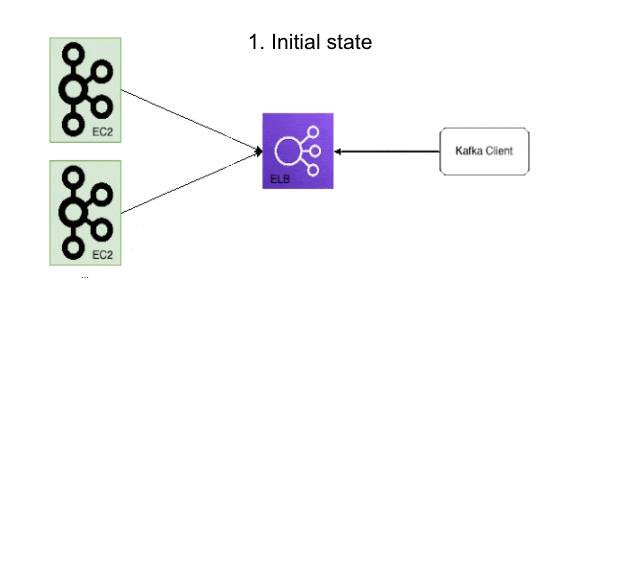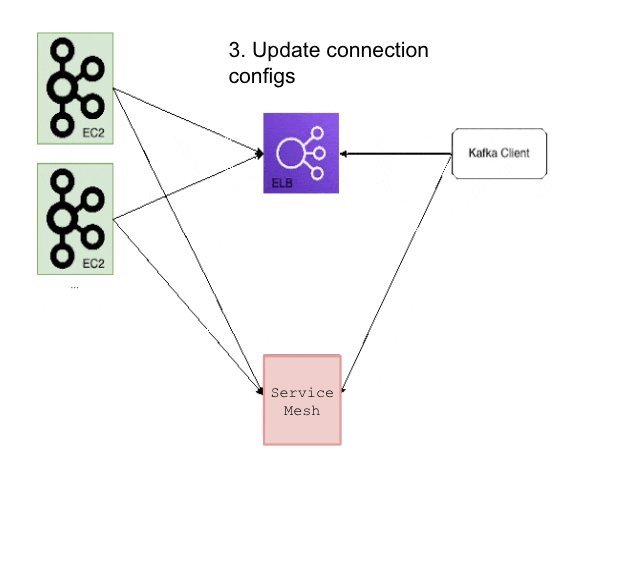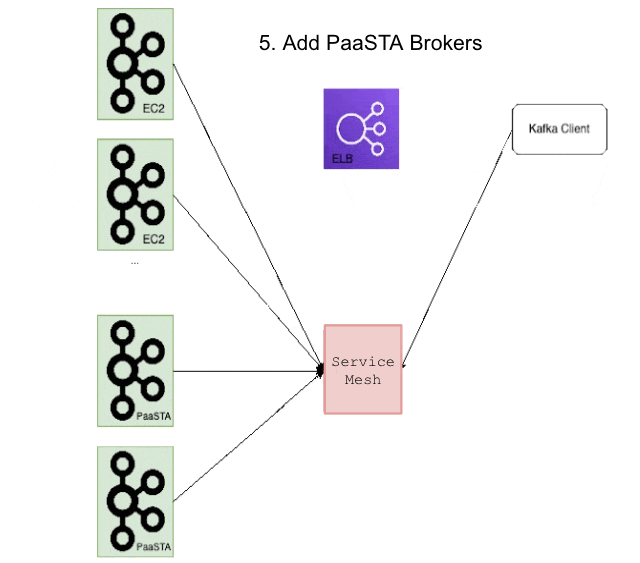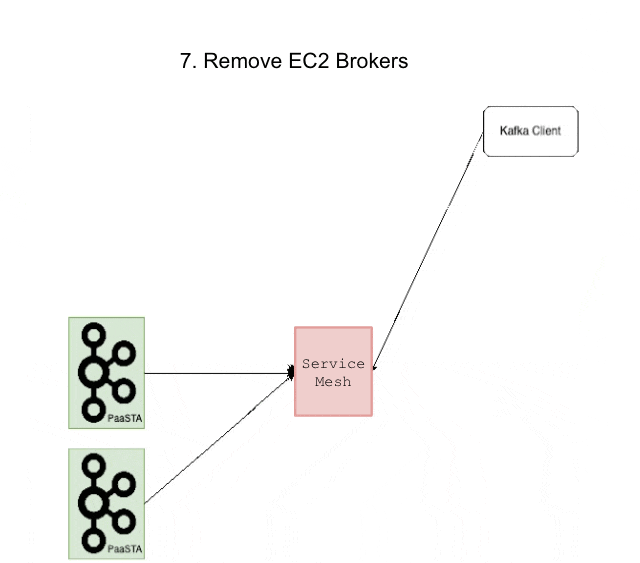
Cluster Connection Migration
Next, we deployed a dedicated instance of Cruise Control for the cluster, with self-healing disabled. We didn’t want multiple rebalance algorithms to run simultaneously, and since the self-healing algorithm is able to rebalance the cluster, we prevented Cruise Control from automatically moving topic partitions. After this we created a PaaSTA instance for the cluster, except we explicitly disabled the Kafka Kubernetes operator’s use of Cruise Control. For an EC2 cluster with N brokers we then added an additional N PaaSTA-based brokers, effectively doubling the cluster size during the migration.
After the new PaaSTA brokers were online and healthy, the cluster had an equal number of EC2 brokers and PaaSTA brokers. We also enabled metrics reporting by creating the __CruiseControlMetrics topic and setting up the appropriate configs prior to each migration. To retain control over when partitions would be moved, we disabled our status quo automated rebalance algorithm. At this point we were ready to start moving data away from the EC2 brokers and leveraged Cruise Control’s API to remove them. Note that this API only moves partitions away from the specified brokers and does not actually decommission the hosts. We continued to send heartbeats for EC2 lifecycle actions throughout the migration procedure since the autoscaling group associated with the EC2 brokers would persist until the end of the migration process. Below is a figure illustrating the state of each component throughout the migration:
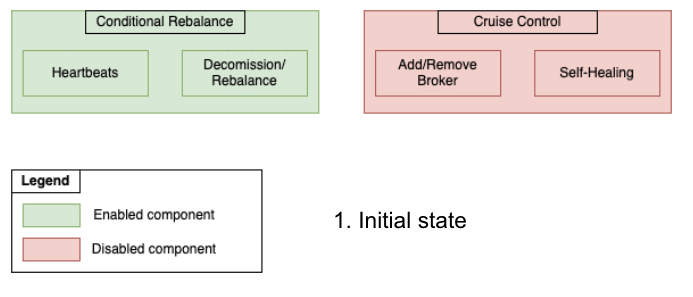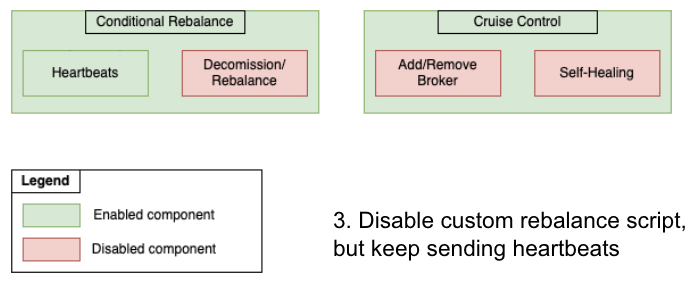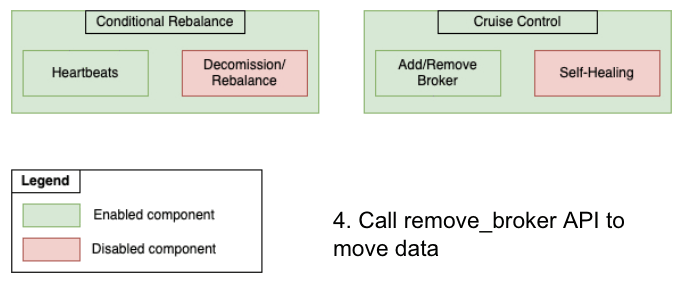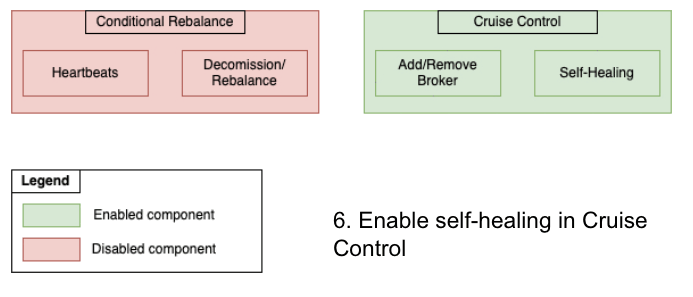
Migrating from Conditional Rebalance Script to Cruise Control
Rather than manually issue broker removal requests, we built a rudimentary migration helper service to check the cluster state, repeatedly issue requests to the Cruise Control REST API, and remove EC2 brokers one by one. After Cruise Control finished moving all partition data away from the EC2 brokers and onto the PaaSTA brokers, we were ready to terminate the EC2 brokers. This was accomplished by shrinking the size of the ASG from N to 0 and by removing references to the old EC2 ELBs in our configuration files. Since we use Terraform to manage AWS resources, the rollback procedure was as simple as a git revert to recreate the resources. After the EC2 brokers had been decommissioned, we removed the instance of our decommission helper service and enabled self-healing in the cluster’s Cruise Control instance. This was now safe to do since the cluster was composed entirely of PaaSTA-based brokers. At this point the cluster migration was complete, and the remaining work entailed cleaning up any miscellaneous AWS resources (autoscaling SQS queues, ASGs, ELBs, etc.) after deeming it safe to do so.
Risks, Rollbacks, and Darklaunches
While we strove to optimize safety over migration speed, there were naturally still some risks and drawbacks associated with our approach. One consideration was the temporary cost increase due to doubling the size of each cluster. The alternative to this was to iteratively add one PaaSTA broker, perform data migration away from one EC2 broker, decommission one EC2 broker, and repeat. Since this approach confines the data movement to one broker’s replica set at a time, this approach would have extended the total duration of the migration procedure. Ultimately we decided that we favored migration speed, so the up-front cost of having twice as many brokers was a cost that we were willing to pay. Additionally, we estimated that the benefits associated with having the cluster on PaaSTA would outweigh these initial costs in the long run. Another tradeoff was that doubling the size of the cluster would also result in very large cluster sizes for some of our high traffic clusters. Those clusters required additional attention during the migration process, and this engineering time-cost was also an initial investment that we were willing to make for the sake of shorter migrations.
In case of a catastrophic issue during the migration, we also needed to devise a rollback procedure. Sequentially reversing the order of the migration procedure at any stage was sufficient to roll back the changes (this time using Cruise Control’s add_broker API rather than the remove_broker API after removing any pending reassignment plans). The primary risk associated with this is that both the migration and the rollback procedure are heavily reliant on Cruise Control being in a healthy state. To mitigate this risk we assessed the resource requirements of these instances on test clusters and then overprovisioned the hardware resources for the non-test Cruise Control instances. We also ensured that there was adequate monitoring and alerting on the health of these instances. Finally, we provisioned backup instances which would serve as a replacement if the primary instance became unhealthy.
While the plan seemed sound in theory, we needed to test it on real clusters and thoroughly document any anomalies. To do this we first used Kafka MirrorMaker to clone an existing cluster and then performed a darklaunch migration in its entirety in a non-production environment before repeating the darklaunch migration in a production environment. Once we had established sufficient confidence and documentation, we performed real migrations of all of our Kafka clusters in development and staging environments before performing any production migrations.
Challenges and Learnings
As previously alluded to, the major risk with the plan was that Cruise Control needed to be healthy in order to proceed with a migration or rollback. We did encounter some instability in some of our non-prod migrations wherein a Cruise Control instance became unhealthy due to offline partitions in a Kafka cluster which temporarily experienced broker instability. Since Cruise Control’s algorithms and internal cluster model rely on being able to read from (and write to) a set of metrics topics, communication between Cruise Control and each Kafka cluster must be maintained. Offline partitions can thus prevent Cruise Control from operating properly, so in those cases the priority is to first triage and fix the issue in Kafka. Additionally, Cruise Control exposes configuration values for tuning various aspects of its internal metrics algorithm, and we found that it was sometimes helpful to reduce the lookback window and number of required data points. Doing so helped Cruise Control regenerate its internal model more quickly in cases where Kafka brokers encountered offline partitions.
Since we were migrating individual clusters, beginning with clusters in our development environment, we were able to gain insights into the performance characteristics of a Kafka cluster when it was running on PaaSTA/Kubernetes compared to when it was running on EC2. Much like with our instance selection criteria when running on bare EC2 instances, we were able to set up Kafka pools with differing instance types according to resource requirements (e.g. a standard pool and a large pool, each containing different instance types).
Another approach we initially considered for our migration procedure was to set up a fresh PaaSTA-based cluster with N brokers and then use Kafka MirrorMaker to “clone” an existing EC2 cluster’s data onto that new cluster. We also considered adjusting the strategy such that we would add one PaaSTA broker, remove one EC2 broker, and repeat N times. However, this would have entailed updating our operator’s reconcile logic for the purpose of the migration, and we would have needed to manually ensure that each broker pair was in the same availability zone. It would have also introduced a lengthy data copying step which we did not feel was acceptable for large clusters. After some further testing of procedures in our development environment, we ultimately settled on the procedure described here.
Acknowledgements
Many thanks to Mohammad Haseeb, Brian Sang, and Flavien Raynaud for contributing to the design and implementation of this work. I would also like to thank Blake Larkin, Catlyn Kong, Eric Hernandez, Landon Sterk, Mohammad Haseeb, Riya Charaya, and Ryan Irwin for their valuable comments and suggestions. Finally, this work would not have been realized without the help of everyone who performed cluster migrations, so I am grateful to Mohammad Haseeb, Jamie Hewland, Zhaoyang Huang, Georgios Kousouris, Halil Cetiner, Oliver Bennett, Amr Ibrahim, and Alina Radu for all of their contributions.
Principal Platform Software Engineer (Data Streams) at Yelp
Want to build next-generation streaming data infrastructure?
View Job