A Simply, Ordinary Reduction

-
Edmond Mui, Applied Scientist
- Jun 27, 2022
Experimentation has become standard practice for companies, and one of the most important aspects is how to evaluate the results to make ship/no-ship decisions. Have you run into experiments where you don’t have enough data for statistically significant results or perhaps the performance of your primary metric seemingly disagrees with that of your secondary metrics? If so, leveraging existing features to perform variance reduction may help with coming to a conclusion. At Yelp, we have found that using features typically used in ML modeling, in particular, can help with measuring treatment effects better than solely using t-tests!
Introduction
Before deciding to fully launch a new feature, you will typically want to have some confidence that the feature will actually lead to some form of a win (e.g. engagement, revenue, etc.). To test the feature change, one of the most common ways is to use an A/B experiment. At its simplest level, start by randomly assigning half of your users to see the new feature and the other half to not. Once the experiment has run for a sufficiently long amount of time, the experiment is done and you can compare the results.
For this comparison of the control and treatment cohorts, standard practice is to use a t-test to determine if the two cohorts have statistically significant differences. First, you need to choose some metric to represent the performance of each cohort. Once you have calculated the metric for each user in control and treatment cohort, the treatment lift can simply be the average of treatment metrics minus the average of control metrics. To determine if that lift is statistically significant, use a t-test to compare the two sets of metrics for control and treatment cohorts.
While this all sounds great in practice, one of the key downsides of only using a t-test is that when there is a significant amount of unexplained variation in the comparison metric, you may have to run the experiment longer than you would like to reach a statistically significant difference. This is where variance reduction techniques come into play. To start this blog post, let’s actually go through a demo of how we would use an Ordinary Least Square regression to help in our experiment analysis! Ordinary Least Square regression is reminiscent of a certain popular TikTok video that will serve as a great guide as we learn more about how it works.
A Fresh Pie!
For our demo, let’s use Yelp, a company you are hopefully very familiar with. One way Yelp helps connect users to local businesses is through ads on various parts of the Yelp website/app. Let’s say we identify a specific segment of advertisers who could really benefit from spending slightly more in their advertising budget with Yelp by using a new feature on the Yelp dashboard. We believe if a business owner sees this on their Yelp dashboard, they will be more likely to increase their advertising budget with Yelp.
As a side note, in practice, we are actually working on product features that help advertisers to make the best spending recommendations (see the Budget Design and Infrastructure Updates section of this blog post) for every local business here at Yelp!
Now back to the demo! We can set up this in Python with the following code snippet:
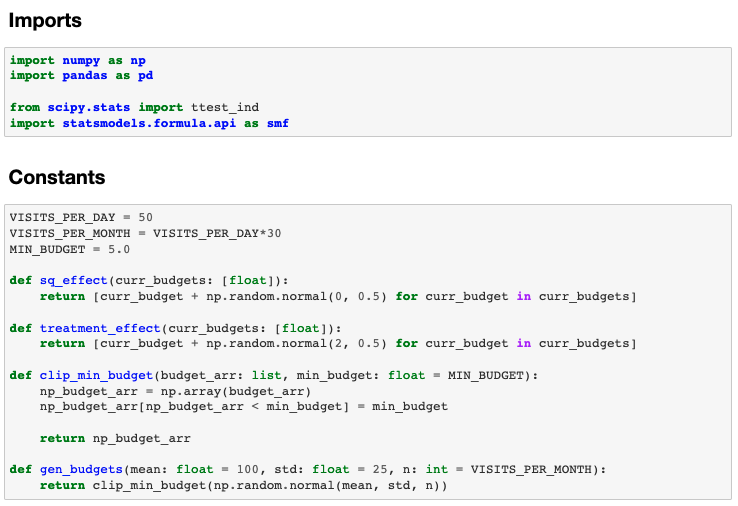
In this code snippet, we have 50 new Yelp advertisers that visit the Yelp dashboard per day and we run this experiment for a month. Let’s assume that the current budget of each Yelp advertiser is normally distributed and a minimum value of $5 since budget cannot be negative. We also assume that the proposed treatment, on average, results in a $2 increase in the business owner’s advertising budget, which we assume to be normally distributed and independent of the business’s existing advertising budget.
Thus, the metric we would want to compare is what the post-treatment advertising budgets are between control and treatment cohorts to see if there is a statistically significant difference. Here is how we would do this with a t-test:
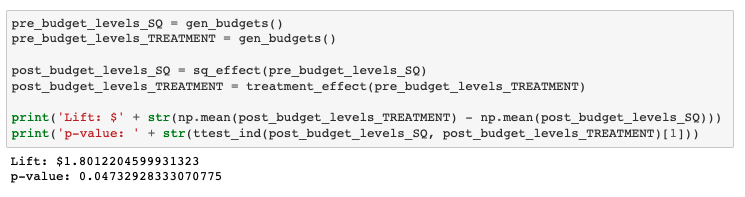
What we observe is that, on average, post-treatment advertising budgets are ~$1.80 higher in the treatment cohort than in the control cohort (well within the variation we set for the expected $2 budget increase). More importantly, we see from the t-test that the p-value between resulting advertising budgets between the two cohorts is 0.0473, which means this difference is indeed statistically significant. Perfect, we are now more confident that our treatment has the desired effect on increasing advertisers’ budgets!
Save Me a Slice!
Now I know what you’re thinking. That was quite a lot of assumptions we made to simplify our A/B experiment, so let’s complicate things quite a bit. Different advertisers at Yelp have different budgeting needs. Let’s incorporate this difference into our code and try running the same t-test.
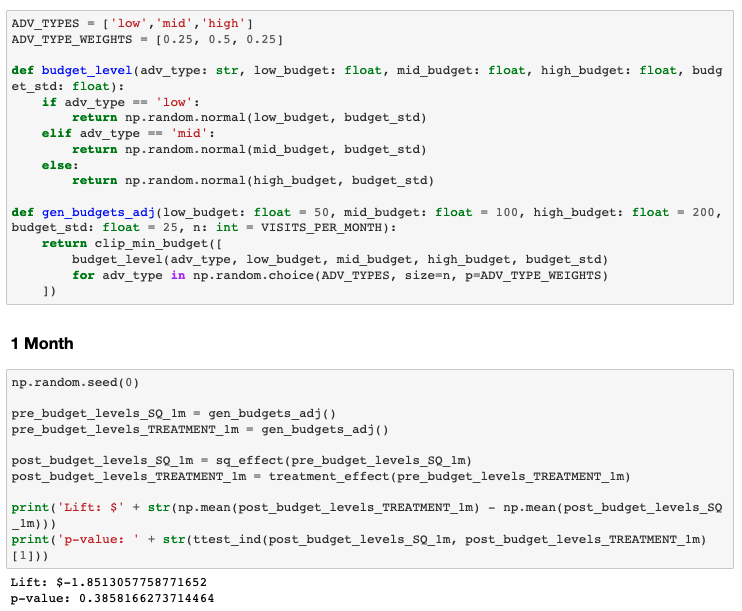
This defines three possible types of advertiser budgets: low, mid, and high, each with a different distribution of advertising budgets that make up 25%, 50%, and 25% of Yelp’s advertisers respectively.
From the results of the t-test, we can see that the difference between advertising budgets of treatment and control cohorts is negative and more importantly, we do not observe a statistically significant difference. The problem here with running a t-test is that the added variance from the three different types of advertiser budgets is attributed as noise, but in reality, it can be explained.
As an exercise, let’s see what would happen if we ran the experiment longer to reduce this “noise.” If we were to run this experiment for 3 months, we would actually still see the same results and it is not until the 4th month that we see a statistically significant lift in advertising budget in the treatment cohort.
We probably don’t want to be running an experiment for 4 months for a variety of reasons (e.g. this subset of advertisers might not even benefit from the increased advertising budget after that long). Let’s see if we can come to a different conclusion using an Ordinary Least Square (OLS) regression where we define the dependent variable as post-treatment advertising budget. We can define it as the following:

As an example, if we only choose cohort as the only feature, which is equivalent to having an empty X, we will actually get the same results as our t-test.
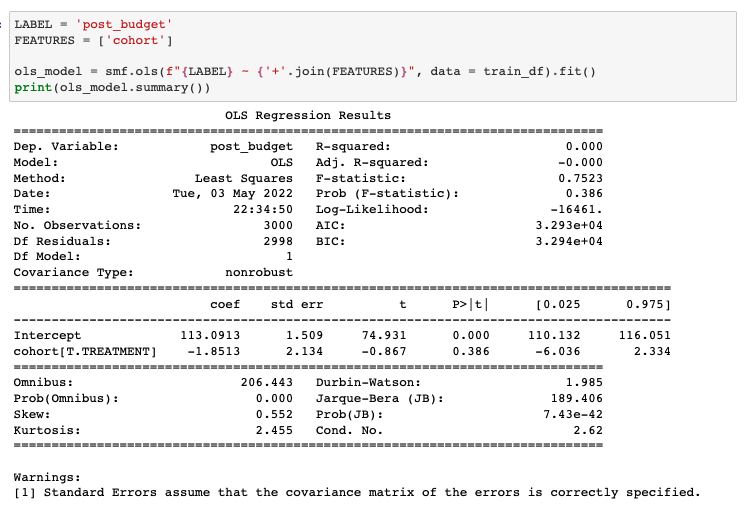
We can ignore most of the numbers in the summary of our OLS regression and focus on the coef and P>|t| values for our treatment indicator feature (cohort[T.Treatment]). This treatment indicator feature is simply 1 if the advertiser belonged to the treatment cohort and 0 otherwise. One thing to note is that there is no feature for the Status Quo cohort since our OLS regression has selected it to be the reference group for the cohort feature. We can manually select the reference group as an input to the OLS regression if necessary, but if not, it will be random.
The coefficient of this feature, coef, represents the average effect that being in the treatment group has on the advertiser’s post-treatment budget. Thus, like the t-test, we are seeing that the treatment leads to $1.85 lower post-treatment advertising budget. P>|t| represents the statistical significance of this feature’s coefficient, which for this OLS regression has the same p-value we calculated in our t-test. Again, in this example, we see that the coefficient is not statistically significant with a value of 0.386.
Rather than just use cohort as a feature, however, let’s see what happens when we add pre-treatment advertising budgets as part of X. Since cohort assignments are randomly picked, there should be no violation of independence between the treatment label and adding this second feature.

What we observe now is that the coefficients of both features in our OLS are significant. The values themselves are also informative! The coefficient for the treatment cohort matches our expectations of a $2 increase in advertising budget and the coefficient for pre-treatment advertising budget is 1. Thus, our model essentially believes that the post-treatment budget can be represented by the pre-treatment budget plus $2 if the advertiser was in the treatment cohort.
To truly understand how much time using an OLS regression with informative predictors can save in an experiment, we can create an A/A test and run a power analysis. For the A/A test, we will run the same two OLS regressions as above, but set the treatment_effect equal to the sq_effect. Once we have these two regressions, we can calculate an estimate of the population standard deviation of our treatment indicator feature from the std err output and use that in our power analysis.
Let’s assume a relatively standard alpha of 0.05 and beta of 0.2. If we wanted to detect a minimum effect size of $0.10 without pre-treatment budget as a feature, we would need over 10,000,000 samples. Note, this is equivalent to our initial methodology of just running a t-test.

Instead, if we add pre-treatment budgets as a feature to detect the same minimum effect size, we’ll need 800 samples. This illustrates the immense impact that informative predictors can have on making the correct ship/no-ship decision with significantly shortened experiment lengths.

That’s Enough Slices!
If you’re still not convinced that using an OLS regression is necessary, I would absolutely agree. In the previous example, we could have run a t-test to look at the differences between post and pre-treatment budgets as our primary metric.

Let’s make things even more complicated then! Our other assumption was that the treatment would have the same effect on all advertisers, which is very rarely the case in practice. Let’s replicate this behavior in our demo by varying the treatment effect for the category that the advertiser is a part of. For example, let’s say that restaurant, plumber, electrician categories make up 25%, 25%, and 50% of all Yelp advertisers. Although not true in practice, let’s also assume that the category of advertiser and their advertising budget are independent of one another.


Let’s now run the same OLS and add category as a feature since we know that the treatment effect is dependent on what category the business is a part of.
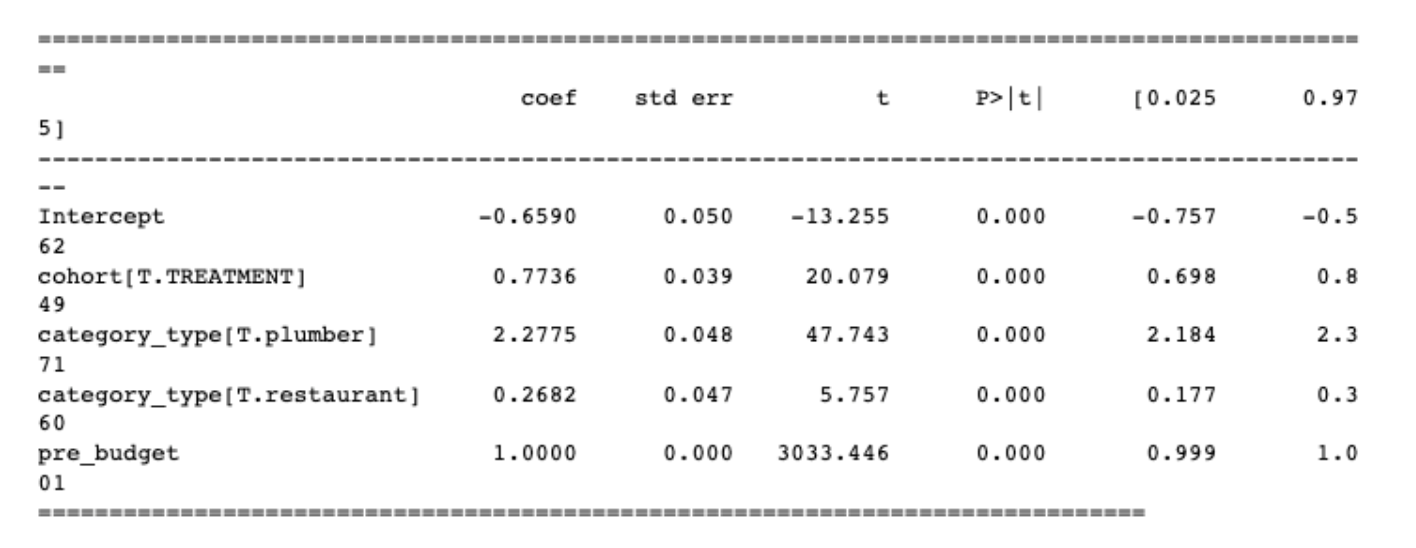
As before, our reference group for category_type is the electrician value so we do not see an indicator feature for that specific category of advertiser.
Unfortunately, the results aren’t exactly what we would have expected. For example, if a business owner is an electrician, our model would be predicting that the treatment would increase their advertising budget by ~$0.75, whereas, in reality, it should have decreased budget by $0.50. This $0.75 represents the average treatment effect on advertising budget since over all advertisers, 50% (electricians) will see a budget decrease of $0.50, 25% (plumbing) will see a budget increase of $4, and 25% (restaurants) will see no treatment (-$0.50*50% + $4*25% + $0*25% = $0.75). Sometimes this is actually all you need, especially in the case that you just want to understand what will happen if Yelp decides to treat a randomly selected advertiser.
Say we want to dive deeper and understand the treatment effect for each category. The problem with our current OLS model is that we are unable to capture the interaction effect between categories and what the conditional treatment effect will be. To remedy this, let’s leverage interaction variables in our OLS by multiplying the treatment label with each categorical feature in the following manner:

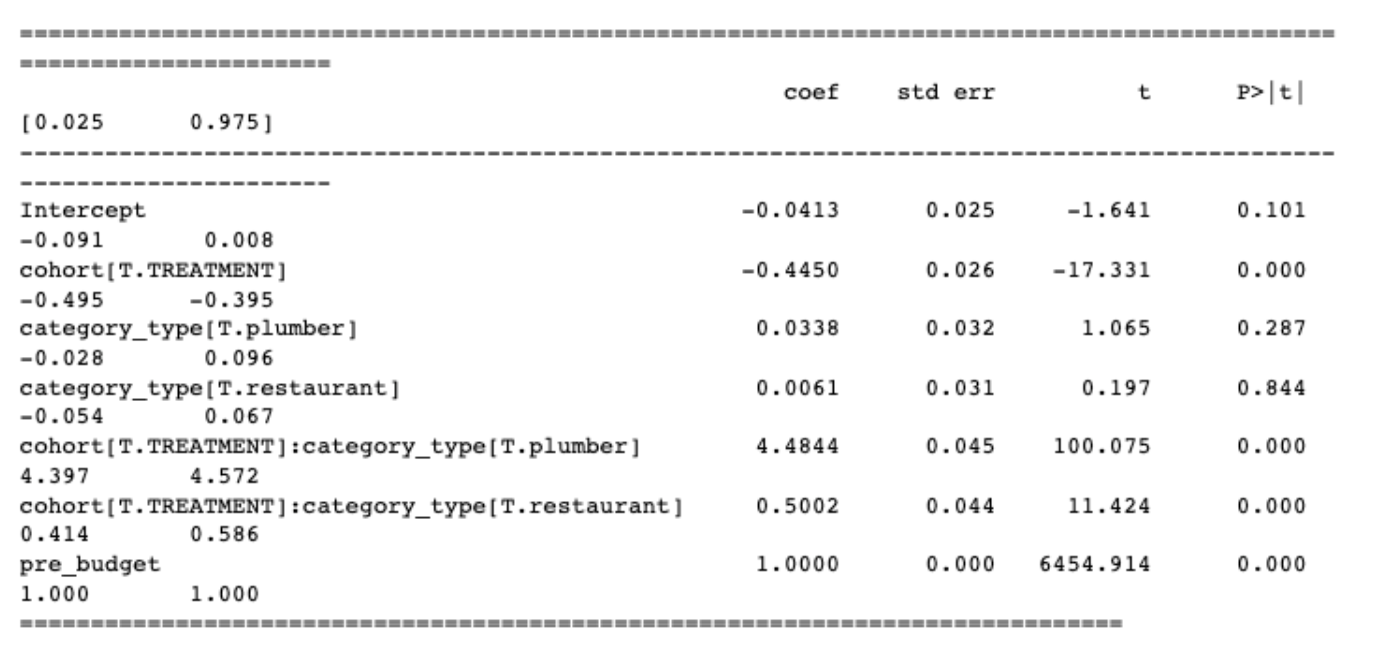
Now we can see the OLS regression has two additional interaction features. For example, cohort[T.TREATMENT]:category_type[T.plumber] will be 1 if an advertiser is a plumber and in the treatment group and 0 otherwise. Essentially, this feature, combined with our treatment indicator feature, will give us the average treatment effect on advertising budget for plumbers. It is also worth noting that category_type features alone are not statistically significant, which makes sense since category alone should not affect a business’s advertising budget in our example.
This is something that is both more interpretable and consistent with the data we generated in our demonstration. For each category of advertiser, we can see that:
electrician: There is no interaction term because this is our reference group forcategory_type. Thus, the treatment effect is simply the coefficient of the treatment label, -0.4450. Thus, the advertising budget is roughly $0.50 less, as expected.plumber: The coefficient of the interaction term is 4.4844, so if we subtract the coefficient of the treatment label, the advertising budget is roughly $4 more, also as expected.restaurant: The coefficient of the interaction term is 0.5002, so if we subtract the coefficient of the treatment label, the advertising budget is neutral, also as expected.- Also, note that the coefficients for all the features mentioned in this section are statistically significant.
Thus, we have been able to show that using an OLS for variance reduction can significantly help with two parts of experiment analysis: decreasing the amount of time we need to run the experiment as well as giving insight into the varying effects that the proposed treatment will have on different populations in the experiment.
Requirements for OLS
Now that we have gone through a demonstration of how an OLS regression may help with experiment analysis, let’s talk about some of the caveats of performing this type of analysis.
- The first is fairly straightforward; using an OLS regression is a conditional expectation and will give the average effect of a feature if we do not include any interaction terms.
- In practice, the treatment effect will likely not be uniform across all subjects. For example, if our treatment has a larger effect on businesses with more reviews on Yelp, an OLS regression without interaction terms would not be able to distinguish the treatment effect difference between two identical businesses with 0 and 10 reviews than two identical businesses with 1000 and 1010 reviews.
- Despite this, starting with an OLS regression can still help with identifying predictive features and can sometimes be all you may want or need in your experiment analysis.
- The second caveat is that the selection of businesses for treatment must be independent of other features used in the OLS regression.
- When running a randomized experiment, this criteria will usually be met as whether or not a business receives the treatment is random.
- Variance reduction will only be noticeable when the features are highly predictive of the dependent variable.
- The theory behind variance reduction is that we want to attribute what a t-test would consider unexplainable noise to be explained by other features. If these features are unable to explain much, we would not be significantly reducing variance and be no better off than running a t-test for analyzing the experiment.
- Be careful with regularization!
- Adding a regularization term in your OLS regression can give you a biased read on coefficients because the coefficient will likely be smaller than their original, unbiased values.
Arguably, the most important requirement when we perform variance reduction is that the features we use must be pre-treatment values. If we do use post-treatment features, there are two scenarios possible:
- The treatment has no effect on the post-treatment feature.
- If the post-treatment feature has no effect on what we are trying to predict, we actually don’t accomplish anything by including the post-treatment feature. In fact, if we add too many useless features, we may incorrectly inflate the standard error of the treatment indicator due to a decrease in degrees of freedom from the extra features.
- If the post-treatment feature does have an effect on what we are trying to predict, our coefficient for the treatment indicator feature will remain the same, but the statistical significance of that feature may change. Since we are reducing the amount of total variance in the predictor with a post-treatment feature, the standard error of the treatment indicator feature will decrease.
- Ultimately, if we are absolutely sure that the treatment will have no influence on some feature, it should be safe to add the post-treatment feature, but in practice, it is hard to make and prove such a statement.
- The treatment does have an effect on the post-treatment feature.
- First, this violates one of our previous requirements since the treatment indicator is no longer independent of all other features.
- Let’s also take an example from literature to illustrate the problems with doing this in more detail. Let’s suppose our treatment is a Yelp advertising tutorial and we are trying to measure the effect the tutorial has on businesses purchasing advertisements. Our post-treatment feature will be a sentiment score for each business towards Yelp and for this scenario, assume that the Yelp advertising tutorial does lead to higher sentiment scores. This example is adapted from Montgomery et al:
Scenario 1: Sentiment scores have a relationship with purchasing ads (let’s assume a positive one). If this is the case and we include it as a feature, the higher ads purchase rate will be attributed to higher sentiment scores rather than the treatment, causing the coefficient of the treatment indicator of the OLS model to be biased. Simply removing the feature will correctly attribute the higher levels of ads purchases to the treatment label feature.
Scenario 2: Sentiment score does not have any effect on purchasing ads. While this may seem harmless to include post-treatment sentiment scores as a feature, it actually is not. Let’s say there is a confounding feature such as business age, where older businesses tend to have higher rates of purchasing Yelp ads and sentiment scores towards Yelp.
- What will happen now is for businesses with higher sentiment scores, there can be two scenarios: they belong to an older business age demographic or they received treatment. All else being equal, businesses that are older will have higher purchase rates than those who received treatment. This will cause our OLS model to falsely associate the treatment with negatively impacting ads purchase rates when we hold the post-treatment feature of sentiment scores equal.
- Note, if we include business age as a feature in the OLS, this would no longer be an issue. However, because we cannot determine all such unknown variables, we will always face the possibility of having a biased coefficient for our treatment indicator feature if we decide to include post-treatment features.
We also want to note that having stale features may be problematic as well. Stale features may lead to having features that are too old to be informative predictors for our dependent variable, which will in term decrease the effect of variance reduction in our experiment analysis (see Caveat 3 above).
This highlights the importance of having time travelable features or more specifically, having an ETL with the ability to generate event-based features. There exists numerous sources (e.g. from Netflix) of online content discussing the benefits of time travelability and feature logging, but those primarily focus on how this infrastructure benefits robust training processes for machine learning (ML) models. Time travelability allows ML practitioners to generate features at prediction time since features generated any further would result in label leakage.
What these articles don’t cover and what we have done at Yelp is leverage the same ETL to generate pre-treatment feature sets since we know exactly when treatment occurs for our population (essentially replace prediction time with treatment time in the ETL). This allows a proper setup of pre-treatment features if we decide to use an OLS regression in an experiment analysis.
Conclusion
TLDR: Using an OLS regression may be superior to a t-test in interpreting experiment results!
- The simplest form of an OLS regression is equivalent to a t-test, where the only feature is the treatment indicator label.
- The more variance introduced into an experiment, which happens naturally in the real world, the more likely it will be the case that a t-test will not be sufficient.
- With an OLS regression, we can also leverage interaction terms if there is reason to believe that treatment will affect separate populations differently.
- Of all the criteria of using an OLS regression, we would like to emphasize the importance of not using post-treatment features as this can significantly distort the interpretations of treatment effects.
- Overall, an OLS regression can more accurately capture treatment effects on specific segments of your population and in a significantly less amount of experiment run time when we have highly predictive pre-treatment features.
As a side note, we would also like to call out that this is not the first time this technique has been used for experiment analysis. Please see a prior Blog Post by Alexander Levin about how we can use the same technique to account for mixshift changes over the course of an experiment.
Acknowledgments
- Shichao Ma for the idea to try this when analyzing an experiment we designed and ran
- Yang Song for reviewing and adding helpful comments
Become an Applied Scientist at Yelp!
Are you intrigued by data? Uncover insights and carry out ideas through statistical and predictive models.
View Job