Data Sanitization with Vitess

-
Matt Ullmer, Database Reliability Engineer
- Jun 22, 2022
Our community of users will always come first, which is why Yelp takes significant measures to protect sensitive user information. In this spirit, the Database Reliability Engineering team implemented a data sanitization process long ago to prevent any sensitive information from leaving the production environment. The data sanitization process still enables developers to test new features and asynchronous jobs against a complete, real time dataset without complicated data imports. MySQL and other open source project innovations over the last decade have led us on a journey to Vitess, which is now responsible for over 1500 workflows across more than 100 database schemas that serves the sanitized data needs of all of our developers at the click of a button.
Vitess Concepts
The following are excerpts or paraphrases from the vitess.io site and will be helpful to know when seeing these terms used later on:
- Vitess is a database clustering system for horizontal scaling of MySQL
- VReplication is a system where a subscriber can indirectly receive events from the binary logs of one or more MySQL instance shards, and then apply it to a target instance
- vt-tablet processes connect to a MySQL database, local or remote
- vtctld is an HTTP server useful for troubleshooting or getting a high-level overview of the state of Vitess
Why did Yelp choose Vitess
Yelp began exploration of Vitess in late 2019 when a need was growing for new capabilities within our MySQL infrastructure. Data sanitization was the most pressing need at the time, and the newly developed VReplication features would help improve the reliability and scalability of our existing sanitization system. The potential of using Vitess to also serve as a data migration tool, and multi-version replication medium in the future also helped lead us to choosing Vitess.
Basics of our MySQL Setup
MySQL is the primary datastore for all transactional workloads at Yelp. The production environment contains more than 20 distinct replication clusters across cloud datacenters in multiple regions of the United States. Nearly every action a user takes on Yelp will be handled on the backend by MySQL. Our largest three MySQL clusters are responsible for serving over 300,000 queries per second covering data measuring in the tens of terabytes, not even counting the queries satisfied by the caching in front of them.
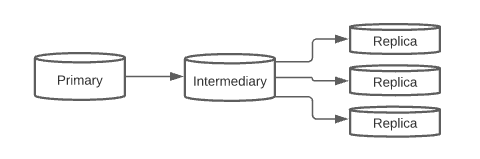
Each MySQL cluster is organized with a single source of row-based replication, depicted in the diagram below as “Primary”. Replication then continues on to an intermediary, which serves as the replication source to all leaves below it. Our leaves can have different roles, and may be consumer facing or internal-facing. The role of “Replica” is one that is restricted to the leaf level, and serves as the data sanitization source to our development environment.
Legacy Data Sanitization
The ability to query data, test batches, and run developer playgrounds outside of the production environment against sanitized data was first provided using trigger-based standard MySQL 5.5.x Replication (statement-based replication).
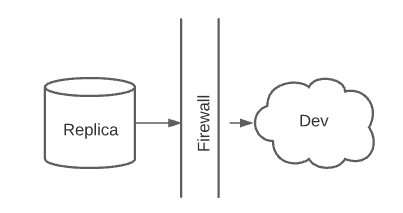
Statement-based sanitization was inherently flawed, but usable as a rough approximation of production for many years. When rows are written, triggers present on the sanitized database replica match a pattern for things such as addresses, emails, or names and are obfuscated in a variety of ways.
Trigger-based sanitization came in various forms, the simplest of which was to clear the column, and then clear the column continuously going forward:
UPDATE user SET last_name = '' ;
DROP TRIGGER IF EXISTS user_insert ;
DELIMITER ;;
CREATE TRIGGER user_insert BEFORE INSERT ON user FOR EACH ROW BEGIN SET NEW.last_name = '' ; END ;;
DELIMITER ;
DROP TRIGGER IF EXISTS user_update ;
DELIMITER ;;
CREATE TRIGGER user_update BEFORE UPDATE ON user FOR EACH ROW BEGIN SET NEW.last_name = '' ; END ;;
DELIMITER ;Flaws in the Trigger-based System
Among the trigger-based system’s worst flaws was that data correctness, even of the unsanitized columns, within this system was never really possible. Once data is obfuscated it cannot always be updated or deleted through statement-based replication in the future.
CREATE TABLE user (
id int NOT NULL AUTO_INCREMENT,
first_name varchar(32) COLLATE utf8_unicode_ci DEFAULT NULL,
last_name varchar(32) COLLATE utf8_unicode_ci DEFAULT NULL,
PRIMARY KEY (id),
KEY last_name_idx (last_name),
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ciTo illustrate, take this simple example, with the user_insert trigger in place and the simplified table structure above:
INSERT INTO user (first_name,last_name) VALUES ('john','smith');
TRIGGER ACTION: BEFORE INSERT ON user FOR EACH ROW BEGIN SET NEW.last_name = '' ;
UPDATE user SET first_name = 'james' WHERE first_name = 'john' and last_name = 'smith';
No Rows AffectedThe result of the trigger sanitization is that the statement no longer matches as it would on an unsanitized host, effectively leaving rows impossible to reference in this manner.
Multiple terabytes of data had to be intermittently rebuilt from scratch due to infrastructure failures, migrations to the cloud, functionally sharding the source cluster, and version upgrades. When executing this process for copying, then sanitizing, and applying triggers, the engineering time required rose dramatically from hours, to days, and towards the end of life of this implementation, a full week. To alleviate manual interventions, backups were enabled to reduce the need to rebuild these hosts from scratch. Testing was implemented to ensure they worked, but even so they were becoming increasingly unwieldy as they were less and less capable of using our standard tooling. Innovations in MySQL enabled by upgrading to newer versions eventually led to the failure of the trigger system in standard MySQL, as triggers do not execute on the replicas in row-based replication (RBR).
MariaDB Workaround for Trigger-based System
Having overlooked the inability of triggers from executing on replicas, we quickly pivoted to find an alternative upon implementation of RBR across our fleet. MariaDB proved to be a serviceable option, providing the ability to execute triggers on row-based events.
The downside to running with MariaDB, which we did for just over a year, was the necessity of maintaining two versions of every tool. While largely compatible with MySQL, the MariaDB tools subtly renamed a lot of the commands, implemented backups a little bit differently, and required maintaining two versions of packages.
Vitess Setup
Our Vitess deployment consists of more than 2000 vt-tablets deployed across dozens of machines residing in our dev, staging, and production environments. These vt-tablets are responsible for VReplication of over 6000 distinct workflows that materialize data from one database instance to another that share no traditional MySQL replication. Several hundred of these vt-tablets are responsible for over 1500 workflows involved in the data sanitization process.
Much of our core setup is off the shelf, and the best resource for deploying Vitess can be found here. The implementation we went with for our initial deployment of Vitess was couched in the knowledge that we had no consumer-facing use cases, little local knowledge of Vitess, and a likely need to implement and materialize data in the future. Knowing that, and that no sharding was needed for this use-case, we created a slimmed-down deployment to only include vtctld and vt-tablet containers.
Our tablets all connect to external MySQL databases, and were deployed on dedicated servers for vt-tablets and vtctlds. The tablets were launched in pairs, with a source tablet and a target tablet for each MySQL schema living on the same physical machine to minimize network transit. Tablet state is stored in Zookeeper, and actual tablet deployments are coordinated with a scheduled job and static configuration file managed by humans based on resource consumption of different tablets.
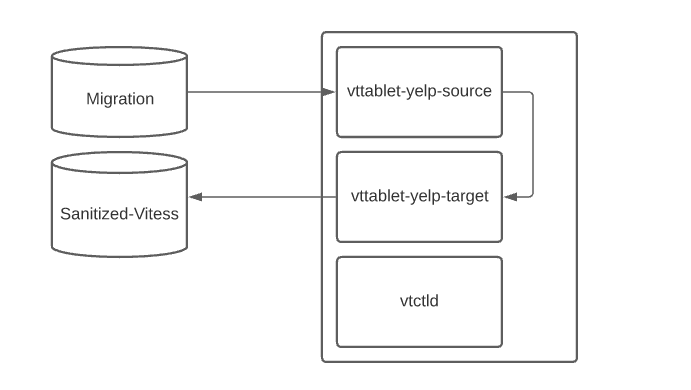
Data flow through tablets
Another role of MySQL hosts was created for each physical MySQL cluster Vitess would materialize data from, which we denoted as ‘migration’ hosts explicitly to serve the needs of Vitess VReplication. Like the ‘replica’ role, this role is exclusive to the leaf level of the replication hierarchy. The migration role is advertised via Envoy/Smartstack, the discovery system used at Yelp, and discovered by the appropriate vt-tablets. With its own role, in this case the target (writable host) and the sanitized server are discovered the same way by the vt-tablets and is a full-fledged replication hierarchy with automatic failover targets available to maintain up-time and ease maintenance.
| Ecosystem | Non-Prod | Prod |
|---|---|---|
| Zookeeper | m5d.xlarge | m5d.xlarge |
| Tablet Hosts | c6i.4xlarge | c6i.12xlarge |
Vitess Materialization Logic
The logic for data sanitization was previously captured as what to change a column value to after it was already seen in replication, and was not directly compatible with Vitess. Another way of thinking about this, is that the unsanitized data was actually replicated to the sanitized server in the relay log, and then on write was modified based on the trigger rules. With materialization rules, the sanitized data is never replicated to the sanitized server, and is instead retrieved directly from the source in a modified, or custom, fashion. In the process of creating this setup, we iterated over every table and created a purpose built rule for sanitizing (or not) the data for use by our developers. All of our workflows are stored in a simple git repository for later re-use, such as for re-materialization or schema changes necessitating modification of the custom rules.
Example of a simple custom materialization rule:
{
"workflow": "user_notes_mview",
"sourceKeyspace": "yelp_source",
"targetKeyspace": "yelp_target",
"stop_after_copy": false,
"tableSettings": [
{
"targetTable": "user_notes",
"sourceExpression": "SELECT id, user_id, 'REDACTED' AS note, note_type, time_created FROM user_notes",
"create_ddl": "copy"
}
]
}Example of a normal materialization rule:
{
"workflow": "user_mview",
"sourceKeyspace": "yelp_source",
"targetKeyspace": "yelp_target",
"stop_after_copy": false,
"tableSettings": [
{
"targetTable": "user",
"sourceExpression": "SELECT * FROM user",
"create_ddl": "copy"
}
]
}There are over 1500 materialization rules in place to vreplicate some or all of the tables from over 100 database schemas into one monolithic database from multiple physical source clusters. At any given time there is near real-time VReplication happening between the originating write and the downstream sanitized write for each of the workflows. Co-locating all of the sanitized data was a conscious choice, and provides a single target for playgrounds our developers run to connect to, eases management, and in the case of data corruption is simple to re-seed.
Vitess Performance Considerations
We learned early on that workflows are not created equal, and that the more workflows that run on a schema the higher resources that are used by the source and target tablets to manage the binary logs and data streaming. As a result of these heavy weight tablets we had to scale up our instances, and further coordinate which tablets run on which hosts in order to spread the load as evenly as possible. The actual load wasn’t the only limiting factor either, as running too many containers on a single server can become unstable and will result in dockerd issues eventually. In the final deployment, we are running over 250 tablets and attempt to keep the number of tablets per node to no more than 50 to limit the dockerd issues we encounter. These tablets are always paired, source and target, as seen below.
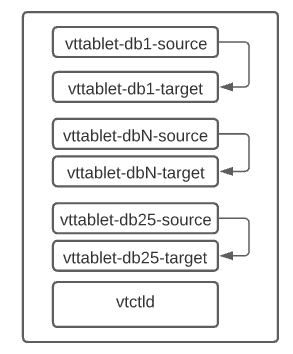
For deployments like this, it’s important to understand the impact large numbers of workflows will have on recovery in the event of failure. When enabling workflows you could also encounter throughput issues that are easier to intuit because the data is being actively copied by Vitess. Doing these materializations in chunks is an obvious optimization, and largely fixes the issues encountered during the course of standing up a sanitized database as we have done. If instead, though, you have an existing system that fails (host that a tablet runs on dies, target writable host dies, service mesh goes down, etc) recovering is not trivial.
Workflows per database
This chart shows the relative number of Vitess workflows per database schema. The bigger the slice, the more workflows.
We have more than 100 database schemas, and many have few workflows as visualized in the above chart. Upon failure, these smaller sets of workflows are able to rapidly re-read binary logs and pick up where the local state indicates they should in quick order. There are also three schemas with upwards of 100 tables, one has nearly 600, and these workflows each must re-establish their positions independently from each other (our workflows are all created 1:1 to tables). On occasions when there is a failure with hundreds of workflows involved on one tablet, we found that stopping and starting them in a staggered way (25 per 3 minutes for example) can help the system recover to working order where it may have never recovered otherwise.
Vitess to the Future
With Vitess, Yelp was able to eliminate mountains of technical debt, bring in a tool with boundless potential, and improve the security and speed of our Sanitization process. Our old system was no longer scaling, and we started to have lengthy manual maintenance cycles whenever a problem came up. Problems with Vitess are easy to fix, and best of all can be automated in most situations.
We have plans in motion for using k8s paasta instead of managing the infrastructure directly. Using the standard k8s operator and a more broadly understood deployment will help as we begin to utilize more Vitess components.
Other projects include one dubbed internally “Dependency Isolation”, where an existing binlog based data-pipeline system is being moved away from the source clusters to one driven by Vitess. This allows us to decouple our consumer-facing cluster upgrades from the data pipeline databases, and to perform the upgrades consciously and independently. A third project in flight is designed to harness the ability to materialize read-only view tables into different database schemas, a common enough use of Vitess. Providing local read-only views of tables can allow for faster development cycles, and easier extraction of data from our monolith.
Become a Database Reliability Engineer at Yelp
Do you want to be a Database Reliability Engineer that builds and manages scaleable, self-healing, globally distributed systems?
View Job