Spark Data Lineage

-
Tien Nam Le, Software Engineer; Swathi Vodela, Data Platform Engineer
- Aug 4, 2022
In this blog post, we introduce Spark-Lineage, an in-house product to track and visualize how data at Yelp is processed, stored, and transferred among our services.
What is Spark-Lineage?
Spark and Spark-ETL: At Yelp, Spark is considered a first-class citizen, handling batch jobs in all corners, from crunching reviews to identify similar restaurants in the same area, to performing reporting analytics about optimizing local business search. Spark-ETL is our inhouse wrapper around Spark, providing high-level APIs to run Spark batch jobs and abstracting away the complexity of Spark. Spark-ETL is used extensively at Yelp, helping save time that our engineers would otherwise need for writing, debugging, and maintaining Spark jobs.
Problem: Our data is processed and transferred among hundreds of microservices and stored in different formats in multiple data stores including Redshift, S3, Kafka, Cassandra, etc. Currently we have thousands of batch jobs running daily, and it is increasingly difficult to understand the dependencies among them. Imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by a few critical Yelp services; you are about to make structural changes to the batch job and want to know who and what downstream to your service will be impacted. Or imagine yourself in the role of a machine learning engineer who would like to add an ML feature to their model and ask — “Can I run a check myself to understand how this feature is generated?”
Spark-Lineage: Spark-Lineage is built to solve these problems. It provides a visual representation of the data’s journey, including all steps from origin to destination, with detailed information about where the data goes, who owns the data, and how the data is processed and stored at each step. Spark-Lineage extracts all necessary metadata from every Spark-ETL job, constructs graph representations of data movements, and lets users explore them interactively via a third-party data governance platform.
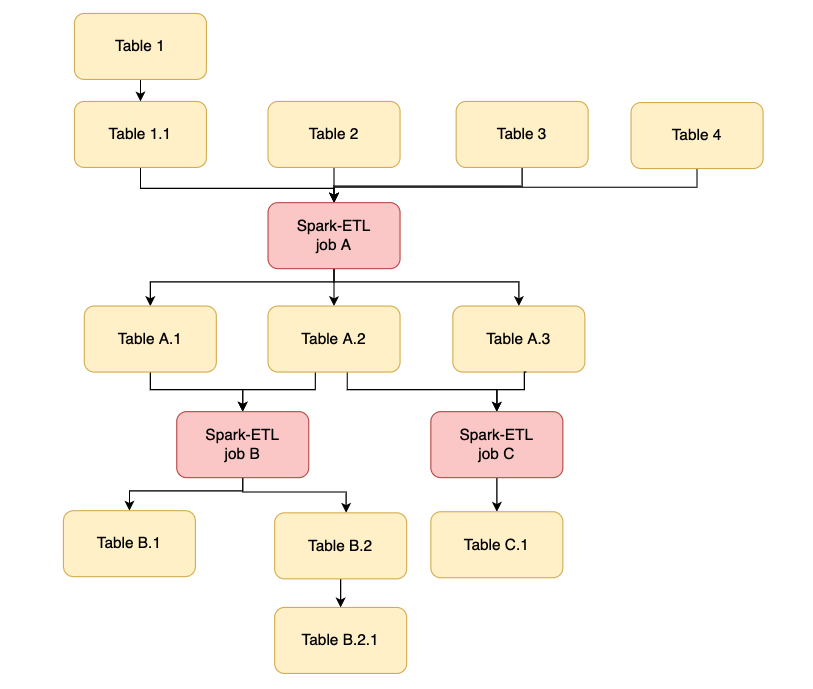
Figure 1. Example of Spark-Lineage view of a Spark-ETL job
Spark-Lineage in detail
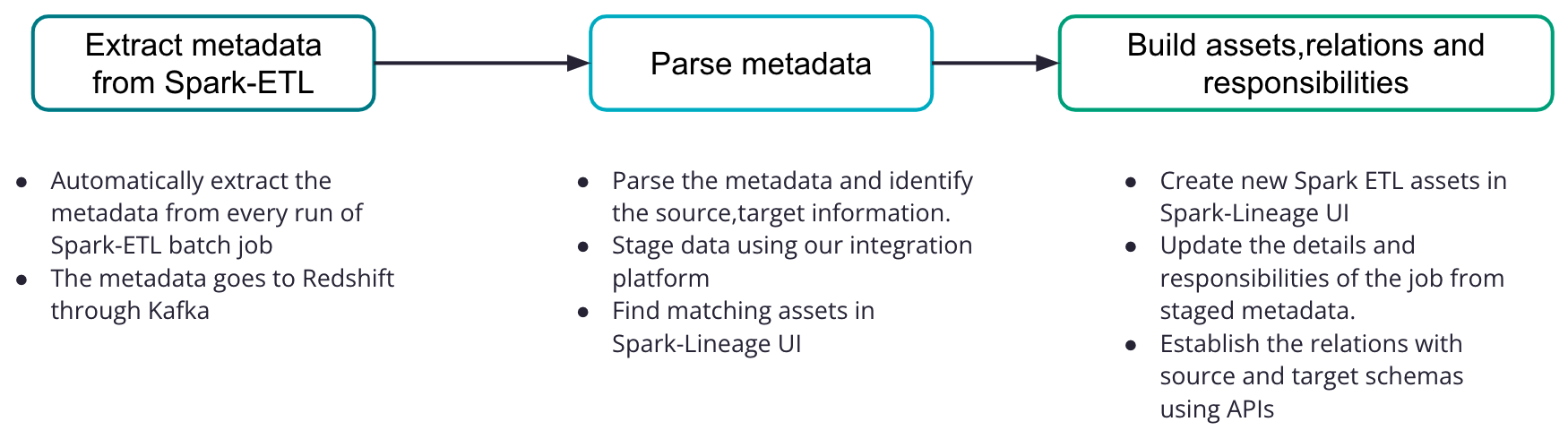
Figure 2. Overview of Spark-Lineage
Extracting metadata from Spark-ETL
To run a Spark job with Spark-ETL is simple; the user only needs to provide (1) the source and target information via a yaml config file, and (2) the logic of the data transformation from the sources to the targets via python code.
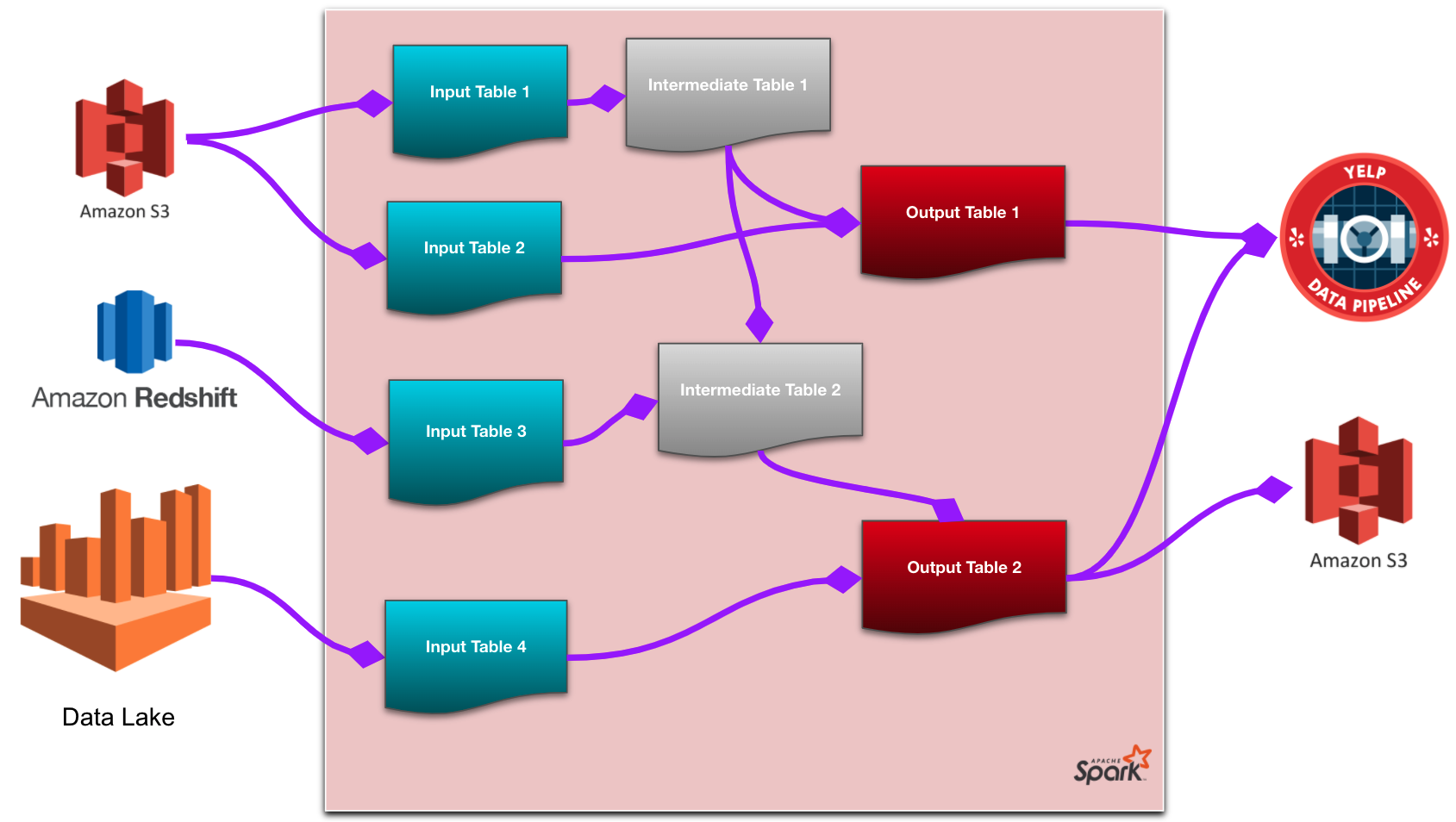
Figure 3. An example diagram of a Spark-ETL job
On the backend side, we implement Spark-Lineage directly inside Spark-ETL to extract all pairs of source and target tables having dependency relationships from every batch job. More precisely, we use the NetworkX library to construct a workflow graph of the job, and find all pairs of source and target tables that have a path between them in the corresponding Directed Acyclic graph (DAG) workflow of that job. All the middle tables in the transformation are not recorded in Lineage because they are temporary. For example, (Input Table 1, Output Table 2) is a pair in Figure 3 since there is a path between them, while (Input Table 2, Output Table 2) is not. For every such pair, we emit a message to Kafka including the identifiers of the source and target, together with other necessary metadata. These messages are then transferred from Kafka to a dedicated table in Redshift.
The reason we go with a two-step process instead of sending messages directly to one place is that Redshift has maintenance downtime while Kafka is highly available to receive newly emitted messages at all times. On the other hand, storing data in Redshift is highly durable and easy to query for analytics purposes. At Yelp, we have on the order of thousands of batches per day, and on average each job emits around 10 messages. In total, the Lineage table grows by a couple of million rows per year, which can be handled at ease by Redshift. Spark-Lineage then reads from the Redshift table and serves users, using an ETL tool plug-in.
Building Spark-Lineages UI
First, we parse the metadata made available from the above steps in Redshift and identify the source and target information. This metadata is first read into a staging table in the Redshift database. The reason we stage this data is to identify any new jobs that have been introduced in the daily load or to capture any updates to the existing scheduled jobs.
We then create a link (a canonical term for tables, files, etc.) for each Spark-ETL table together with additional information extracted from the metadata. We also add relationships between these jobs with their respective schemas. Finally we establish the connections among source and target tables according to the DAG extracted from Spark-ETL.
A mock-UI of Spark-Lineages is shown in Figure 1, where the user can browse or search for all Spark tables and batch jobs, read the details of each table and job, and track the dependencies among them from their origin to their end.
Spark-Lineage use cases
Understanding a Machine Learning feature
Data scientists working on Machine Learning models often look for existing data when building new features. In some cases the data they find might be based on different assumptions about what data should be included. For example, one team may include background events in a count of all recent events that a given user has performed, when the model does not wish to include such events. In such a case, Spark-Lineage allows a team to track down what data is used to identify these different decisions and what data can alleviate the discrepancies.
Understanding the impacts
One of the major advantages of having data lineage being identified and documented is that it enables Yelpers to understand any downstream/upstream dependencies for any changes that will be incorporated into a feature. It also provides an ability for easy coordination across relevant teams to proactively measure the impact of a change and make decisions accordingly.
Fixing data incidents
In a distributed environment, there are many reasons that can derail a batch job, leading to incomplete, duplicated, and/or partially corrupt data. Such errors may go silently for a while, and when discovered, have already affected downstream jobs. In such cases, the response includes freezing all downstream jobs to prevent the corrupt data from spreading further, tracing all upstream jobs to find the source of the error, then backfilling from there and all downstream inaccurate data. Finally, we restore the jobs when the backfilling is done. All of these steps need to be done as fast as possible and Spark-Lineage could be the perfect place to quickly identify the corrupted suspects.
Besides, mentioning the responsible team in Spark-Lineage establishes the accountability for the jobs and thus maintenance teams or on-point teams can approach the right team at the right time. This avoids having multiple conversations with multiple teams to identify the owners of a job and reduces any delay in this that could adversely affect the business reporting.
Feature Store
Yelp’s ML Feature Store collects and stores features and serves them to consumers to build Machine Learning models or run Spark jobs and to data analysts to get insights for decision-making. Feature Store offers many benefits, among them are:
- Avoiding duplicated work, e.g. from different teams trying to build the same features;
- Ensuring consistency between training and serving models; and
- Helping engineers to easily discover useful features.
Data Lineage can help improve the Feature Store in various ways. We use Lineage to track the usage of features such as the frequency a feature is used and by which teams, to determine the popularity of a feature, or how much performance gain a feature can bring. From that, we can perform data analytics to promote or recommend good features or guide us to produce similar features that we think can be beneficial to our ML engineers.
Compliance and auditability
The metadata collected in Lineage can be used by legal and engineering teams to ensure that all data is processed and stored following regulations and policies. It also helps to make changes in the data processing pipeline to comply with new regulations in case changes are introduced in the future.
Conclusion
This post introduces the Yelp Spark-Lineage and demonstrates how it helps tracking and visualizing the life cycle of data among our services, together with applications of Spark-Lineage on different areas at Yelp. For readers interested in the specific implementation of Spark-Lineage, we have included a server- and client-side breakdown below (Appendix).
Appendix
Implementation on the server side
Data identifiers
The most basic metadata that Spark-Lineage needs to track are the identifiers of the data. We provide 2 ways to identify an input/output table: the schema_id and the location of the data.
-
Schema_id: All modern data at Yelp is schematized and assigned a schema_id, no matter whether they are stored in Redshift, S3, Data Lake, or Kafka.
-
Location: Table location, on the other hand, is not standardized between data stores, but generally it is a triplet of (collection_name, table_name, schema_version) although they are usually called something different for each data store, to be in line with the terminologies of that data store.
Either way, if we are given one identifier, we can get the other. Looking up schema information can be done via a CLI or PipelineStudio – a simple UI to explore the schemas interactively, or right on Spark-Lineage UI with more advanced features compared to PipelineStudio. By providing one of the two identifiers, we can see the description of every column in the table and how the schema of the table has evolved over time, etc.
Each of the two identifiers has its own pros and cons and complements each other. For example:
- The schema_id provides a more canonical way to access the data information, but the location is easier to remember and more user-friendly.
- In the case the schema is updated, the schema_id will no longer be the latest, while looking up using the pair (collection_name, table_name) will always return the latest schema. Using schema_id, we can also discover the latest schema, but it takes one more step.
Tracking other information
Spark-Lineage also provides the following information:
-
Run date: We collect the date of every run of the job. From this we can infer its running frequency, which is more reliable than based on the description in the yaml file, because the frequency can be changed in the future. In the case we don’t receive any run for a month, we still keep the output tables of the job available but mark them as deprecated so that the users are aware of that.
- Outcome: We also track the outcome (success/failure) of every run of the job. We do not notify the owner of the job in case of a failure, because at Yelp we have dedicated tools for monitoring and alerts. We use this data for the same purpose as above; if a service fails many times, we will mark the output tables to let the users know about that.
- Job name and yaml config file: This helps the user quickly locate the necessary information to understand the logic of the job, together with the owner of the job in case the user would like to contact for follow-up questions.
- Spark-ETL version, service version, and Docker tag: This information is also tracked for every run and used for more technical purposes such as debugging. One use case would be if an ML engineer finds out a statistical shift of a feature recently, he can look up and compare the specific code of a run today versus that of last month.
Implementation on the client side
Representation of Spark ETL jobs: As a first step to represent a Spark ETL job, a new domain named “Spark ETL” is created. This enables easy catalog searching and results in a dedicated area for storing the details of Spark-ETL jobs from the Redshift staging table. Once the domain is available, unique links (for the spark ETL jobs) are created in the data governance platform with job name as the identifier.
Adding metadata information: The details of the Spark ETL job (e.g., Repository, source yaml, etc.) are attached to the respective links created above. Each of the metadata information is given a unique id and value with a relation to the associated job. The current mechanism implemented for the Spark ETL jobs can be extended to represent the additional information in future.
Assign accountability: As the information about the owners is fetched from Kafka into Redshift, the responsibility section of the job link in the data governance platform can be modified to include the “Technical Steward” – an engineering team who is accountable for the Spark ETL job, including producing and maintaining the actual source data and responsible for technical documentation of data and troubleshooting data issues.
Establishing the lineage: Once the Spark-ETL jobs and the required metadata information are made available in the data governance platform, we establish the 2-way relation to depict source to Spark ETL job and Spark ETL job to target relation. The relations are established using a REST POST API call. After the relations are created, the lineage is auto-created and is made available for use. There are multiple views that can be used for depicting the relations but “Lineage View” captures the dependencies all the way until Tableau dashboards (See Figure 1).
Acknowledgements
Thanks to Cindy Gao, Talal Riaz, and Stefanie Thiem for designing and continuously improving Spark-Lineage, and thanks to Blake Larkin, Joachim Hereth, Rahul Bhardwaj, and Damon Chiarenza for technical review and editing the blog post.
Become an ML Platform Engineer at Yelp
Want to build state of the art machine learning systems at Yelp? Apply to become an ML Platform Engineer today.
View Job