Rebuilding a Cassandra cluster using Yelp’s Data Pipeline

-
Muhammad Junaid Muzammil, Software Engineer
- Jan 30, 2023
Robots are frequently used in the manufacturing industry for numerous use-cases. Amongst many, one case is to eliminate defective products automatically from reaching the finished goods inventory. The same principles of these systems can be adopted to filter out malformed data from datastores. This blog post deep dives into how we rebuilt one of our Cassandra(C*) clusters by removing malformed data using Yelp’s Data Pipeline.
Apache Cassandra is a distributed wide-column NoSQL datastore and is used at Yelp for storing both primary and derived data. Many different features on Yelp are powered by Cassandra. Yelp orchestrates Cassandra clusters on Kubernetes with the help of operators (explained in our Operator Overview post). At Yelp, we tend to use multiple smaller clusters based on the data, traffic and business requirements. This strategy assists in containing the blast radius in case of failure events.
Motivation
For us at Yelp, the primary driver for this effort was the discovery of data corruption across multiple nodes inside one of our Cassandra clusters. This corruption was widespread to different tables including those in the system keyspace. The following were some of the events that happened as we discovered the issue.
-
Numerous exceptions started happening in the Cassandra logs indicating the corruption. The exceptions were found to be happening over multiple nodes in the cluster.
-
Repairs began failing on the Cassandra cluster, which can lead to inconsistencies and data resurrection.
-
The compaction process was seen failing on the Cassandra cluster. The compaction process allows SSTable (Sorted String Table) to be merged together, leading to maintenance of fewer SSTables, and hence improved read performance.
Since the corruption was widespread, removing SSTables and running repairs wasn’t an option as it would have led to data loss. Also, based on corruption size estimates and recent data value, we opted not to restore the cluster to the last corruption free backed up state.
More technical details about the corruption and the initial remediation steps like repairs and data scrubbing are covered in the Appendix. Though those steps didn’t help us in fixing the issue, they provide vital information about the nature of the corruption.
Rebuilding Cassandra Cluster
In order to mitigate the issue and stop more data from getting corrupted, we decided to rebuild a new cluster by migrating data from the existing cluster.
Overall Strategy
The overall high level strategy for rebuilding a new Cassandra cluster for mitigating the issue is quite similar to the sortation systems used for quality checking in the manufacturing industry. Within the industry, automatic sorters are installed on the conveyors that inspect the product and filter out the defective ones from reaching the finished goods inventory.
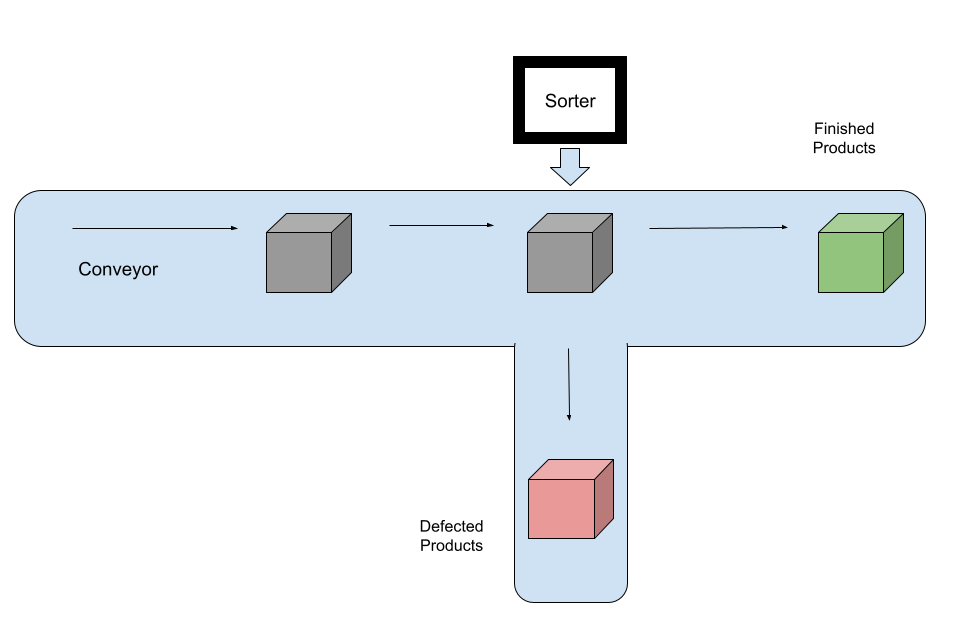
Conceptual Model of Sortation System
Using the same principle, a Data Pipeline was created to rebuild a new Cassandra cluster after eliminating the malformed data as depicted in the figure below.
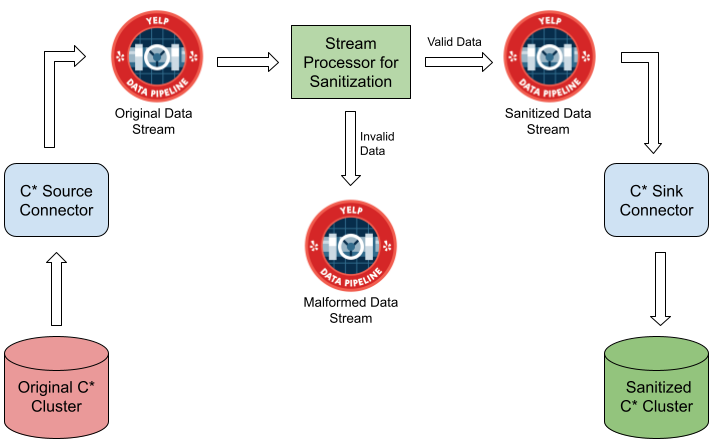
Corruption Mitigation Strategy at a High Level
The process extensively relies on the different connectors and pipeline tools developed by Yelp’s Data Infrastructure teams. Here’s a quick explanation of the overall dataflow.
-
A new Cassandra cluster “Sanitized Cassandra Cluster” was spun up on Yelp’s modern Kubernetes infrastructure. This allowed the new cluster to leverage from many hardware and software upgrades.
-
The data from the original Cassandra cluster was published into Yelp’s Data Pipeline to create an “Original Data Stream” through Yelp’s Cassandra Source Connector. The Cassandra Source connector relies on the Change Data Capture (CDC) feature, which was introduced in the Cassandra 3.8 version. More details about the Cassandra Source connector can be found in the blogpost: Streaming Cassandra into Kafka in (near) Real Time.
-
The Stream Processors allow transformation of the Data Pipeline streams. This stream process acts as an “automatic sorter” responsible for eliminating the malformed data from reaching the destination. Of the various different supported stream processors by Yelp’s Data Pipeline, Stream SQL was adopted here in this case as it allowed writing stream processing applications in a language similar to SQL. While writing the stream processor, there were a few considerations required.
-
Source and Destination Data Stream identifiers: The identifiers allow selection of the input & output Data Pipeline topics.
- Sanitization Criteria:
This specifies the valid list/ranges of values for fields inside the Data Pipeline. Inspecting the data, we figured out that using a criteria based on the id & time values can filter out malformed data. A simple stream SQL statement for sanitizing on the basis of a criteria based on non-negative id and valid time_created range would look as follows.
SELECT id, created_time FROM <source datastream identifier> WHERE id IS NOT NULL AND id >= 0 AND time_created IS NOT NULL AND TIMESTAMPDIFF(DAY, CURRENT_TIMESTAMP, time_created) <= 1 AND TIMESTAMPDIFF(YEAR, CAST('2000-01-01 00:00:00' AS TIMESTAMP), time_created) >= 0; - Malformed Stream Criteria:
This allows creation of a data stream containing all the malformed data. That can simply be created by inverting the sanitization stream SQL statement.
SELECT id, created_time FROM <source datastream identifier> WHERE NOT( id IS NOT NULL AND id >= 0 AND time_created IS NOT NULL AND TIMESTAMPDIFF(DAY, CURRENT_TIMESTAMP, time_created) <= 1 AND TIMESTAMPDIFF(YEAR, CAST('2000-01-01 00:00:00' AS TIMESTAMP), time_created) >= 0 );
-
-
The data from the sanitized data stream was ingested into the Sanitized Cassandra Cluster through Yelp’s Cassandra Sink Connector.
-
The data from the malformed data stream was further analyzed to discover
- whether the corruption is legit
- what percentage of data got corrupted
- whether there is a possibility of extracting useful information from it
Data Validation
Like any other data migration project, validation of data was of utmost importance. A couple of steps were used for data validation, which ultimately verified the above strategy.
Validation using Random Sampling
This is perhaps the most common strategy for validating data migration analogous to Quality Control inspections of finished products in manufacturing industries. A random subset of the migrated data was selected and value comparison for all the columns was done between the Original Cassandra Cluster and Sanitized Cassandra Cluster.
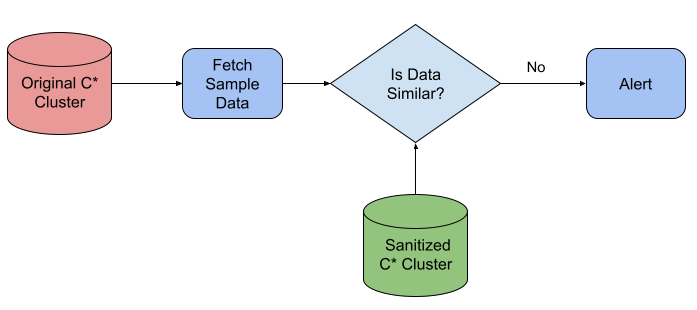
Data Validation using Random Sampling
Since this is a statistical sampling technique, the confidence level greatly depends upon the sample size. Cochran’s equation helped us in estimating a sample size for sufficiently large tables since the data residing inside the Cassandra tables was sufficiently large.
\[n = Z^2 p (1-p) / e^2\]where n is the sample size, Z is the z-score for confidence interval; chosen as 1.96 for 95% confidence interval p(1-p) determines the degree of variability; Value of p chosen as 0.5 for maximum variability e is the sampling error; used as 5%
The total number of partitions randomly sampled were 400 (>385 from Cochran’s equation) for the tables. One of our tables has a total data of 162G divided into approximately around 7.2 million partitions.
Validation using Comparison Tee
The Database Reliability Engineering team at Yelp uses a proxy for our Cassandra datastores in order to isolate the infrastructure complexity from the developers. The proxy supports a few different wrappers, with Tee being particularly relevant here.
Until this point, the traffic was still being served by the Original Cassandra Cluster. This Teeing feature allowed us to do further verification from client request perspectives. The conceptual model of Teeing is depicted in the figure below.
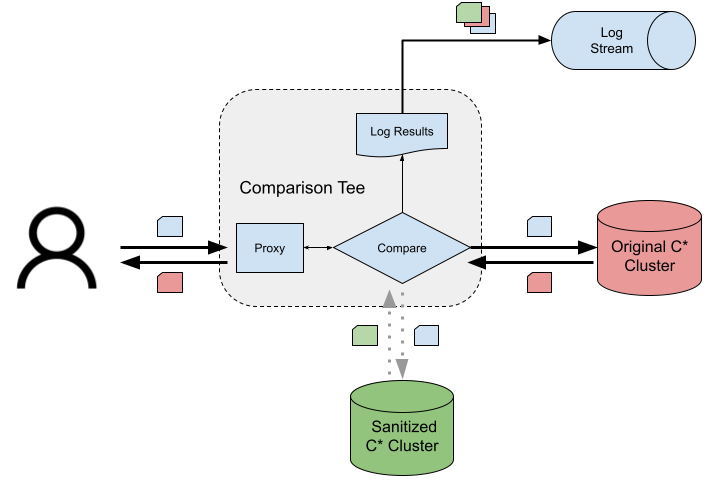
Data Validation using Comparison Tee
Here is a brief explanation of the model.
- A fraction of read requests were sent to both the Original Cassandra Cluster and the Sanitized Cassandra Cluster before switching the traffic to the sanitized cluster.
- Comparison was done on the responses observed from both the clusters, and the comparison results were logged.
- Response from the Original Cassandra Cluster was sent back to the requesting client.
- Offline Analysis of logged comparison results led to Data validation between the two clusters.
An example client performing Comparison Tee for keyspace kspace would look like:
original_client = DataClient(cluster="original_cassandra_cluster"
)
sanitized_client = DataClient(cluster="sanitized_cassandra_cluster"
)
def compare_results(main_result, tee_result):
if main_result != tee_result:
return {"original": main_result, "sanitized": tee_result}
return {}
teed_client = ComparisonTee(
client=original_client,
tee_client=sanitized_client,
comparison_fn=compare_results,
)
Switching Traffic
The total amount of corruption observed in the cluster was roughly estimated to be around 0.009% of the total data. Once the data was completely validated, the traffic was switched from the Original Cassandra Cluster with faults to the Sanitized Cassandra Cluster. The Original Cassandra Cluster was torn down after moving the entire traffic. This allowed a seamless transition with zero downtime and without any visible effect on the user experience.
Learnings
The execution of the project allowed us to rebuild the cluster with sanitized data, but also enabled us to move our cluster to an improved infrastructure with zero downtime. There were quite a few learnings from this project.
-
It is important to have validation plans at each stage (and if possible multiple validation criteria) when carrying out a complex data movement.
-
Cassandra logs provide great insight into the database operations being performed. This includes information about any uncaught exceptions, garbage collector, cluster topology, compaction, repairs etc. Any anomaly observed inside the logs can be pretty useful for debugging errors or performance issues. From an operational perspective, it’s better to create alerts for any new uncaught exceptions and analyze them as they happen.
-
Repairs are essential for a guaranteed data consistency on a Cassandra cluster in case one of the data nodes goes down for an extended duration (greater than max_hint_window_in_ms). Absence of periodic repairs on a Cassandra cluster can lead to data integrity issues. However, running repairs on an unhealthy, broken or corrupted cluster is not recommended and is likely going to make things worse.
There is so much more to write here with respect to the learnings - Data Pipeline infrastructure tools, datastore connectors, Scribe Log Streams, CI/CD pipelines for Cassandra deployments - and much more. If you are interested to know more about these, what better way is there than to come and work with us.
Acknowledgements
- Thanks to Adel Atallah, Michael Persinger, Toby Cole and Sirisha Vanteru who assisted at various stages of the design and implementation of the project.
- The author would like to thank the Database Reliability Engineering team at Yelp for various contributions in handling the issue.
Appendix
Data Corruption Overview
The corruption was detected when engineers observed exceptions of the following form in the Cassandra system.log file in one of the clusters.
Last written key DecoratedKey(X) >= current key DecoratedKey(Y)
This Cassandra cluster was still on our old AWS EC2 based infrastructure as described in our Operator overview post. Along with the above exception, the engineers also observed the Cassandra process crashing on a few nodes in the same cluster while trying to deserialize CommitLog Mutations. A mutation is synonym to a Database write since it changes the data inside the database. Exceptions of the following form were observed in the Cassandra logs.
org.apache.cassandra.serializers.MarshalException: String didn't validate
Repairs are required for a guaranteed data consistency on a Cassandra cluster in case one of the data nodes goes down. At Yelp, we run periodic repairs on Cassandra clusters for fixing any data inconsistencies. However, following this issue, engineers observed that the repairs started to fail on the above cluster, and actually caused the “Last written key” exception to spread to all the nodes inside that cluster. The cluster contained two data centers, with each having a replication factor of 3. Even though there wasn’t any observable impact due to necessary replication and validation safeguards, the exceptions still required further analysis from operational perspectives. An immediate action was taken to stop the repairs from running for this cluster.
The investigation around the exception revealed that at-least one of the SSTable (Sorted String Table) rows was unordered, which caused the compaction operation to fail. SSTables are immutable files that are always sorted by the primary key. This indicated a corruption event inside the Cassandra SSTables. These SSTable corruptions were observed for different tables, including the tables in the system keyspace, across multiple nodes in that cluster, indicating a distributed corruption present on multiple nodes in the cluster. This means that using full table scans on user keyspaces via a batch processing framework like Spark wouldn’t completely solve the problem, as the corruptions would still be persisted in system keyspaces.
Since the SSTable corruption was widespread across all the nodes inside the cluster, removing the SSTables and running the repairs wasn’t an option, as this will lead to data loss.
Restoring the cluster from the periodic backups was another open option for us. However, there’s a trade-off for losing recent data inserted after the last backup with no corruptions. A quick impact analysis revealed that it’s more valuable to retain the recent data as compared to the old corrupted one.
Scrubbing SSTables
Data Scrubbing process is used as a data cleansing step, and aims to remove the invalid data from the database. With Cassandra, we had 2 options for running the scrubbing process.
- Online Scrubbing
- Offline Scrubbing
Online Scrubbing
Online scrubbing can be invoked using either the nodetool scrub or nodetool upgradesstables command, with the latter being recommended. Since the online scrubbing process is much slower than the offline one, we opted for the offline scrubbing.
Offline Scrubbing
Offline scrubbing can be performed with an opensource tool sstablescrub, that gets shipped with Cassandra. We stopped the Cassandra node gracefully after running nodetool drain, as it is a prerequisite for the execution of sstablescrub. The data for keyspace kspace & table table can be scrubbed as follows.
sstablescrub kspace table
However, there were failures seen in the offline scrubbing process and following logs were observed in the output.
WARNING: Out of order rows found in partition:
WARNING: Error reading row (stacktrace follows):
WARNING: Row starting at position 491772 is unreadable; skipping to next
........
WARNING: Unable to recover 7 rows that were skipped. You can attempt manual recovery from the pre-scrub snapshot. You can also run nodetool repair to transfer the data from a healthy replica, if any
WARNING: Row starting at position 22560156 is unreadable; skipping to next
null
Exception in thread "main" java.lang.AssertionError
at org.apache.cassandra.io.compress.CompressionMetadata$Chunk.<init>(CompressionMetadata.java:474)
at org.apache.cassandra.io.compress.CompressionMetadata.chunkFor(CompressionMetadata.java:239)
at org.apache.cassandra.io.util.MmappedRegions.updateState(MmappedRegions.java:163)
at org.apache.cassandra.io.util.MmappedRegions.<init>(MmappedRegions.java:73)
at org.apache.cassandra.io.util.MmappedRegions.<init>(MmappedRegions.java:61)
at org.apache.cassandra.io.util.MmappedRegions.map(MmappedRegions.java:104)
at org.apache.cassandra.io.util.FileHandle$Builder.complete(FileHandle.java:362)
at org.apache.cassandra.io.util.FileHandle$Builder.complete(FileHandle.java:331)
at org.apache.cassandra.io.sstable.format.big.BigTableWriter.openFinal(BigTableWriter.java:336)
at org.apache.cassandra.io.sstable.format.big.BigTableWriter.openFinalEarly(BigTableWriter.java:318)
at org.apache.cassandra.io.sstable.SSTableRewriter.switchWriter(SSTableRewriter.java:322)
at org.apache.cassandra.io.sstable.SSTableRewriter.doPrepare(SSTableRewriter.java:370)
at org.apache.cassandra.utils.concurrent.Transactional$AbstractTransactional.prepareToCommit(Transactional.java:173)
at org.apache.cassandra.utils.concurrent.Transactional$AbstractTransactional.finish(Transactional.java:184)
at org.apache.cassandra.io.sstable.SSTableRewriter.finish(SSTableRewriter.java:357)
at org.apache.cassandra.db.compaction.Scrubber.scrub(Scrubber.java:291)
at org.apache.cassandra.tools.StandaloneScrubber.main(StandaloneScrubber.java:134)
This led to failure in complete removal of corrupted rows inside the SSTable.
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job