Yelp Content As Embeddings

-
Fanny Salvail-Berard, Machine Learning Engineer
- Apr 20, 2023
Yelp aims to offer easily accessible high-quality content. We need to tag, organize and rank online content to attain this goal. For this purpose, Yelp engineers have started using general embeddings on different data. It improves usability and efficiency for all kinds of model development. Having embeddings that encapsulate semantic information readily available for the massive amounts of data Yelp owns makes implementing new deep learning models easier, since it can serve as an excellent baseline for any model input.
This blog post discusses how the Content and Contributor Intelligence team generates low-dimensional representations of review text, business information and photos for any unspecified machine learning task.
Text Embeddings
Text embedding has been researched in depth in the scientific community. First, embeddings were generated with sparse vectors representing words. Embeddings developed further with context-aware embeddings since the same word can have different meanings depending on how it is used in a sentence. With the use of transformers in recent years, we now have text snippet embeddings that capture more semantic meaning.
Semantic comprehension of the text is essential for Yelp. Yelp reviews are our most valuable asset since they contain a lot of business context and sentiment. We want to capture the essence of each review text to serve their information to our users better. We looked for versatility in our embedding as we try to use the same embedding in various tasks: tagging, information extraction, sentiment analysis and ranking.
Embeddings based on reviews are currently generated by the Universal Sentence Encoder off-the-shelf model offered by Tensorflow. This blog section will present the USE model, any modifications tested to improve it and its advantages for the Yelp dataset.
Universal Sentence Encoder
The Universal Sentence Encoder (USE) shows many advantages for Yelp data. It transforms varying sentence lengths into a fixed-length vector representation. The generated representation aims to encode the meaning and context of the text snippet instead of simply averaging the words together or getting their position in a learned latent space like Latent Dirichlet Allocation (LDA).
The paper presenting the Universal Sentence Encoder trained a model on various data sources and tasks like text classification, semantic similarity, and clustering. Training a model on varying tasks makes it more general and captures all the possible expressiveness of a text snippet. The model demonstrates promising results on eight transfer tasks and suggests that training this model on diversified data sources and sufficiently varied tasks makes it universal, as the name suggests. Universal embeddings are what we were looking for to exploit our most diverse and deep content, Yelp reviews. We want to extract the business information and context given in the review, do sentiment analysis and even rank the reviews based on their relevance and information diversity with the help of the generated review embeddings.
The deep averaging network (DAN) version of USE takes words and bigram embeddings and then averages them together. This resulting embedding serves as input to a feedforward deep neural network that produces the universal sentence embedding we aim to obtain.
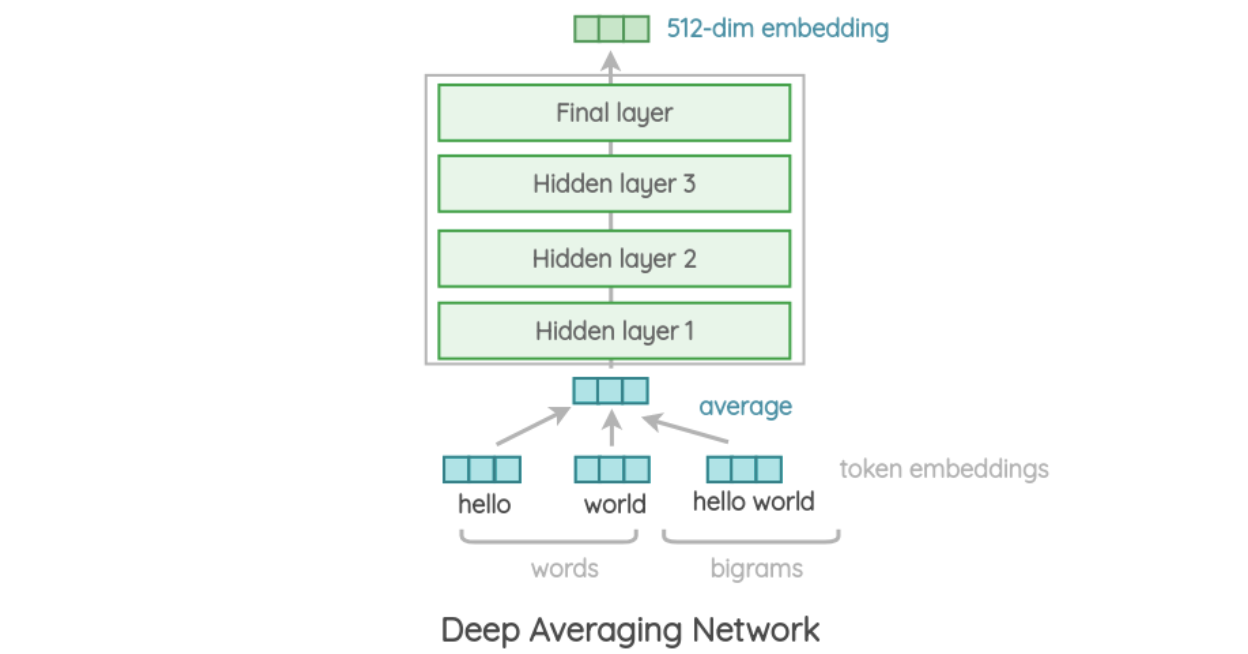
An architecture overview of DAN, taken from https://amitness.com/2020/06/universal-sentence-encoder/
Yelp Exploration
By nature, most NLP models will perform better when trained on domain-specific text. With this hypothesis, we developed and compared a Yelp fine-tuned encoder with the pre-trained USE model available on TensorFlow-Hub. We aimed to create a better model adapted to the Yelp domain than the pre-trained model. After fine-tuning the model, we wanted to use it to generate an embedding for reviews specifically.
Yelp data contains different text formats like reviews, captions, searches, and survey responses that can all be used to fine-tune the USE encoder. Since these models are not generative, we needed to create generic supervised learning tasks to fine-tune the model on Yelp domain text.
Some examples of learning tasks we used:
- Review Category Prediction
- Review Rating Prediction
- Search Category Prediction
- Sentence Order Prediction
- Same Business Prediction
For the evaluation task, we chose:
- Photo Caption Classification
- Menu Item Classification
- Business Property Classification
- Synonym Generation for a phrase input
The model evaluation made on the Yelp domain showed that the ready-to-use model performed better than or as well as the Yelp pre-trained encoder for all tasks. These results happened because either the Yelp domain touches many generic subjects in the USE model or our experiments lacked task diversity to gain an edge. Based on these results, we decided to keep the off-the-shelf USE pre-trained model.
USE on Yelp Domain
We can measure two embeddings’ relatedness when they are projected together in the same vector space. This is helpful for semantic search, cluster analysis, and other applications.
Below is a graph representation of a USE embedding space applied on the Yelp dataset. We wanted to verify that the embedding representation and their vector space position related to each other, which is expected of a semantic embedding that captures the general subject of the text snippet it encodes.
We computed the cosine similarity between different embedding representations of reviews from different categories and regrouped them in the following heatmap. We verified that reviews from the same category domain were closer in the vector space than reviews from a different domain, as shown by the lighter boxes in the graph below.
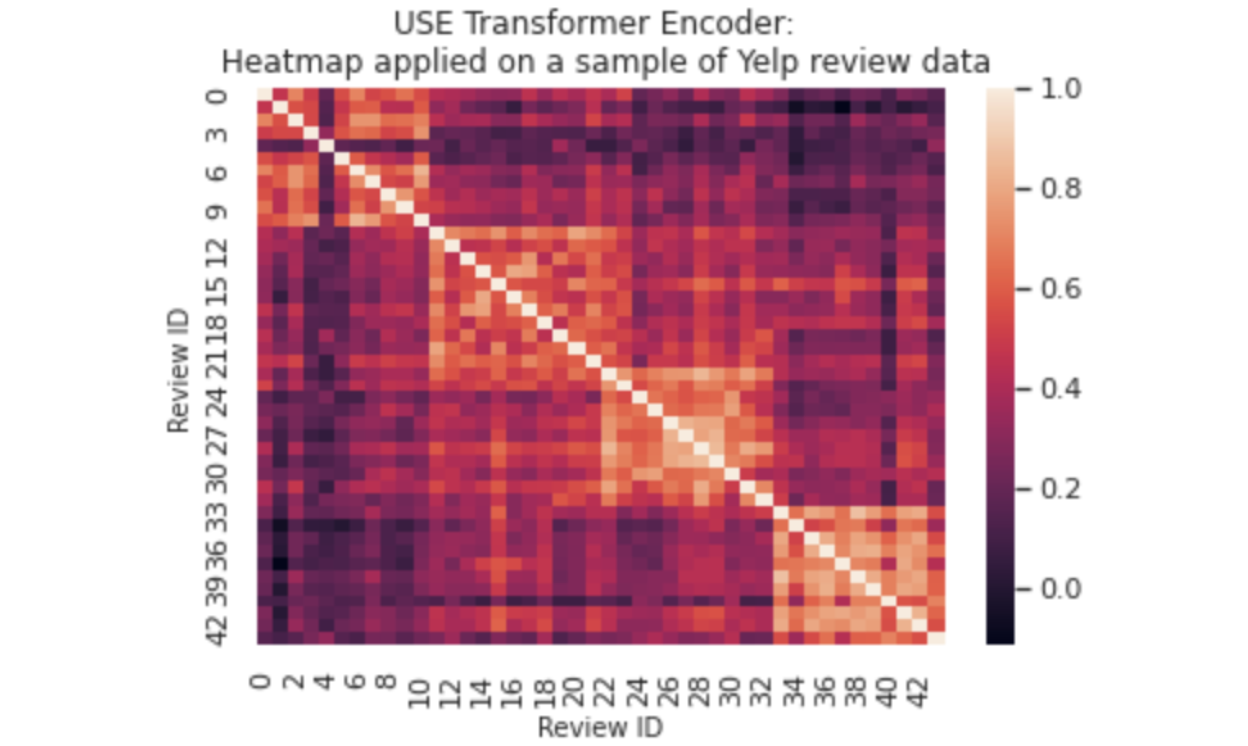
Numbers on the axis reference 44 different reviews IDs. Those reviews business categories are shown in the table below. We can see a clear correlation between reviews from a similar business type.
| Labels association table | |
|---|---|
| Reviews ID | Yelp Business Type |
| 0 to 10 | Restaurants |
| 11 to 21 | Dry Cleaning |
| 22 to 33 | Groomer |
| 33 to 43 | Plastic Surgeon |
Business Embeddings
After Yelp created embedding representations of reviews which showed great potential across several projects, we explored different possibilities to grow our vector representations. We started exploring ways to develop a business vector representation using all of its metadata.
We chose to base our business embedding on user content. We select the 50 most recent reviews and average their vector embeddings to create our first business embedding representation. It’s a great way to start since reviews contain quality content describing the businesses. The next step will be to add the photo embeddings as well.
Business embeddings help generate a top-k similarity list to relate businesses to other businesses, users to businesses and users to users based on their matching business interaction history. This correlation matrix of similarity helps show signification recommendations like “Users like you also liked…” or “Since you like business A, you might like business B”. You can learn more about this use case in this blog post.
Photo Embeddings
Review and business vector representations have existed at Yelp for some time already. Last year, when the paper that presented the Contrastive Language-Image Pre-training (CLIP) model was published, it inspired us at Yelp to generate more semantic data representation based on photos this time.
Research made on photo’s semantic representation improved significantly with the use of transformers applied on images. This section will present OpenAi’s CLIP model, its known capabilities, CLIP’s pre-trained effectiveness on the Yelp domain and some vulnerabilities that are good to be aware of before using it.
CLIP model
Our photo encoder is based on the CLIP model’s performance and ability. This model has learned to associate an image with the most relevant text given. It is a pre-trained zero-shot model that associates a natural language with high-level visual concepts.
CLIP’s input is two sets of features, an image and text. The feature embedding of a single image and a bunch of possible texts are generated alongside their respective encoders. After, CLIP aims to regroup similar image-text pairs in the embedding space and distance dissimilar ones using contrastive representation learning based on their cosine similarity. Our first goal here is to generate photo embeddings. To that end, we experimented with the CLIP pre-trained model then used the generated embeddings on the Yelp dataset in the next section and compared it with our models in production.
The CLIP model is a zero-shot model, meaning it can infer successfully from an unseen dataset. A zero-shot model is an opportunity for Yelp to better identify and tag unseen photo categories to improve photo search. Our classifier won’t need a thousand examples for each new tag or label added.
Research done on CLIP showed its multimodal neuron ability in an abstract concept. Instead of reacting to a specific image feature like a Convolutional Neural Network model’s neuron, it responds to a cluster of ideas with a high-level theme.
In the table below are some examples of high-level themes. You can see tombstones in the image associated with the word Halloween. Those images, generated using different tools referenced in the openAI blog post, try maximizing a single neuron activation with gradient-based optimization for the input (i.e. “Halloween”) and the distribution of images.
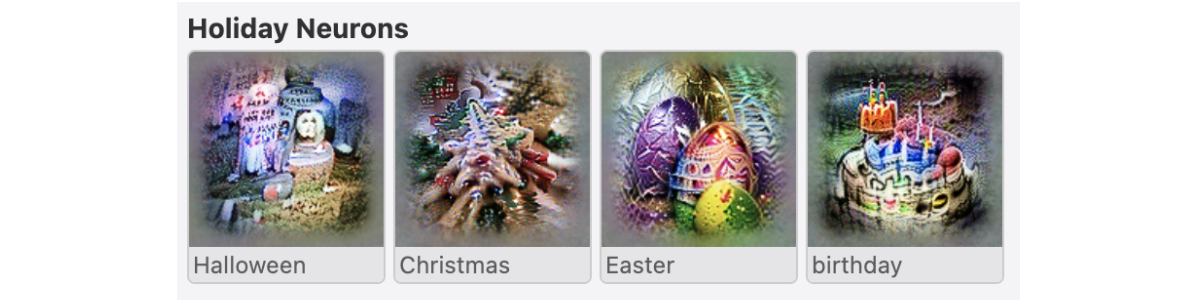
Image taken from openAI blogpost: https://openai.com/blog/multimodal-neurons/
Evaluation made on Yelp Photo Dataset
We compared the CLIP model with three existing ResNet50 classification models to evaluate CLIP’s capability on the Yelp domain. Our 5-way Restaurant, Food and Nightlife classifier identifies Food, Drinks, Menu, Interior or Exterior categories for photos. The food classifier consists of 27 food dishes, and the Home Services Contractor Classifier identifies five categories of repairs. We tested the CLIP model without any fine-tuning applied to the pre-trained model found on HuggingFace. We manually engineered the classes’ labels to optimize the CLIP model performance but didn’t optimize the categories themselves since we wanted a direct comparison with the existing models.
5-Way Restaurant, Food and Nightlife Classifier
While experimenting, we rapidly concluded that we could not simply reuse our previously-used class names as input. The paper suggested adding ‘A photo of’ in front of our title, but it didn’t prove effective for all the categories. The table below contains the label engineering applied to the 5-Way Restaurant, Food and Nightlife classification problem.
| Original Labels | Engineered Labels |
|---|---|
| Drink | A photo of a drink |
| Food | A photo of food |
| Menu | A photo of a menu |
| Interior | A photo of inside a restaurant |
| Outside | A photo of a restaurant exterior |
| A photo of other |
The following table compares the ResNet50 model currently in production and the zero-shot CLIP model. Results for the 5-way restaurant, food and nightlife classifier show that CLIP has potential and that label engineering could beat a domain-trained deep learning model. These results also encourage us to explore further the potential of a fine-tuned CLIP model on Yelp domain.
| Comparison Table of the 5-Way Classifier | ||||
|---|---|---|---|---|
| ResNet50 | CLIP | |||
| Precision | Recall | Precision | Recall | |
| Drink | 96.8 % | 87.1 % | 96 % | 91 % |
| Food | 96.0 % | 92.7 % | 88 % | 91 % |
| Menu | 95.0 % | 80.3 % | 51 % | 94 % |
| Interior | 89.4 % | 92.2 % | 92 % | 77 % |
| Outside | 84.3 % | 94.6 % | 96 % | 80 % |
| Other | 29 % | 38 % |
Let’s dive deeper into the results shown above with the table below. It shows the precision with which the CLIP model predicted the hand-labeled Yelp dataset. More importantly, it shows which categories get mixed up together. Most notable are photos classified as Other by the CLIP model that were otherwise labeled in the dataset.
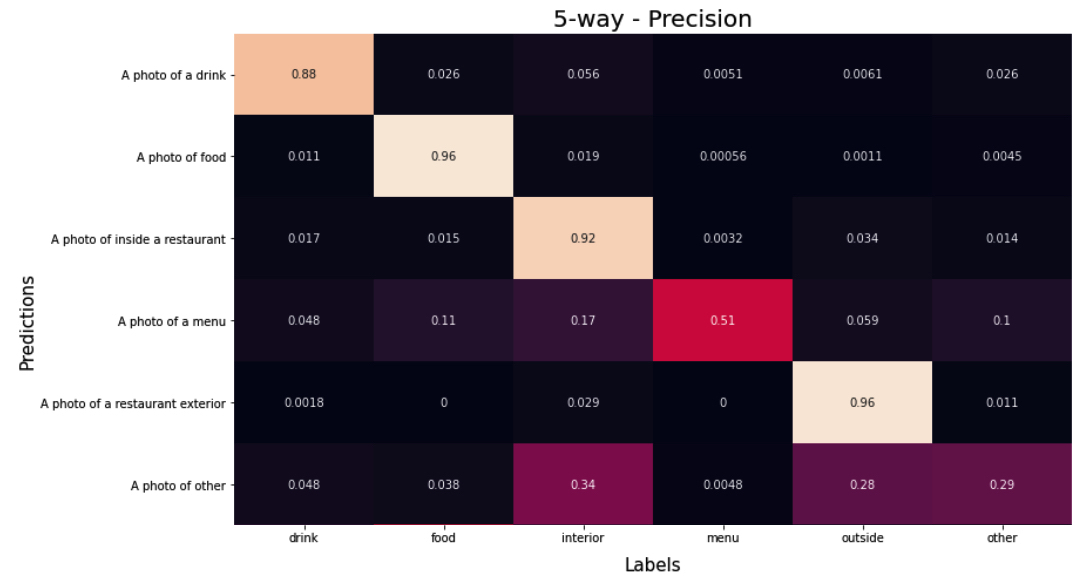
With a closer look, we observe that many Interior and Exterior photos get classified as Other by the CLIP model. Here are some examples for Interior.

Images taken from yelp.com
We can see that these misclassifications are due to photo composition. People are often in the foreground of interior and exterior photos. The CLIP model is built to emphasize the embedding representation of concepts shown in the images. The attention model emphasized foreground elements at the cost of background elements.
Food Classifier
The Food Classifier aims to identify a dish showcased in a photo. The production model is a ResNet50 trained on 27 food classes (Comparison Table found in appendix 1). CLIP performed well in general compared to the production model, but it still needs improvement in multiple categories.
CLIP is a peculiar model. Using it like a ResNet50 might create some error opportunities. First, we must remember that category labels were engineered but not the categories themselves. Too many labels hindered the results of models like ResNet since each label category is trained from scratch and requires many examples.
On the contrary, using as many dish names as possible would better reflect the photo for the CLIP model. CLIP was trained by pairing one image with 32,768 randomly sampled text snippets. The model can work with a wide range of possible outputs. For our comparison tests, category engineering wasn’t done.
Second, we also found that some original dishes might confuse our results. Images labeled Waffles in our dataset were considered misclassified as Chicken Wings or Fried Chicken by the CLIP model. Hand verification shows its classification accurately represents the images that showcase a Texan dish of Fried Chicken and Waffles.

Image taken from yelp.com
| Label | Probability |
|---|---|
| Chicken Wings & Fried Chicken | 44 % |
| Waffles | 11 % |
| Ribs | 9 % |
| Dessert | 9 % |
| Tacos | 5 % |
| Steak | 5 % |
| Sandwiches | 5 % |

Image taken from yelp.com
| Label | Probability |
|---|---|
| Chicken Wings & Fried Chicken | 51 % |
| Waffles | 42 % |
| Ribs | 3 % |
| Pancakes | 1 % |
| Dessert | 1 % |
Lastly, some dishes’ names represent the protein in the meal but aren’t plated to showcase it. For example, the CLIP model misclassified some images labeled Grilled Fish in the Salad category.

Images taken from yelp.com
Home Services Contractor Classifier
Home Services Contractors Classifier got great results with CLIP for most categories. The categories were highly curated in the past to optimize the ResNet50 model in production as it was with the 27-food classifier seen previously. CLIP offers the possibility to remove the restraint of needing a large number of examples for each category our model infers. A review of the possible output classes from CLIP will lead to more diversified content tags on Yelp.
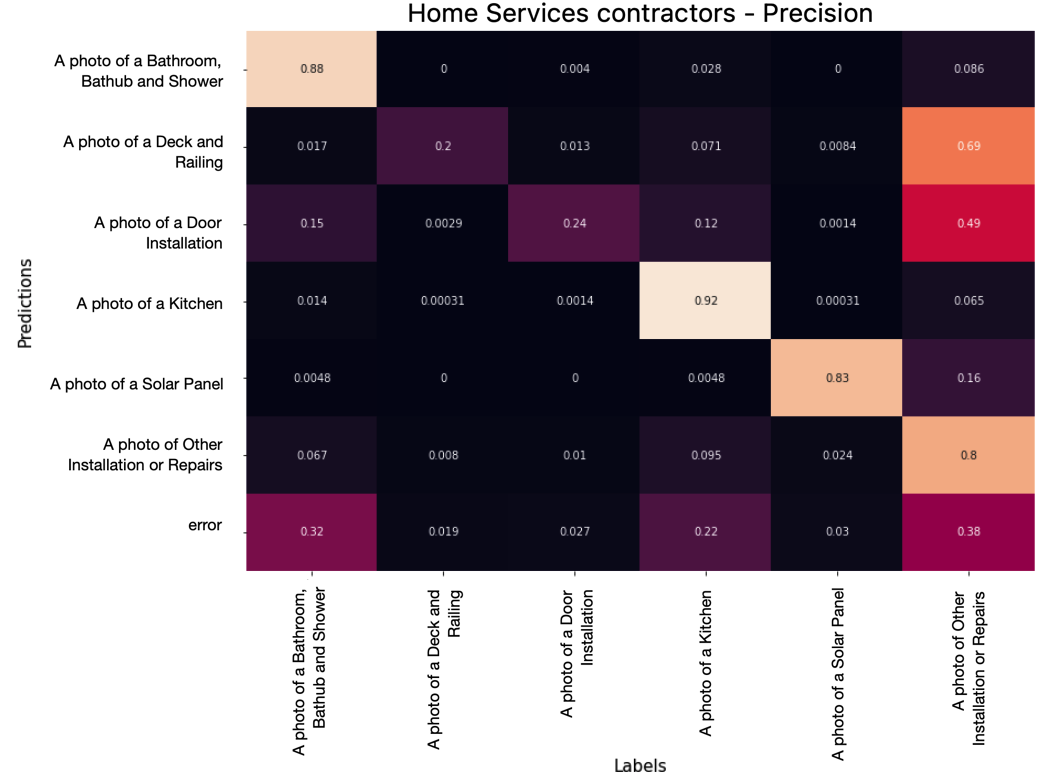
In the confusion matrix above, we can see that CLIP doesn’t identify enough photos labeled “Other” in our dataset. To remedy that, we tried using a 70% compatibility threshold to label an image, with the default being Other. The table below shows the results. The table shows that having a threshold is a tradeoff between increasing precision (decreasing the number of false positives) and decreasing recall (reducing the percentage of positives identified).
| Comparison Table of the Home Services Contractor Classifier | ||||
|---|---|---|---|---|
| CLIP | CLIP - 70% threshold | |||
| Precision | Recall | Precision | Recall | |
| Bathroom, Bathtub and Shower | 88 % | 87 % | 91 % | 82 % |
| Decks and Railing | 20 % | 84 % | 35 % | 76 % |
| Door, Door Repair & Installation | 24 % | 81 % | 38 % | 74 % |
| Kitchen | 92 % | 85 % | 94 % | 79 % |
| Solar Panel | 83 % | 77 % | 89 % | 69 % |
| Other Contractors | 80 % | 57 % | 69 % | 77 % |
CLIP’s vulnerability
Before using CLIP and publishing its results, it’s better to know its vulnerabilities and how to optimize the model performance. We already identified label and category engineering and used threshold. Here we describe another likely inconvenience of the model at Yelp.
Below are some examples of high-level themes, as seen previously. Let’s focus on more abstract concepts like typographical neurons that show images of word snippets related to syllables.

Image taken from openAI blogpost: https://openai.com/blog/multimodal-neurons/
This demonstrates the model’s capability to “read” as mentioned in the image caption. It comes with the caveat of easily fooling the algorithm with typographic attacks. A prominent word like iPod handwritten on a sticker in any photo would classify it as an iPod, even if the picture clearly shows an apple.
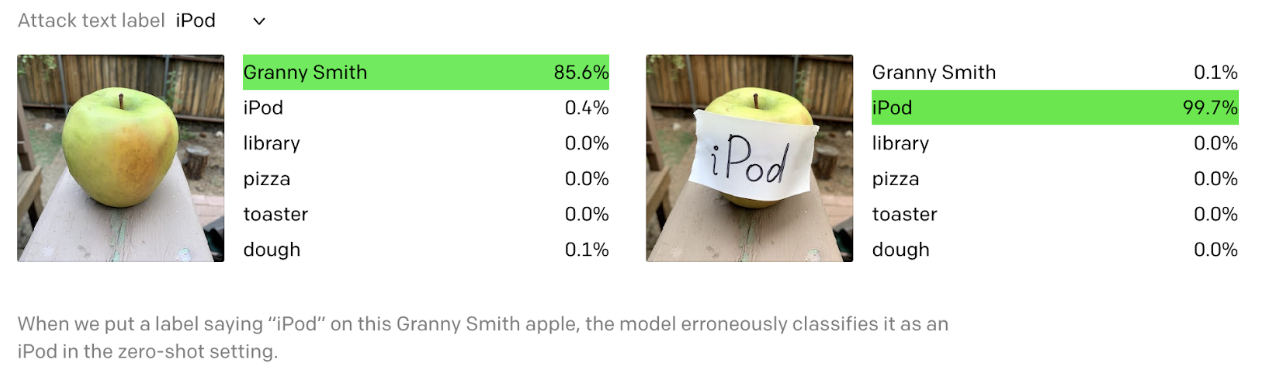
Image taken from openAI blogpost: https://openai.com/blog/multimodal-neurons/
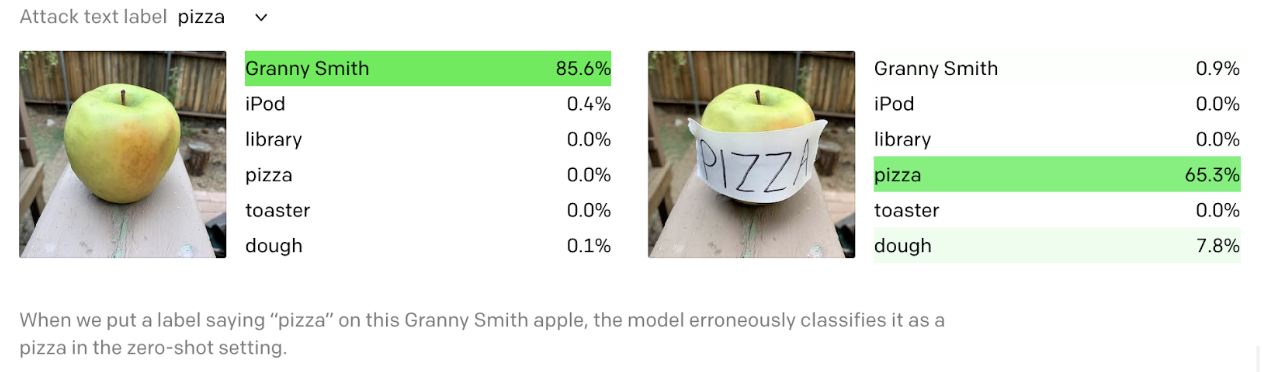
Image taken from openAI blogpost: https://openai.com/blog/multimodal-neurons/
On Yelp’s dataset, it means restaurant merchandise lying around in a photo could create more misclassifications by the model.
Conclusion
While working on this new project, we took the opportunity to review and upgrade our storing system for the vector representation we are responsible for. We aimed to make this data as accessible and easy to use as possible for any internal project.
We needed to generate new embeddings for all our collected Yelp data to complete this project with the identified models and techniques chosen to create our content embeddings.
Yelp aims to constantly grow the breadth, depth, and accuracy of the data we show to our consumers. Review and text embeddings show great promise in helping us improve in all three dimensions.
Many teams are working on the extensive datasets Yelp offers. There are still a lot of unexploited opportunities based on Yelp’s datasets, especially in deep learning. CLIP-based embedding is the first version of photo embedding generation and is only the beginning. Fine-tuning the CLIP model on the Yelp domain will improve the photo embeddings. Our team is presently exploring it. Also, the business embedding is currently only incorporating the review embeddings. It could also use photos or other metadata as inputs.
This project means that Yelp now owns a database with hundreds of millions of embeddings. Many Yelp teams are already exploiting them to improve their products.
Acknowledgements
Many people were involved in these projects, but special thanks to Parthasarathy Gopavarapu, Satya Deo, John Roy, Blake Larkin, Shilpa Gopi, and Jason Sleight. They helped with the design and implementation of these projects or the content of this post.
Appendix
Comparison table Prod (ResNet50) compared to zero-shot CLIP model after some label engineering.
| Comparison Table of the Food Classifier | ||||
|---|---|---|---|---|
| ResNet50 | CLIP | |||
| Recall | Precision | Recall | Precision | |
| Pizza | 0.96 | 0.92 | 0.90 | 0.83 |
| Sushi & Sashimi | 0.87 | 0.78 | 0.79 | 0.69 |
| Ramen & Noodles | 0.82 | 0.95 | 0.70 | 0.55 |
| Sandwiches | 0.93 | 0.97 | 0.57 | 0.44 |
| Tacos | 0.78 | 0.75 | 0.83 | 0.59 |
| Salads | 0.67 | 0.92 | 0.65 | 0.50 |
| Donuts | 0.8 | 0.77 | 0.55 | 0.87 |
| Steak | 0.84 | 0.84 | 0.39 | 0.46 |
| Burgers | 0.84 | 0.87 | 0.77 | 0.59 |
| Bagels | 0.91 | 0.90 | 0.55 | 0.85 |
| Cupcakes | 0.75 | 0.81 | 0.74 | 0.93 |
| Fish & Chips | 0.87 | 0.77 | 0.89 | 0.74 |
| Burritos & Wraps | 0.79 | 0.67 | 0.47 | 0.66 |
| Hot Dogs | 0.76 | 0.73 | 0.54 | 0.90 |
| Crepes | 0.94 | 0.94 | 0.69 | 0.55 |
| Waffles | 0.89 | 0.89 | 0.49 | 0.88 |
| Pancakes | 0.69 | 0.79 | 0.38 | 0.83 |
| Nachos | 0.81 | 0.86 | 0.77 | 0.74 |
| Soups & Chowder | 0.7 | 0.71 | 0.47 | 0.69 |
| Ribs | 0.67 | 0.6 | 0.6 | 0.69 |
| Curry | 0.64 | 0.61 | 0.57 | 0.62 |
| Paella | 0.79 | 0.82 | 0.9 | 0.79 |
| Oysters & Mussels | 0.69 | 0.79 | 0.69 | 0.87 |
| Grilled Fish | 0.86 | 0.77 | 0.51 | 0.59 |
| Pasta | 0.65 | 0.53 | 0.55 | 0.85 |
| Chicken Wings & Fried Chicken | 0.81 | 0.83 | 0.57 | 0.56 |
| Dessert | 0.85 | 0.86 | 0.58 | 0.41 |
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job