Speeding Up Delivery With Merge Queues

-
Benson Pan, Software Engineer
- Jul 11, 2023
Merging code safely can be quite time consuming for busy repositories. A common method is to test and merge branches serially, and one at a time, in order to ensure the safety of the main branch. However, this method does not scale well when many developers want to merge code at the same time. In this blog post, you’ll see how we’ve sped up code merging at Yelp by creating a batched merge queue system!
Why Merge Queues?
In our blog post about Gondola, our frontend Platform as a Service (PaaS), we talked about the benefits of moving to a monorepo. As we onboarded more teams and developers into our monorepo, we experienced a bottleneck when integrating code changes (merge requests) during peak hours. Ensuring quick code delivery is important to us at Yelp, as it enables us to iterate quickly and ship fast. Whether it’s bundling JavaScript or running mobile builds, we wanted a system that could speed up all our repositories without changing the developer experience (DX).
We’ve traditionally run pipelines in serial to keep a clean main branch and prevent merge conflicts from happening. However, this does not scale well when many developers want to push code at the same time (we’ve observed our repo is busiest in the morning). As such, we’ve explored different ways to merge code while guaranteeing the same branch safeties.
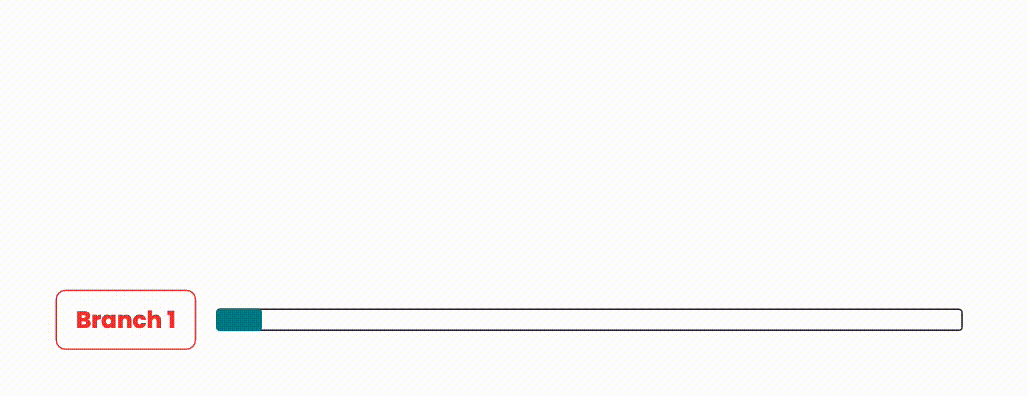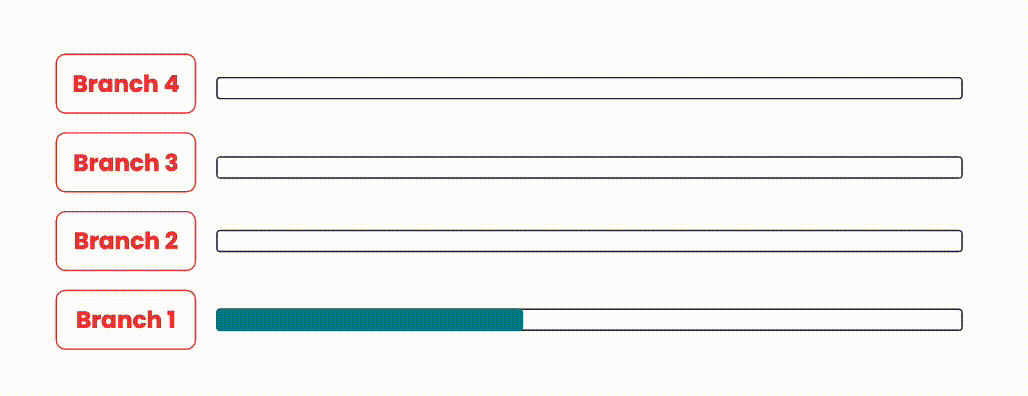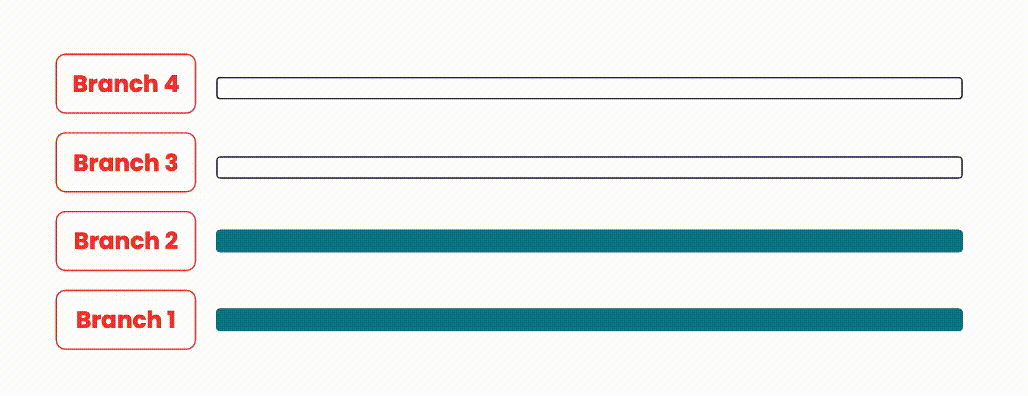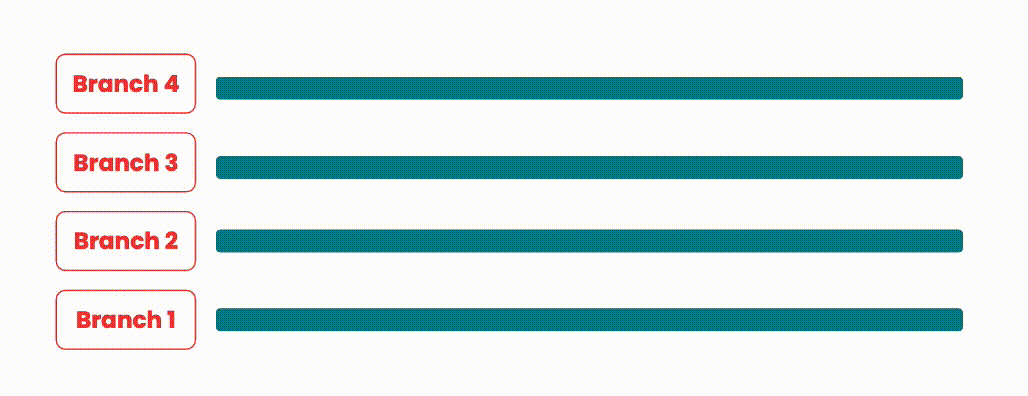
An illustration showing how branches were integrated traditionally.
Alternative Approaches
During our exploratory phase, a common method we saw to expedite code delivery was to run pipelines in parallel when merge requests overlap. The idea behind this approach is to merge any in-progress merge requests along with the new request in our pipeline. This decreases the time spent waiting between pipelines compared to merging in serial, while still guaranteeing merge safety. If a pipeline fails however, the merge request is removed and new pipelines are started for every merge request after the failing merge request, with the failing merge request now removed.
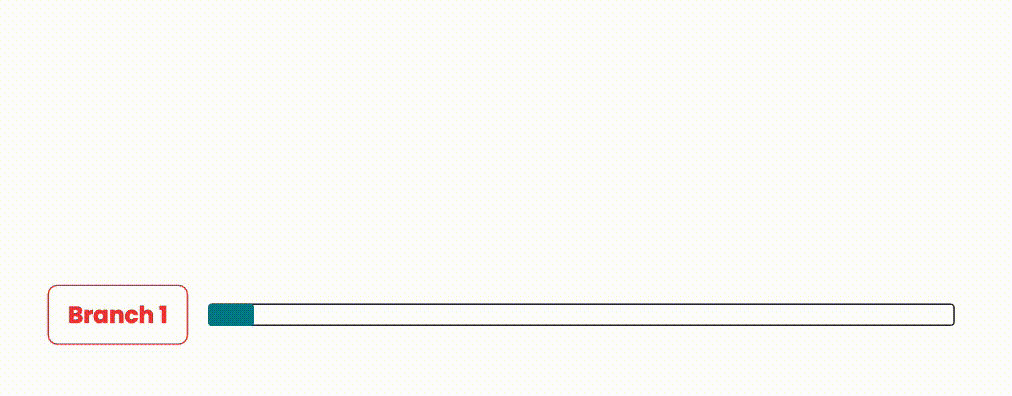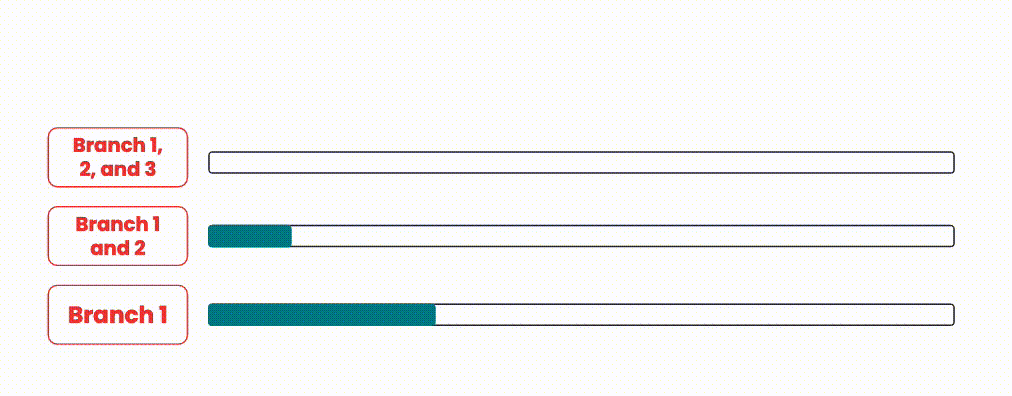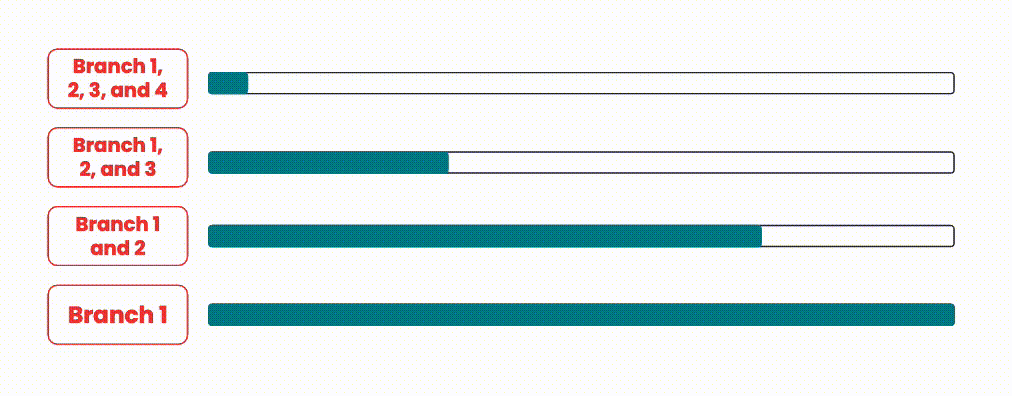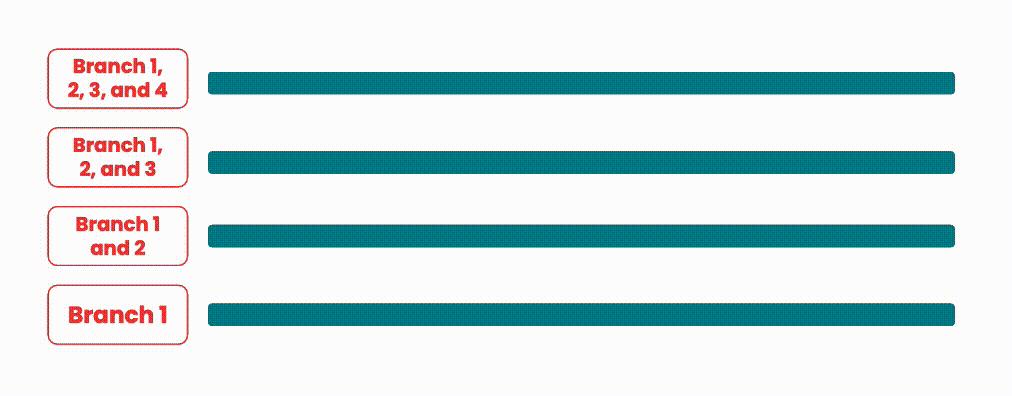
An illustration showing how branches could be integrated in parallel.
This approach is quite resource intensive, since for N branches/merge requests, there would be N pipelines running at the same time. On systems with shared/limited resources, this is a heavy burden to carry, as resource constraints may also negatively affect pipelines currently running.
Merge Queues
The merge queue strategy involves batching up merge requests into merge groups and integrating these merge groups sequentially. This approach keeps our resource usage low as we still run one pipeline at a time at most. However, instead of merging one merge request at a time we can merge in as many good, non-conflicting merge requests as possible.
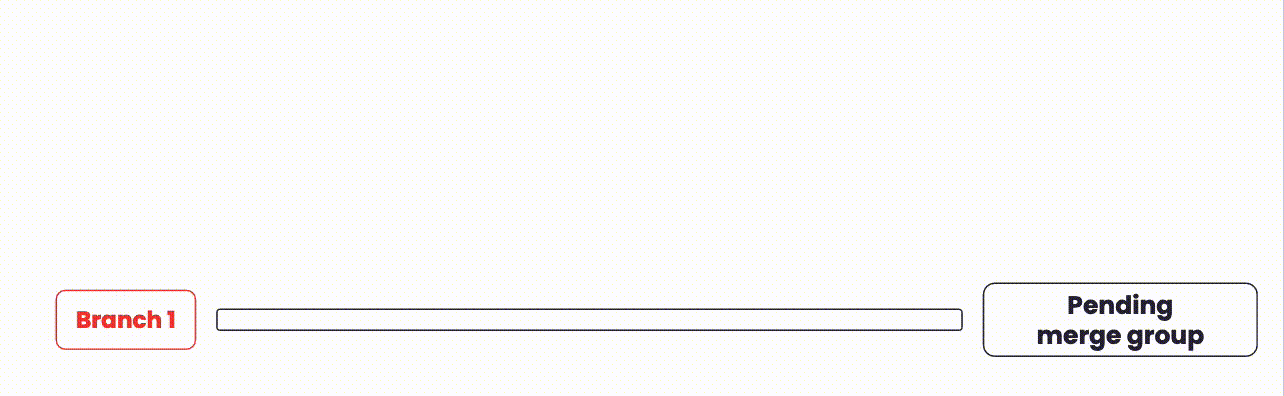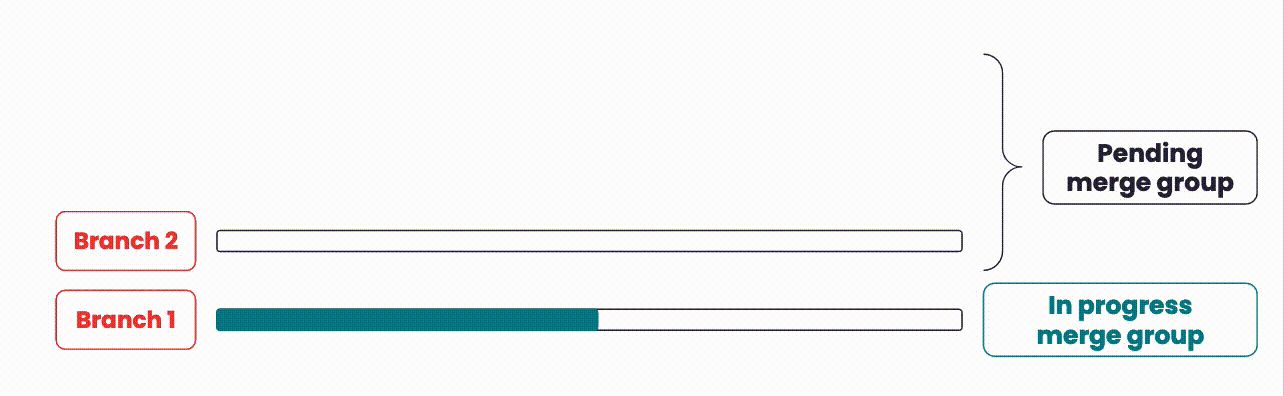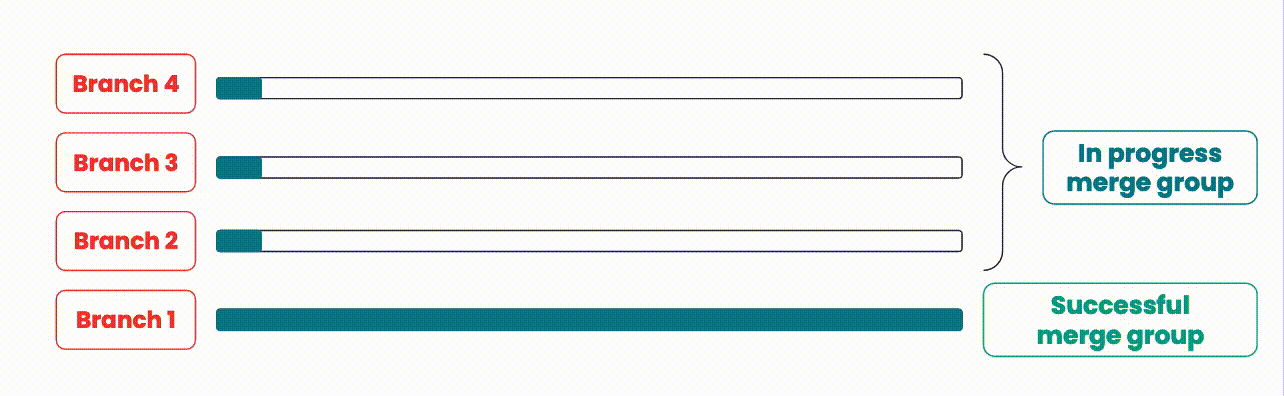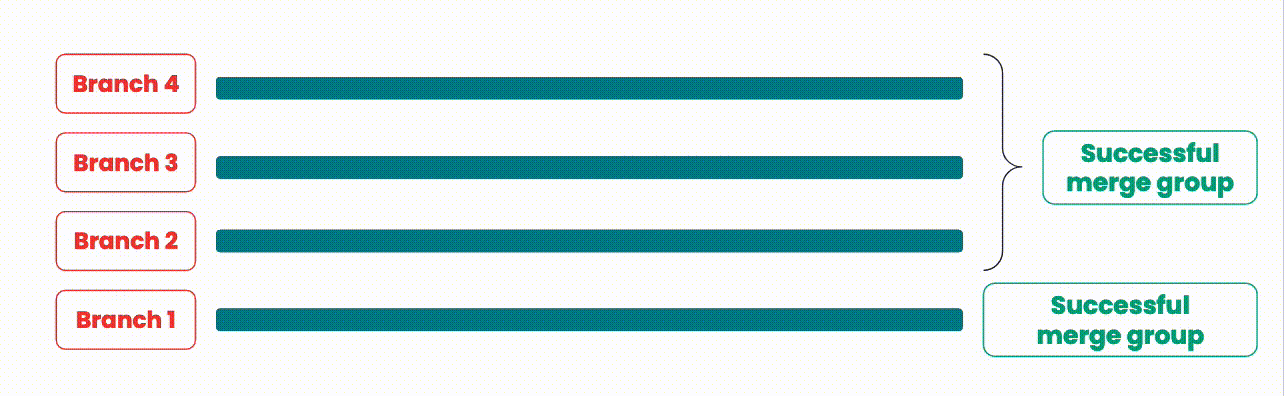
An illustration showing how branches are integrated with merge queues.
When a merge group fails, we perform a binary search to find the bad merge request(s) by splitting the merge group into two child merge groups. With this strategy, a child merge group that no longer contains any bad merge requests can merge its subset of merge requests all at once. However, if a child merge group continues to fail, we continue the binary search until we get a merge group of one merge request, which either passes or fails and does not split further.
To illustrate this we created the diagram below. We start with a merge group with six merge requests (labeled A to F), with one of them being unable to merge (labeled C). The first merge group A, B, C, D, E, and F on the left gets split because we are unable to merge C. The next merge group being evaluated contains merge requests A, B, C which gets split again. We are able to evaluate and merge in merge groups containing D, E, F and A, B afterwards. Eventually, we reach a point where there is a merge group containing merge request C, which fails to merge and does not get split into any child merge groups.
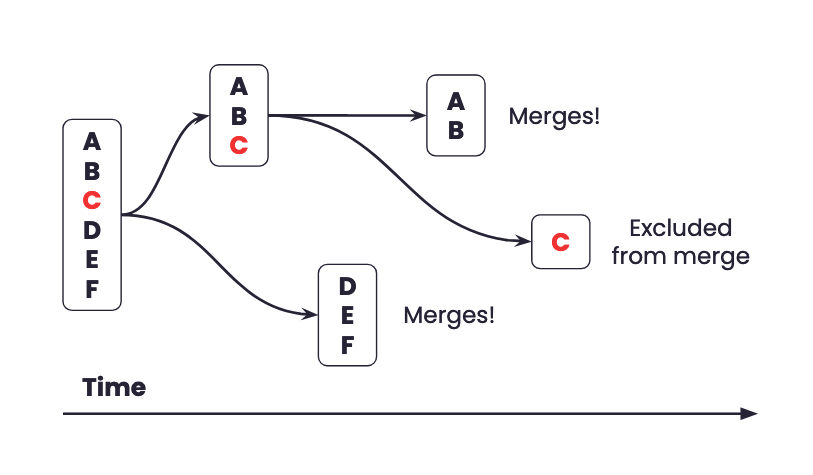
Example showing how a merge group of 6 merge requests are merged and split over time.
Implementation
For a bit of background, code delivery pipelines at Yelp start with a magic pull request comment, !integrate. This triggers a pipeline to perform common actions like merging code, running tests, and pushing upstream. With this in mind, we wanted the new system to preserve the developer UX, while still being flexible enough to rollout to any repo.
To create the merge queue, we began by building a new service that would execute the run loop. This service manages state/logic (such as merge group creation, splitting, etc.) and periodically checks if a pipeline should run for a subsequent merge group. In addition, we extended the !integrate comment logic to seamlessly replace the old workflow with this new approach. Repos can choose to use the merge queue by adding a config file that specifies which pipeline to run. The existence of this config file also indicates that the new magic comment logic should be used. As a result, the magic comment for this repo will direct a pull request to join the merge queue (after checking mergeability) instead of running a pipeline immediately.
In our delivery pipelines, most repositories follow 3 steps as mentioned earlier: merge, test, and push. To account for more complex repos, we allowed developers to perform additional actions before/after these standardized steps or replace them instead. This structure also helps standardize and simplify pipeline code for our repository owners as they onboard to using merge queues. With these changes, pipelines can continue performing necessary actions, while being managed by the merge queue to speed up previously sequential builds.
Conclusion
Implementing merge queues was a huge improvement from our serial integration pipeline. On the extreme end, we’ve even seen merge groups with over 10 merge requests merge in successfully! By using this system over the past year, our frontend monorepo had an average of about 1.2 merge requests per merge group. In a hypothetical world where a pipeline takes one hour to run, this translates to saving 12 minutes of developer time per pipeline run when compared to running pipelines in serial! For busy repos, which can easily have thousands of merge requests a year, those time savings can add up.
Acknowledgments
The merge queue project was a collaboration between Webcore and our talented Continuous Integration and Delivery team. Many thanks to the developers who’ve contributed to this project from idea generation to further optimizations.
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job