Gondola: an internal PaaS architecture for frontend app deployment

-
Joe Bateson, Software Engineer
- Mar 3, 2023
The Yelp website serves millions of users and business owners each day, and engineers in our product teams are constantly adding and improving features across hundreds of pages. Webcore, Yelp’s frontend infrastructure team, is always looking to ensure that web developers can ship their changes quickly and safely, without the burden of maintaining complex team-specific infrastructure.
To achieve this, we made some significant changes to our internal deployment model for React pages in late 2019. This blog post will explain why we made these changes, describe the new architecture we implemented, and share some of the lessons we learned along the way.
We ended up with an architectural model based on an immutable key-value (KV) store with clearly defined page boundaries: frontend asset manifests that can be hot-swapped quickly and safely in production. Alongside that platform layer, “Gondola”, we rolled out a new monorepo, solving many of the challenges we had begun facing as we scaled the number of feature teams and webpages across the site.
Status quo
Yelp’s website was originally served by a large Python monolith, and over time this has shifted towards a microservice architecture for backend services, allowing teams to maintain their own Docker images, deployment pipelines, and runbooks. This concept was then expanded to the frontend, which brought over frontend asset build configs (webpack, Babel, ESLint…) for teams to maintain. Webcore set up shared configs and CLI tooling to encode recommended best practices in order to ensure a consistent frontend build experience.
In this environment, each individual feature team at Yelp ended up owning one small “website slice”, from top to bottom. Full-stack developers on these teams would be responsible for their entire stack, encompassing both the frontend and backend as well as the linting, testing, and on-call responsibilities that came along with it. Even with the help of the shared Webcore-provided frontend infra tooling, relying on teams to keep the shared configs up to date wasn’t ideal - especially if certain frontend microservices had minor deviations.
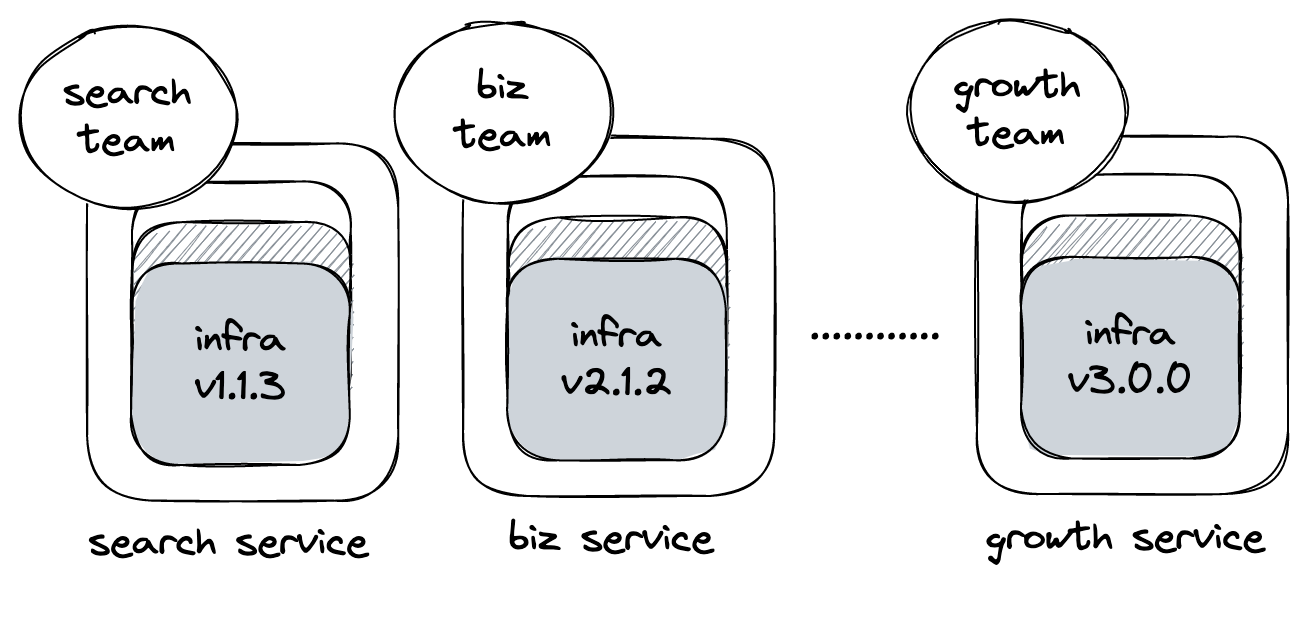
Our status quo model, where each team owns a potentially-fragmented piece of the website stack
As a result, we often saw a lag between releasing a new version of our shared build infrastructure and seeing its effects on the wider set of web pages. We’d sometimes even have cases where pages would be stuck on an old version of our tooling for months, and so it was difficult for Webcore to have confidence in infrastructure changes we released. Manually testing every frontend microservice wasn’t feasible because they often drifted from Webcore standards, resulting in custom deployment models and unique setups.
As we started moving to React and away from our Python-powered templating, it was clear that we were becoming less reliant on server-side logic. Much of our UI was starting to be described via React (rendered through Server Side Rendering), and our data fetching was moving to GraphQL on a per-component basis. Despite not needing anything other than simple data fetching and stitching on the server, developers would have to deploy a full Python service to make even a simple copy change or style update. This could sometimes take an hour or more for larger deployments when many instances were required, and rolling back or reverting changes could take a similar amount of time even for frontend-only updates!
A better model
When comparing our largest frontend microservices at Yelp, we could see that much of our existing infrastructure concerning the deployment of pages could be simplified. Large amounts of boilerplate code existed in order to fetch data, manipulate it into an appropriate form, and then send it off to be server-side rendered using a specified React component representing the whole page.
We also saw room for improvement given the fact that our services were now generally “thin”, since they delegate React SSR to an external service powered by Hypernova (something we published an updated blog post talking about recently). We imagined a new, centralized service containing generalized logic built to serve all web pages at Yelp. Essentially an internal Platform-as-a-service for React pages!
Our service, “Gondola”, had the following requirements:
- Deploying and rolling back frontend code should be near-instant
- Deployment of assets should be decoupled from the Python code powering Gondola
- The service should contain minimal page-specific logic: all page behavior should be described by the rendered React components
- Teams should only be required to own product code, not infrastructure, and ownership should be clearly defined
Our first step was to reduce the scope of team ownership from a microservice (the “full website slice”) to a “page”. A Gondola page can be defined as an asset manifest describing all JS and CSS entrypoint files that we need to include in order to fully describe a desired UI, along with appropriate chunk names (including async chunks) mapped to public CDN urls for each asset. It gives us a way to fully describe each page’s frontend needs and can be generated at build time by webpack:
{
"entrypoints": {
"gondola-biz-details": {
"js": ["gondola-biz-details.js", "common.js"],
"css": ["gondola-biz-details.css"]
},
"gondola-search": {
"js": ["gondola-search.js", "common.js"],
"css": ["gondola-search.css"]
}
},
"common.js": "commons-yf-81b79eb1bc6d156.js",
"gondola-biz-details.js": "gondola-biz-details_a775bc492d91960a.js",
"gondola-biz-details.css": "gondola-biz-details_eabd4c9f434f9468.css",
"gondola-search.js": "gondola-search_69082d627b823fd5.js",
"gondola-search.css": "gondola-search_d0ef76f21dcbf11d.css"
}
This choice was very deliberate, as it allows us to embrace the web platform (with URLs at its core) as the primary building block for routing, bundling, and deploying code to yelp.com. This simplified many decisions in the rest of our design once we had settled on this level of granularity as our main abstraction.
We then took our existing Pyramid React renderer (a Pyramid renderer designed to take props from Pyramid and produce a rendered SSR page via React), which was built for individual teams to use in their services, and tweaked it to work alongside a fast KV store powered by DynamoDB. In our database, we store our page manifest data keyed by Gondola page version, and in a separate table track the active Gondola page for a given path (we use the commonly-adopted path-to-regexp format for matches here).
All interaction with our KV store is performed via a small CLI tool we distribute across our development environments (including Jenkins) which talks to DynamoDB in a consistent schematised way. The Gondola service itself only requires read-only access to the database so that it can serve the appropriate pages as requests come in.
This means that the flow for an incoming request to Yelp looks as follows:
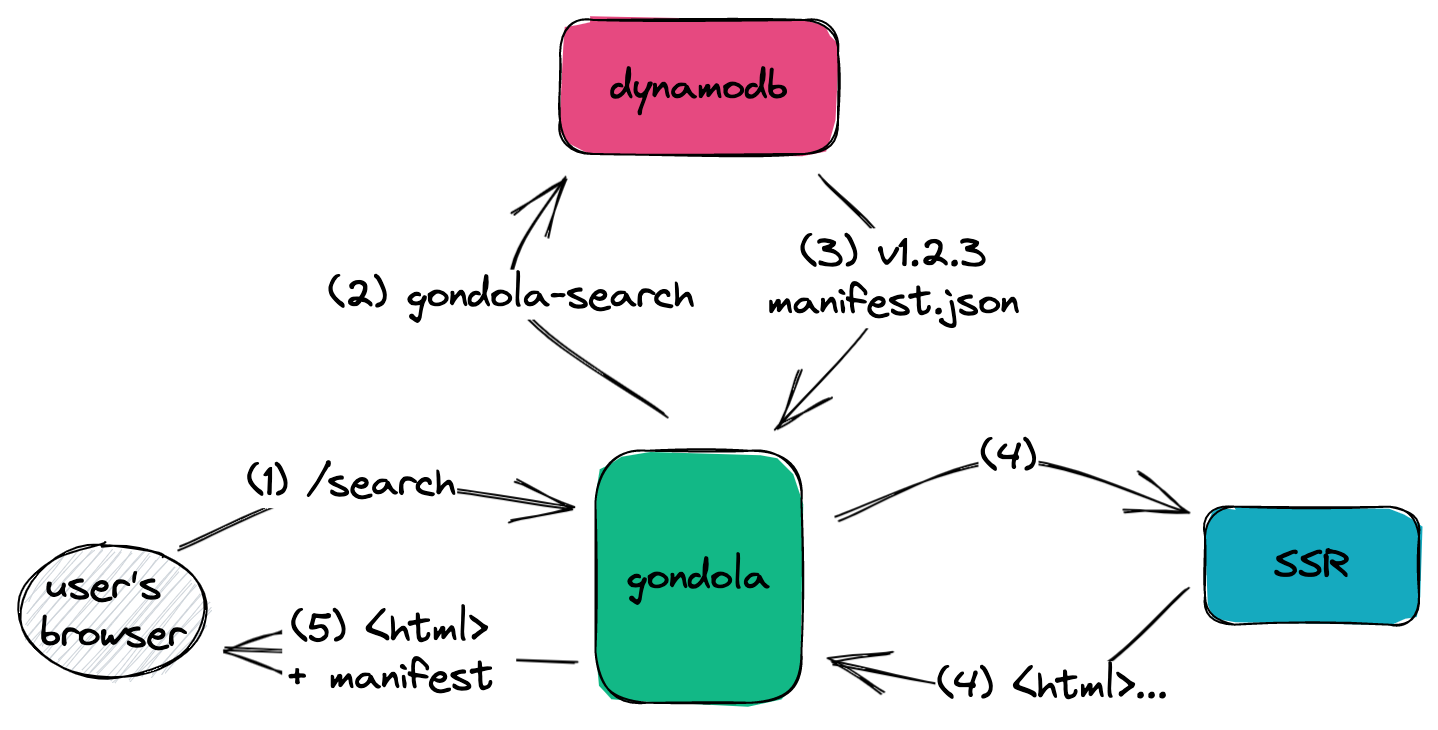
An incoming request hitting the Gondola service to render the Search page
- A user requests a Gondola-powered page such as /search - this goes directly to Gondola, and matches the route via path-to-regexp
- Gondola queries DynamoDB to determine the active version for /search, and the accompanying asset manifest for that version
- A query is made to our dedicated Server Side Rendering (SSR) service which returns rendered html
- The appropriate asset tags from the manifest are included in the page shell to hydrate the page
By basing the rendering of the page entirely on the contents of the page manifest, the Gondola service has a lot of flexibility: this model supports our first requirement of near-instant deployments, since “deploying” a Gondola page now consists of updating a single version row in our DB. This assumes you’ve built and uploaded your assets and manifest, but this can happen at any time beforehand: creating a new Gondola page version isn’t tied to deployment.
This means that our merge pipeline becomes a lot safer. The only thing that can affect production is the DB being updated to flip active versions, and the version can be instantly reverted in the same way if we spot errors during rollout.
The nature of the KV store model also lends itself to cacheability: a given page and version pair is immutable, and we can serve manifests very efficiently from an in-memory cache layer without needing complex cache invalidation.
Centralized updates
One of the most important benefits to this model is that Webcore now has the ability to make changes to all Gondola pages at once, and introduce significant UX and DX improvements across all pages with ease. For example, we can add new metrics to our performance logging infrastructure centrally, or optimise our first-byte times for all pages with a single Pull Request.
In a world where teams maintain their own frontend microservices, we don’t have the ability to make sweeping changes. This would require either a large amount of onboarding and education or Webcore-lead migrations to get everyone onto the latest and greatest libraries containing any improvements we ship out. This comes with its own set of dependency versioning challenges and is generally no fun for anyone.
Deployment Previews
Another win for this model is the ability to add additional logic around the hot-swapping of frontend versions: as one important example, it allows us to implement Deployment Previews internally, where we can tag specific versions as pre-release and view them against the production website instantly via a query param.
A deployment preview model naturally fits with our routing behavior above. Deployment Preview IDs (using memorable and fun names like cool-purple-hippo-24!) can slot in anywhere that versions are used, and the logic remains almost identical.
While not a novel feature in the wild across most modern static site hosts, the existence of Deployment Previews internally allows for:
- Realistic demos against prod data rather than relying on persistent sandboxes or screenshots
- The ability to quickly compare two versions against the same environment, including unreleased versions
- Audits and automatic smoke tests run on every PR, against the Deployment Preview url
The last point is something that has a great deal of potential in the future, too: we already have several “Page Checks” which run Lighthouse performance audits, checks for console errors or JS exceptions, A11y audits, and automatic screenshots. All of these checks can be run at PR-time without the developer having to do anything, and results are reported back via Github status checks conveniently:
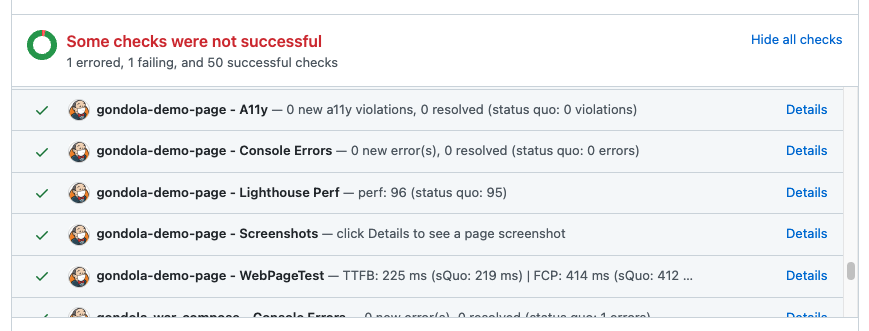
Example Page Checks running against a branch’s Deployment Preview at PR time
This all hinges on our ability to switch out the running version of a page near-instantly in any environment, made possible by Gondola. There are likely also lots of other opportunities that we’ve yet to explore which are unlocked by this newfound freedom!
The Monorepo
In addition to our work to build out the Gondola service, we needed a pipeline to ferry changes between a Pull Request, asset manifest, and our DB, so that they can subsequently be deployed.
Our status quo was a loose collection of team-owned Jenkins pipelines spread across many different individual git repositories. This was never ideal due to the reasons outlined earlier on, but the rethinking of our deployment model gave us a great opportunity to do something about our package dependency model. The result was a new monorepo for frontend code.
By moving to a monorepo, we sought to solve some of the largest problems that had been frustrating developers previously:
- No more “dependency hell” - updating a monorepo package version automatically releases a new page if the package is directly or transitively depended upon, and packages are enforced to only depend upon the latest version on disk
- It’s easier to reason about the dependencies that will be bundled in the final page
- We can also globally enforce a deduplicated lockfile to minimise our install and build times
- No backend infrastructure to maintain: we’ve moved all of that to the Gondola service, so the monorepo can be 100% frontend code
- Any improvements to the build immediately benefit all developers, with no need for migrations - all build infrastructure and tooling is shared and maintained by Webcore, and any changes can be easily confirmed to work in the monorepo
- Faster, more efficient bundling: since all pages and packages live together, we’re able to run a single Webpack build with multiple entry points, and utilize granular chunking strategies that can take advantage of cross-page shared chunks
To avoid the growth of the monorepo slowing down developers, we built and continue to maintain tooling to run tests only against packages that have been affected by the PR in question (we use lerna with additional custom scripts). This was and is one of the biggest concerns that tends to appear when discussing monorepos, and it’s important that we stay on top of build performance to ensure that we’re not frustrating developers.
We also enforce strict package boundaries and require that each package in the monorepo has a defined owner. We provide a helpful scaffold to make this process simple when first adding code to the monorepo, which has helped significantly with onboarding.
Developers, developers, developers
A major part of the work involved with Gondola was to ensure that developers could be onboarded with minimal disruption. A lot of this work was non-technical: we felt it was important to involve our customers (in this case, internal front-end developers) as early as possible in the design process and make sure that what we were building was actually useful for them! Writing docs as we went and pairing with early adopters directly helped mitigate a vast swathe of potential problems which we may not otherwise have discovered.
In our case, since we were asking developers to change some of their pre-established patterns of working on frontend code, we sought to maintain as much familiarity as possible with our tooling decisions. As one example, at Yelp we use Make as standard in all repos, so it was important to ensure that a developer opening up the monorepo for the first time would feel at home. We set up symlinked Makefiles per-package to ensure that running commands from within a package would feel close-to-identical to the old flow.
We also set up a dedicated docsite with an in-depth migration guide, and provided clear iterative steps: specifically in our case our emphasis was on the fact that step one would involve moving frontend code to the monorepo without the requirement that they move to Gondola. This made it easier for teams to tackle the migration at their own pace without the need for any “big bang” rewrites.

Part of our dedicated Gondola migration guide written internally for developers
Supporting legacy data fetching
While GraphQL is our primary supported data fetching method at Yelp, there are still some services which continue to fetch their data via Python. Since we don’t expose the Python backend to Gondola users, this poses a problem: how can we allow developers to onboard onto Gondola without requiring them to take on an additional GraphQL migration?
We solved this by building a custom Pyramid renderer we call the “Gondola Legacy Renderer”: it’s designed to be plugged into any existing service, and fire off a request to Gondola with an additional set of “legacy props” passed via GET request body internally. This means that we unlock the ability for any existing service to become a proxy for Gondola itself, gaining the majority of benefits of a “real” Gondola page while teams complete their migration to GraphQL.
Several teams have adopted the Legacy Renderer and we’re pleased with its ability to bridge the gap for developers who otherwise may not have had the bandwidth to start migrating away from dedicated team-owned services.
The future
With Gondola, we aimed to build a platform for all of Web at Yelp: we wanted to introduce a large shift in our mental model of deployment and question some of the existing assumptions we had about what was feasible to design.
So far, we’ve seen positive signs from our customers that our approach was successful. The majority of Yelp’s web traffic is now served by Gondola, but there’s lots more to do: the Gondola platform can never really be “finished”, so we continue to roll out and improve core features and take into account feedback from web developers across the company.
As teams continue to onboard, we’ve introduced optimistic build queues, started incrementally adopting fast rust-based tooling like swc in critical areas, and continue to implement Page Checks to provide assurance that PRs created against Gondola meet the company’s web performance goals. There’s also room for exciting new Deployment Preview integrations and ways to improve our DX for all developers.
With releases like React 18 and its support for streamed SSR responses, our ability to make sweeping changes across the monorepo (and by extension all Gondola pages at Yelp) gives us confidence that we can perform this and other large migrations in ways that stay out of feature developers’ way: something that’s critical to ensure we’re not negatively affecting deployment velocity while embracing industry best practices.
Conclusion
The creation of Gondola itself was years in the making: the journey from our legacy Python/jQuery templates, to React, to GraphQL, and finally to the monorepo model did not happen overnight. It was important to iterate gradually with immediate benefits gained at each stage - rewrites should always be avoided!
By simplifying and slimming down our deployment model, we’ve been able to introduce features that were impossible before, removing a large amount of cognitive overhead from feature devs who shouldn’t be required to maintain their own website stacks top-to-bottom.
It’s been exciting and encouraging to see the positive response from developers, as well as the amount of support we’ve had from all our internal customers! There’s a lot more we want to get done, but Gondola serves as a great platform for us to do it, and the future of web development is looking exciting at Yelp.
Acknowledgements
Gondola wouldn’t have been possible without the input from many teams and individuals across the company. Thanks go out to current and past members of the Webcore team, the many contributors to Gondola’s codebase and docs, as well as the initial spec reviewers from our product teams that helped turn the idea into reality.
Additional thanks goes out to all the developers in our web tech community that work every day with the platform and offer us honest and direct feedback that helps us shape Gondola’s roadmap!
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job