Coordinator - The Gateway For Nrtsearch

-
Luana Fragoso, Sarthak Nandi and Swetha Kannan, Software Engineers
- Oct 6, 2023
While we once used Elasticsearch at Yelp, we have since built a replacement called Nrtsearch. The benefits and motivations of this switch can be found in our blog post: Nrtsearch: Yelp’s Fast, Scalable and Cost Effective Search Engine. However in this blog post, we will discuss the motivations behind building Nrtsearch Coordinator - a gateway for Nrtsearch clusters. We will also go over how Nrtsearch Coordinator adds sharding logic to Nrtsearch, handles scatter-gather queries, and adds support for dark/live launching cluster improvements.
Motivations
We traditionally used a gateway to call Elasticsearch, which provides metrics, isolation rate-limiting per client, and geo sharding, and it also eases Elasticsearch upgrades (see Yelp’s Elasticsearch-based Ranking Platform - Indexing and Defense Mechanisms for more details). However, we couldn’t use the same gateway for Nrtsearch for a few reasons:
- It was using the Hystrix library for rate-limiting and isolation which has been deprecated for a while.
- It was running on Java 1.8 since Hystrix is not supported on newer Java versions.
- It exposed a REST API with JSON while Nrtsearch uses gRPC and Protobuf. Converting the Protobuf messages to JSON would make the responses much larger and harder to parse for clients.
- It was built for geo sharding but we needed to shard the data using multiple strategies.
- It used a cassandra-based system instead of our more recent Flink-based Elasticpipe for indexing.
We considered modernizing the gateway and supporting the required features, but it would have required a lot of changes in the gateway and also in existing applications. Instead we decided to build Nrtsearch Coordinator to address all the issues with the previous gateway. It runs on the latest Java version, uses gRPC and Protobuf, and also has more required features. These features are discussed in detail below.
Features of Nrtsearch Coordinator
Sharding
Nrtsearch clusters have a single primary (which does all the indexing) and multiple replicas which serve search requests. The replicas start up by downloading a copy of the index from S3, and then connect to the primary to get the real-time indexing updates. We also have the replicas keep the docvalues (column-based per-field data structures that are read sequentially) for the entire index in memory using OS disk cache for faster retrieval for search requests. This design presents two challenges:
- Index size is limited by the amount of memory we can get in an instance. Larger instances are also more expensive.
- Replicas will require more time to bootstrap the larger an index is – since the download from S3 will take longer – increasing the time it takes to scale up the number of replicas when there is an increase in search traffic.
While these challenges won’t present issues for small indices (sized in 10s of GBs), they will for larger indices (100s of GBs). This is a typical problem faced by databases since data size can easily grow beyond the space available on a disk. Databases typically “shard” (create chunks of) large amounts of data and distribute them across multiple nodes so that each node has a manageable data size. The Nrtsearch Coordinator allows us to do the same for Nrtsearch, but instead of distributing data across multiple nodes in a cluster, we do it across multiple Nrtsearch clusters. We call this logical grouping of clusters a “cluster group.”
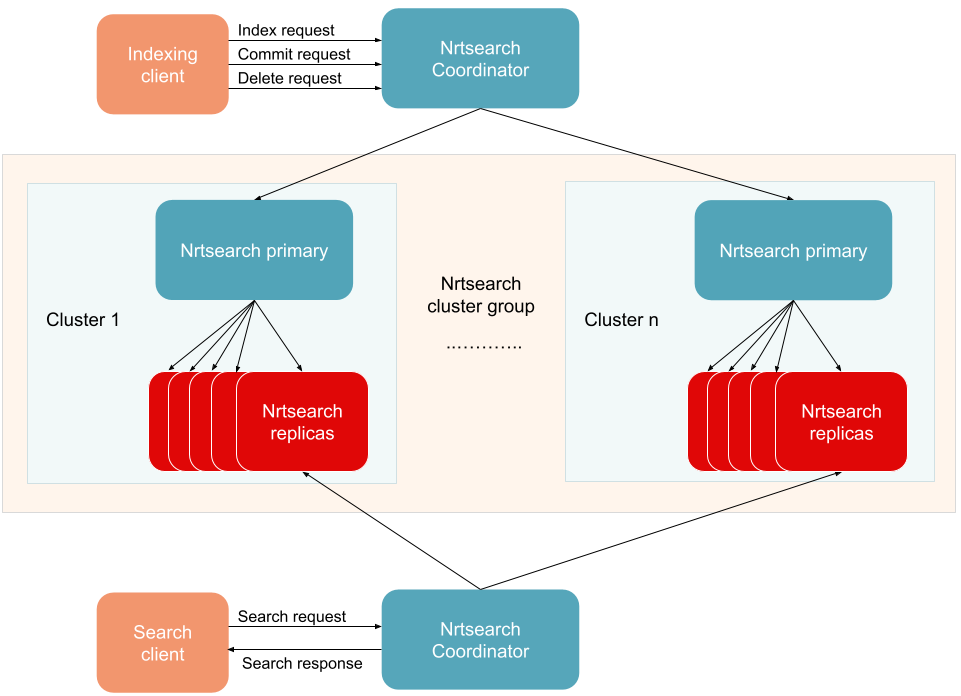
Interactions between Nrtsearch primaries and replicas of clusters in a cluster group, and Nrtsearch Coordinator
We can easily create the required number of Nrtsearch clusters, and then Nrtsearch Coordinator will direct both indexing (including add document, delete and commit requests) and search requests to the right clusters. All of these requests include a sharding parameter object which contains the required information for Nrtsearch Coordinator to send the request to the right cluster. Nrtsearch Coordinator also needs a sharding configuration which defines how the sharding will be performed. The information within the sharding parameter and the required configuration will depend on the type of sharding being used:
-
ID sharding
ID sharding simply takes the mod of an integer by the number of clusters/shards and can index the data in the cluster or search for data in a cluster. While the name implies that the integer must be an ID, it may or may not be the document ID. The sharding configuration needs to map the numbers 0 to n-1 (where n is the number of Nrtsearch clusters) to Nrtsearch cluster and index name. Example ID sharding configuration:
clusters_to_indices: 0: cluster_1: index_name_1 1: cluster_2: index_name_2 2: cluster_3: index_name_3 -
Geo sharding
With geo sharding, the data in the same region is stored in a single cluster. The sharding parameter may contain a geo point (latitude and longitude) or a geo box (two geopoints representing opposite corners of a rectangular area). The sharding configuration needs to contain a mapping from geo box to a Nrtsearch cluster and index name. A request will be mapped to an Nrtsearch cluster if the point or box are contained in its corresponding geo box. We add some fudge factor to index businesses that are at the boundary to keep the search behavior consistent. Example geo sharding configuration:
geoshards: - index_name: west_americas cluster_name: search_west bounds: min_latitude: -90.0 max_latitude: 90.0 min_longitude: -170.0 max_longitude: -100.0 - index_name: east_americas cluster_name: search_east bounds: min_latitude: -90.0 max_latitude: 90.0 min_longitude: -100.0 max_longitude: -30.0 -
Default sharding
This implies that we are only using a single Nrtsearch cluster and not sharding the data. The sharding parameter need not contain anything while the sharding configuration needs the single Nrtsearch cluster and index name. Example default sharding configuration:
cluster_name: search index_name: business_v1
We select one of these sharding strategies:
- If the index size is small enough to fit on a single cluster use default sharding.
- If the index is large, can be split by location, and every search query only has a single geo area use geo sharding.
- Use ID sharding for everything else.
When sharding data, databases generally try to split the data evenly across all shards. Queries are fanned out to all shards and then the results are combined. As you can see with ID sharding (unless using document IDs as the sharding parameter) or geo sharding, there is no guarantee that the data will be evenly distributed across Nrtsearch clusters. These sharding strategies can only be used with search queries that access a single shard. Say you have a geo shard for the Eastern U.S. and you have a search request that only needs results within the area of New York. You can direct the search request to the New York shard by setting the sharding parameter to the geo box containing New York. In addition to that you can also add a geo bounding box to the query to limit the results to New York.

Geo sharding example
This works with ID sharding too. You can search over all reviews of a single business by ID sharding on business ID instead of review ID. Also since we run Nrtsearch on Kubernetes we can individually set the resources for primaries and replicas in each cluster, and also the number of replicas. For example:
- If a cluster has a small index we can set it to have less memory.
- If a cluster has only a few updates we can reduce the CPU on the primary.
- If a cluster receives more traffic than other clusters, its replicas can scale up and service the traffic. There is no need to increase the number of replicas for other clusters.
All we need is that the index sizes on each cluster are small enough that the docvalues fit in memory and that Nrtsearch can download the index and startup within a few minutes. But if your search query requires searching over all data across multiple shards, we can ID shard on the document ID to have all data evenly spread across all clusters and use scatter-gather.
Scatter-Gather
Nrtsearch Coordinator also supports scatter-gather, in other words, it can fan out search requests to all clusters and combine the responses for use-cases where we cannot apply application level sharding logic. This can be used with any type of sharding but is best used with ID sharding using document ID in the sharding parameter to evenly distribute the data and also search load.
Processing a search request this way enables parallel processing and improves performance for searches over huge datasets contained in a cluster group. Consider an Nrtsearch index that contains reviews and is sharded by review ID. Scatter-Gather can be used to query all reviews containing the word pizza across all clusters. In this case we can send the same query to all the clusters and combine the responses to rank them accordingly.
We implemented scatter-gather to distribute an incoming search request across multiple clusters using multi-threading to invoke all the search tasks in parallel and with appropriate timeouts to process the request. Nrtsearch Coordinator acts as a collector for these individual search responses. All the logic needed to merge and sort these responses are built into Nrtsearch Coordinator. This requires scatter-gather to be performant to take advantage of Nrtsearch’s high performance searches on each cluster.
The Nrtsearch Coordinator merges the responses as they are received. The hits are ranked either according to the relevance scores or the query’s sort field type. We use a heap data structure to merge the results and to retain the top N document IDs requested by the client. Currently if any request to a cluster errors out we return an error in the response. Support for partial responses is discussed in the future work section.
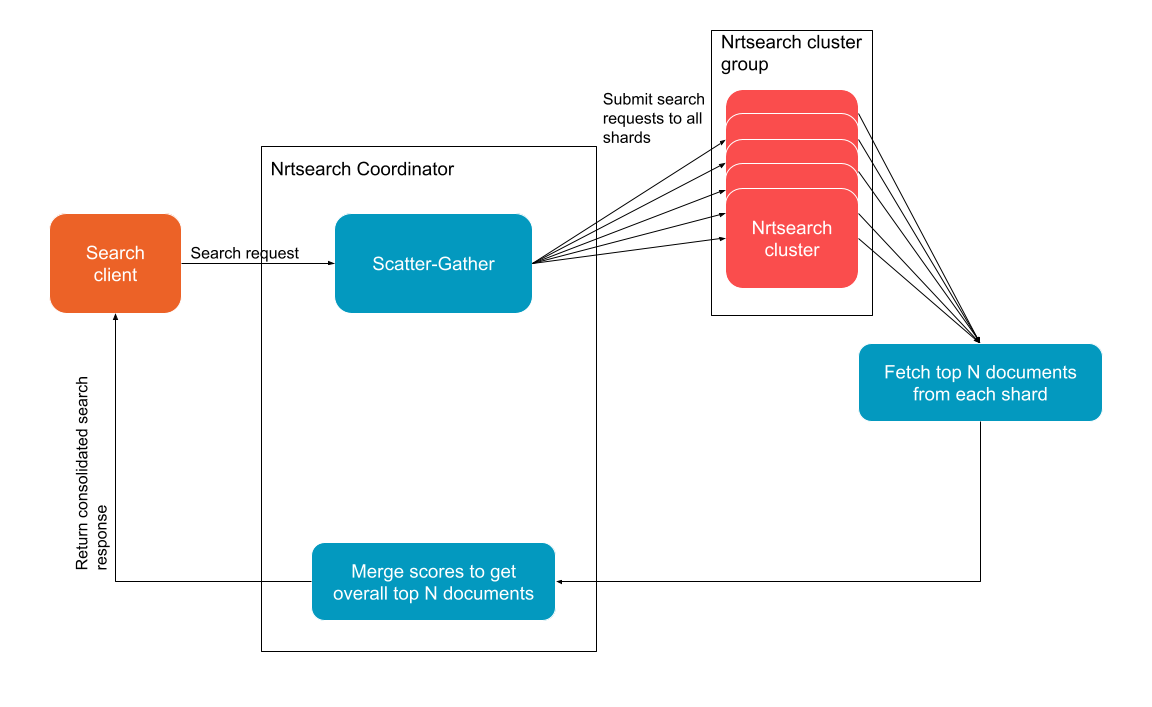
Nrtsearch Coordinator Scatter-Gather feature
An Nrtsearch search response contains the hits results, search diagnostics, collector or aggregation results and several other metrics and information about the search query that is processed. All of these fields are merged accordingly to enrich the combined search response with all the useful information.
When aggregations such as Terms aggregation are requested, Nrtsearch uses collectors to get results from individual segments of an index and a reduce logic computes the aggregations per cluster. If topN results are requested, for example, we get the topN from each shard to combine and sort the individual responses. We use a query-and-fetch approach here instead of query-then-fetch since we did not experience any latency concerns for our current use cases. However in the future, we plan to implement a query-then-fetch approach to handle large search requests to clusters with a higher number of shards. For search clients that require higher accuracy when dealing with imbalanced shards, we will be fetching more than the requested number of results from each shard so that the final topN results have the highest accuracy and relevance.
In Nrtsearch Coordinator, we recursively process the results of these collectors and the nested collectors within them to merge the responses. These results are then ordered and processed using a priority queue to have top buckets of certain size in the final aggregation result.
Slow query logging
Some search requests can take too long to be processed, which can cause timeouts in the Nrtsearch cluster. The reasons why the query could not be processed within a reasonable time may vary from queries that require ranking a large number of documents, to a lack of resources in the Nrtsearch cluster. We log these slow queries along with the time taken to understand the root cause behind the slow processing time. The slow query is logged in Nrtsearch Coordinator because sharding is not part of Nrtsearch. It would not be possible to investigate a sharding problem if we were logging the slow query through Nrtsearch instead of Nrtsearch Coordinator.
It is important to note that the information in the slow query log does not contain any sort of sensitive information that could harm users’ privacy. The term “slow” is subjective and configurable in the Nrtsearch Coordinator configuration file. This is an example of a slow query configuration:
queryLogger:
defaultStreamName: all_slow_queries
timeTakenMsToLoggingPercentage:
# 1% of the queries that took more than 150ms but not more than 350ms
# will be logged into the default all_slow_queries stream
150: 0.01
350: 1.0
timeTakenMsToStreamName:
# 100% of the queries that took more than 350ms will be logged in the
# stream name defined below instead of all_slow_queries
350: slow_queries_over_350_ms
# fields that should be skipped when logging a search response/request
sensitiveFieldsInSearchResponse: [response_sensitive_field]
sensitiveFieldsInSearchRequest: [request_sensitive_field]
Dark and live launch
Many changes on Nrtsearch clusters are only infrastructural and not behavioral. For such infrastructural changes, we look for the following:
- Client code should not require any changes.
- The new cluster group should return the same response.
- The response from the new cluster group should not be slower than the status quo cluster group.
Dark and live launches (also known as blue-green deployment) are a great way for developers to safely test a new Nrtsearch cluster group by slowly shifting incoming traffic to the new cluster group. A comparison between the responses from the status quo and the new cluster groups is very useful to build confidence in the new cluster group behavior before actually serving live traffic to it, avoiding any negative impact on the clients.
Nrtsearch Coordinator is a good place to add the dark/live launch features because it already routes requests to the proper Nrtsearch cluster based on the sharding parameters. Dark/live launches also route requests to the proper Nrtsearch cluster group, but based on a traffic percentage. Having this logic in Nrtsearch Coordinator instead of client services also means that any client using Nrtsearch Coordinator during a dark/live launch would have the new Nrtsearch cluster changes without the need of any change on the client side.
All of the traffic percentage and launch type (status quo, dark launched, and live launched) definitions are configurable in the Nrtsearch Coordinator configuration file. Currently, dark/live launches only work for search requests. We can define the different types of launches as follows:
- Status quo - Status quo is the cluster group that Nrtsearch Coordinator currently sends all search requests to.
- Dark launch - Dark launched cluster groups are the cluster groups that we want to test in a way that does not have any user impact. Dark launching should not affect the status quo response in any way, including the content or timings. To achieve that, Nrtsearch Coordinator sends any search request to the status quo AND the dark launched cluster groups. Only the search response from the status quo cluster group is returned to the client. In more detail, the same request is first sent to and processed by the status quo cluster group. Then, the same request is sent to the dark launched cluster group, but in a different thread such that the response from the status quo cluster group is not blocked and it can be returned right away to the client. As a result, we can keep track of both the status quo and the dark launched cluster group responses for the same request. These responses and the search request are logged so that we can later compare if both cluster groups behave the same (more in Comparison Report section).
- Live launch - Live launched cluster groups are cluster groups that usually went through a dark launch first and can now be gradually exposed to users. When live launching, Nrtsearch Coordinator sends any search request to the status quo OR one of the live launched cluster groups. The response from the selected (status quo or live launched) cluster group is returned to the user. Since the same request is not sent to both the status quo and the live launched cluster groups, we do not have a comparison log similar to what we have during dark launch.
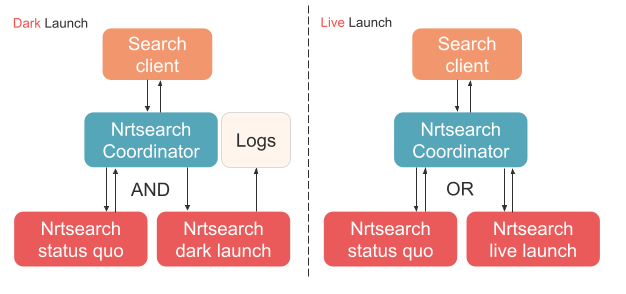
How dark/live launch works in Nrtsearch Coordinator
Besides defining the status quo as well as the dark/live launched cluster groups, Nrtsearch Coordinator also needs to know by how much it should route the search traffic to these cluster groups, which can happen from 0% to 100%. A common dark/live launch flow looks like the following:
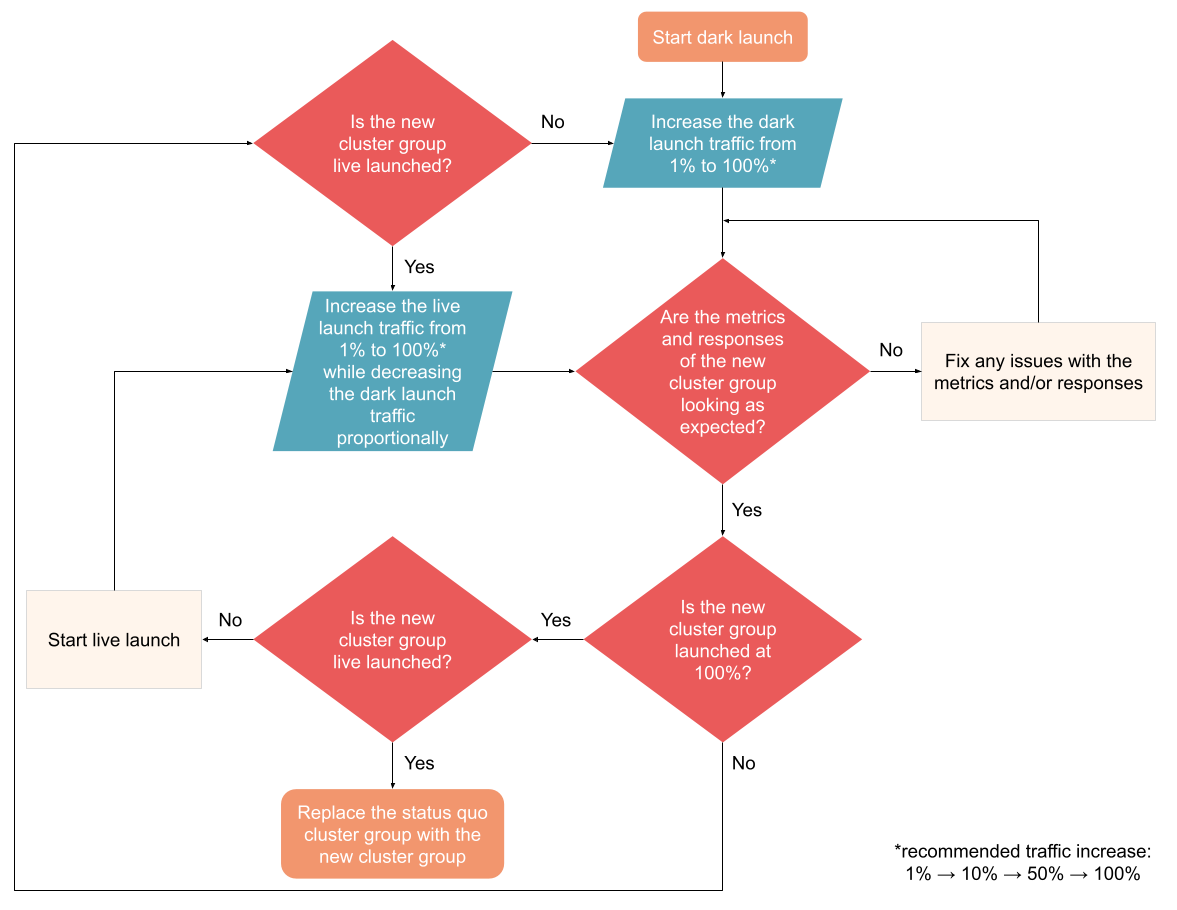
Dark/live launch flow
Comparison report
We developed a comparison report tool with the purpose of facilitating the comparison of Nrtsearch search responses between the status quo and dark launched cluster groups. Since we log the status quo and dark launched responses for the same request, we can use these logs to check the behavior of the dark launched cluster group against the status quo. Each line in this log contains the search request, the search response of the status quo, and the search response of the dark launched cluster groups. The comparison report tool uses this log to compare the responses and generates a summary of the comparison, by checking the response equality in the following order: total hits → hit fields that are ids → remaining hit fields → hit scores. The complete Nrtsearch response structure can be found here. This is how the comparison report summary looks like:
----- COMPARISON REPORT SUMMARY -----
Dark launch cluster group: test-cluster-group
Total log lines compared: 293
Number of error messages: 15 (5.12% of total log lines)
Number of matching responses: 178 (60.75% of total log lines)
Number of mismatching responses: 100 (34.13% of total log lines)
-- Total hits mismatch stats --
Number of mismatching total hits: 70 (23.89% of total log lines)
Total hits average difference: 60
-- Top hits mismatch stats --
Number of mismatching ids: 7 (2.39% of total log lines)
Number of mismatching fields: 23 (7.85% of total log lines)
Number of mismatching scores: 0 (0.00% of total log lines)
Comparison report saved at nrtsearch_coordinator/generated/comparison_reports/comparison_report_20221109-155500.txt
The comparison report is a command line tool that is part of the Nrtsearch Coordinator repository. While this tool could have been released separately from Nrtsearch Coordinator, we thought of deploying it together to avoid installing and deploying it in different environments. It also makes sense to deploy the comparison report tool and Nrtsearch Coordinator together because the comparison tool is highly coupled with the dark launch log formatting, which is defined in Nrtsearch Coordinator.
Future work
- Support pagination, partial responses and combining facet results in scatter-gather
- Translating coordinator requests to work with API changes in nrtsearch to avoid changes in clients
- Add more sharding strategies which work better for a variety of use-cases
Acknowledgements
We would like to thank all current and past members of Ranking Infrastructure team at Yelp who have contributed to building Nrtsearch Coordinator including Andrew Prudhomme, Erik Yang, Karthik Alle, Mohammad Mohtasham, Tao Yu, Ziqi Wang, Umesh Dangat, Jedrzej Blaszyk and Samir Desai.
Become a Data Backend Engineer at Yelp
Do you love building elegant and scalable systems? Interested in working on projects like Nrtsearch? Apply to become a Data Backend Engineer at Yelp.
View Job