Yelp’s AI pipeline for inappropriate language detection in reviews

-
Gouthami Senthamaraikkannan, Machine Learning Engineer
- Mar 12, 2024
Yelp’s mission is to connect consumers with great local businesses by giving them access to reliable and useful information. Consumer trust is one of our top priorities, which is why we make significant investments in technology and human moderation to protect the integrity and quality of content on Yelp. As a platform for user-generated content, we rely on our community of users and business owners to help report reviews that they believe may violate our Terms of Service and Content Guidelines. Our User Operations team investigates flagged content and, if it’s found to be in violation of our policies, may remove it from the platform.
Beyond user reporting, Yelp also has proactive measures in place that help mitigate hate speech, and other forms of inappropriate content through the use of automated moderation systems. In this pursuit, Yelp recently enhanced its technology stack by deploying Large Language Models (LLMs) to help surface or identify egregious instances of threats, harassment, lewdness, personal attacks or hate speech
Why LLMs for inappropriate content detection?
Automating inappropriate content detection in reviews is a complex task. Given the potential complexities of different contexts, several considerations go into creating a tool that can confidently flag content violating our policies. In the absence of high precision, such a tool can have significant consequences, including delays in evaluating reviews, while less stringent measures can result in the publication of inappropriate and unhelpful content to the public. Addressing this, we have iterated through several approaches to achieve higher precision and recall in the detection of inappropriate content. The tradeoffs in precision-recall drove us to adopt LLMs, which have been largely successful in the field of natural language processing. In particular, we explored the efficacy of LLMs to identify egregious content, such as:
- Hate speech (including disparaging content targeting individuals or groups based on their race, ethnicity, religion, nationality, gender, sexual orientation, or disability)
- Lewdness (including sexual innuendos, pickup lines, solicitation of sexual favors, as well as sexual harassment)
- Threats, harassment, or other extreme forms of personal attacks
Unrelated to this automated system, as previously mentioned, Yelp allows both consumers and business owners to report reviews they believe violate our content policies, including reviews that contain threats, harassment, lewdness, hate speech, or other displays of bigotry. In 2022, 26,500+ reported reviews were removed from Yelp’s platform for containing threats, lewdness, and hate speech. These reported reviews, along with Yelp’s pre-existing systems that curb inappropriate reviews in real-time, provided us with a large dataset to fine-tune LLMs for the given binary classification task, where the goal was to classify reviews as appropriate or inappropriate, in real-time.
Navigating challenges in data curation
To train the LLM for classification, we had access to a sizeable dataset of reviews identified as inappropriate in the past. However, given the inherent complexity of language, especially in the presence of metaphors, sarcasm and other figures of speech, it was necessary to more precisely define the task of inappropriate language detection to the LLM. To accomplish this, we collaborated with Yelp’s User Operations team to curate a high-quality dataset comprising the most egregious instances of inappropriate reviews, as well as reviews that adhered to our content guidelines. A pivotal strategy here was the introduction of a scoring scheme that enabled moderators to signal to us the severity level of inappropriateness in a review. To further augment the dataset, we also implemented similarity techniques using sentence embeddings from LLMs, and identified additional reviews that were similar to the high-quality samples we obtained from moderator annotation.
Apart from this, we also applied sampling strategies on the training data specifically to increase model recall. In order to train a model that can recognize different forms of inappropriate content, it is necessary to have a dataset with enough samples from different sub-categories of inappropriate content. Unfortunately, a large number of reviews that we curated did not contain this information. To solve this problem, we leveraged zero shot and few shot classification capabilities of LLMs to identify the sub-category of inappropriate content and performed under-sampling or over-sampling where needed.
Fine-tuning LLMs for binary classification
Using the carefully curated data, we began investigating the effectiveness of large language models for the given text classification task. We downloaded LLMs from the HuggingFace model hub and computed sentence embeddings on the preprocessed review samples. Using these embeddings, we determined the separation between appropriate and inappropriate samples by evaluating the silhouette score between the two groups, as well as by plotting them on a two-dimensional space upon dimension reduction with t-SNE. The separation was fairly apparent as can be seen in the figure below.
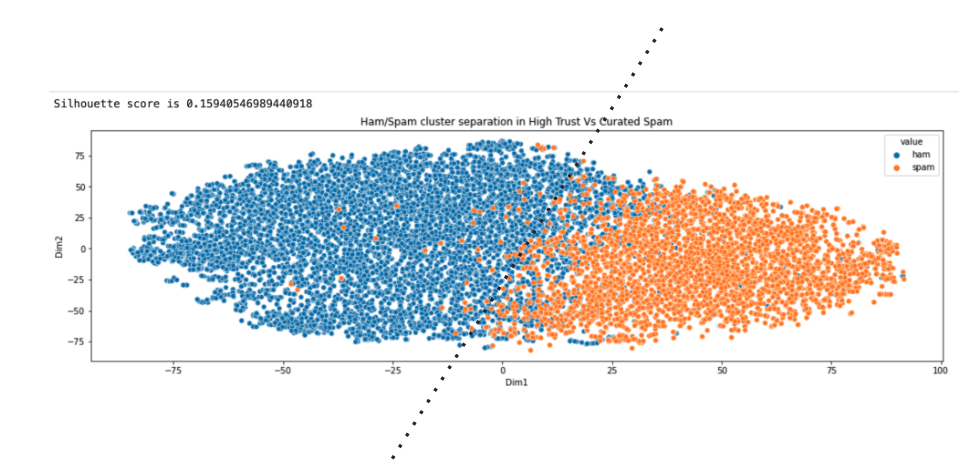
Visualizing separation between appropriate/inappropriate reviews on model embeddings
Encouraged by this, we minimally fine-tuned the same model on the dataset for the given classification task and saw successful results on the class-balanced dataset (see metrics below).
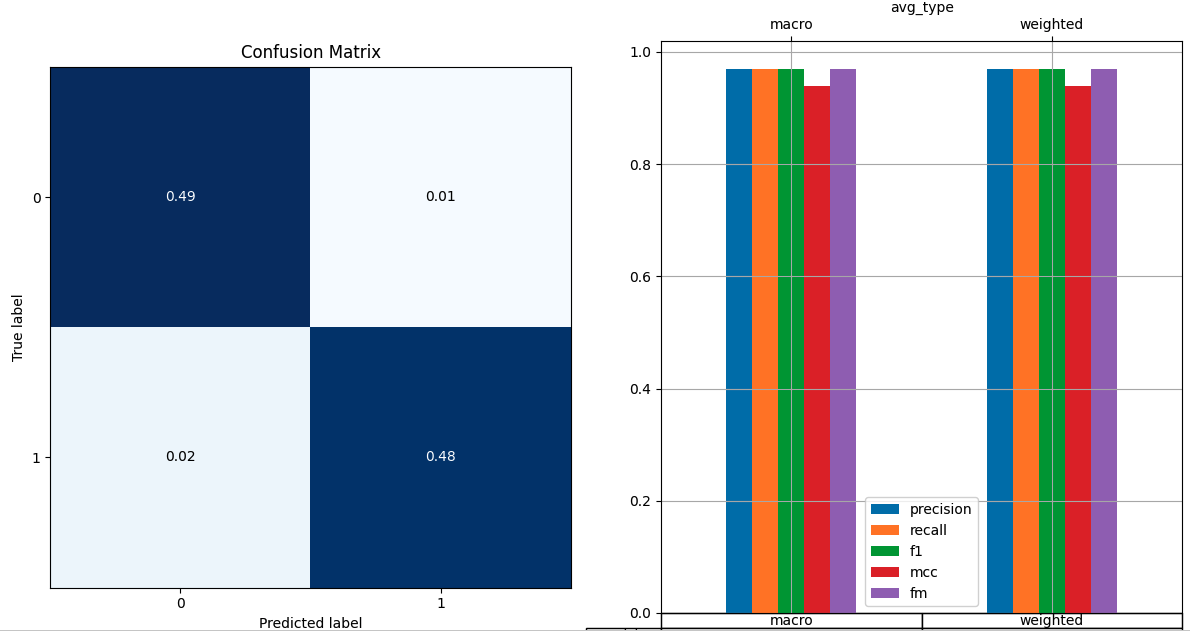
Trained model metrics on balanced test data
Although the metrics were promising, we still needed to assess the false positive rate generated by the model in real-time traffic. This is because the spam prevalence in actual traffic is very low, so we needed to be extremely careful in our assessment of the model’s performance in real-time and choose a threshold that helps generate high precision.
In order to simulate the model’s performance in real-time, we generated many sets of mock traffic data with different degrees of spam prevalence. The result of this analysis allowed us to determine the model threshold at which we can identify inappropriate reviews with an accepted range of confidence. Now we were ready to push the model’s deployment to actual traffic on Yelp.
Deployment
The following flow diagram illustrates the deployment architecture. Historical reviews stored in Redshift were selected for labeling and similarity matching (as described in the data curation section). The curated dataset is stored into an S3 bucket and fed into the model training batch script. The model generated from the batch is registered in MLFlow from which it is loaded into MLeap for serving predictions inside a service container (model server component in the picture below). Please refer to this blog post from 2020 for more details on Yelp’s ML platform.
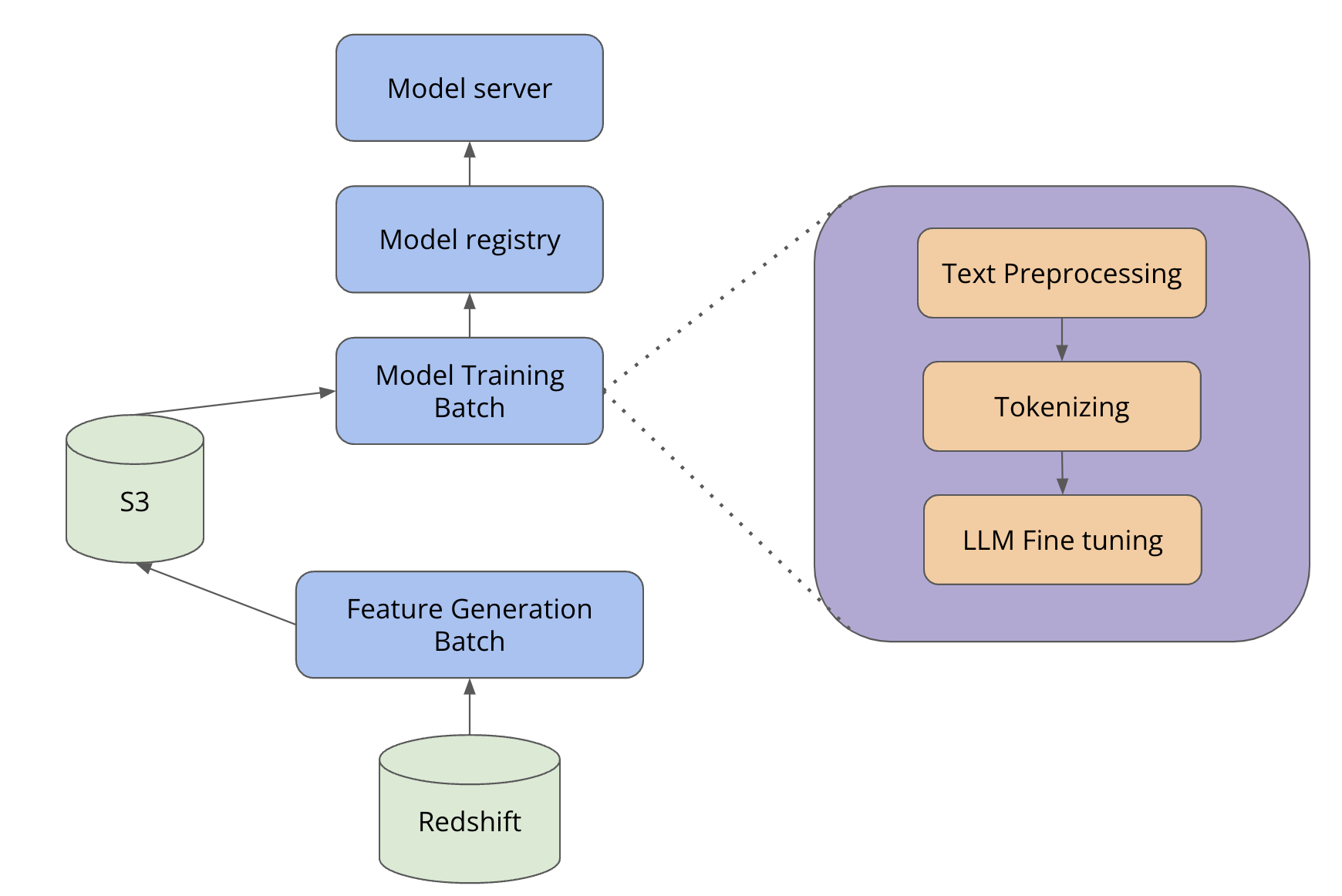
Model training & deployment process
Since incorporating LLMs to help detect harmful and inappropriate content, it enabled our moderators to proactively prevent 23,600+ reviews from ever publishing to Yelp in 2023.
Conclusion
Yelp makes significant investments in its content moderation efforts to protect consumers and businesses. Recent advancements in Large Language Models have showcased their potential in understanding context, presenting us with a significant opportunity in the field of inappropriate content detection. Through a series of strategies we have now deployed a Large Language Model to live traffic for the purpose of identifying reviews that contain egregious instances of hate speech, vulgar language, or threats and thereby, not in compliance with our Content Guidelines. The flagged reviews are manually reviewed by our User Operations team, and through this combined effort, we have proactively prevented several harmful reviews from ever being published on Yelp. However we still continue to rely on our community of users to report inappropriate reviews. Based on the decisions made by moderators and subsequent retraining of the model, we anticipate further improvements in the model’s recall in the future.
Acknowledgement
I would like to acknowledge everyone that was involved in this project. Special thanks to Marcello Tomasini, Jonathan Wang, Jiachen Zhao, Jonathan Skowera, Pankaj Chhabra for contributing to the design and implementation of the work described here. I’d also like to thank members of the ML infra team, Yunhui Zhang, Ludovic Trottier, Shuting Xi, and Jason Sleight for enabling LLM deployment, and the members of the User Operation team.
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job