Keeping track of engineering-wide goals and migrations

-
Jason Tran, Software Engineer; James Flinn, Software Engineer
- Mar 13, 2024
What is Engineering Effectiveness Metrics (EE Metrics)?
EE Metrics was envisioned as a hub that helps teams manage their technical debt. EE Metrics provides every team with a detailed web page that contains information about technical debt that needs to be addressed. It also serves as a platform to highlight top engineering initiatives at the organization level.
EE Metrics empowers infrastructure teams to surface important migrations or metrics that could improve the health of software projects. Organization-wide migrations of technologies can often be difficult to surface and keep track of.
General EE Metrics lifecycle
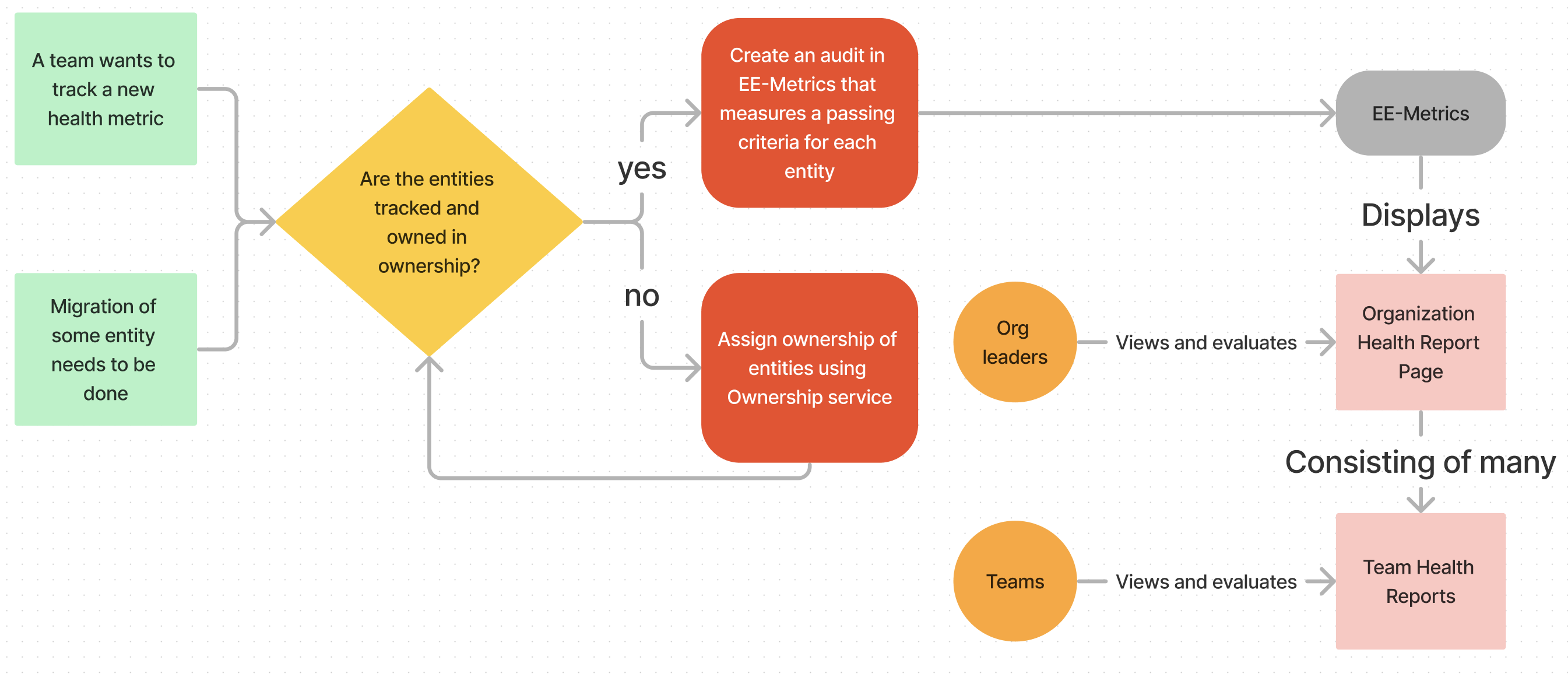
Figure 1: Diagram showing how EE Metrics is interacted with and consumed
Many of our users will generally browse their respective team’s health reports within their team specific page to understand which migrations/health metric they need to address based on the impact and priority.
The EE-metric ecosystem - the nitty gritty
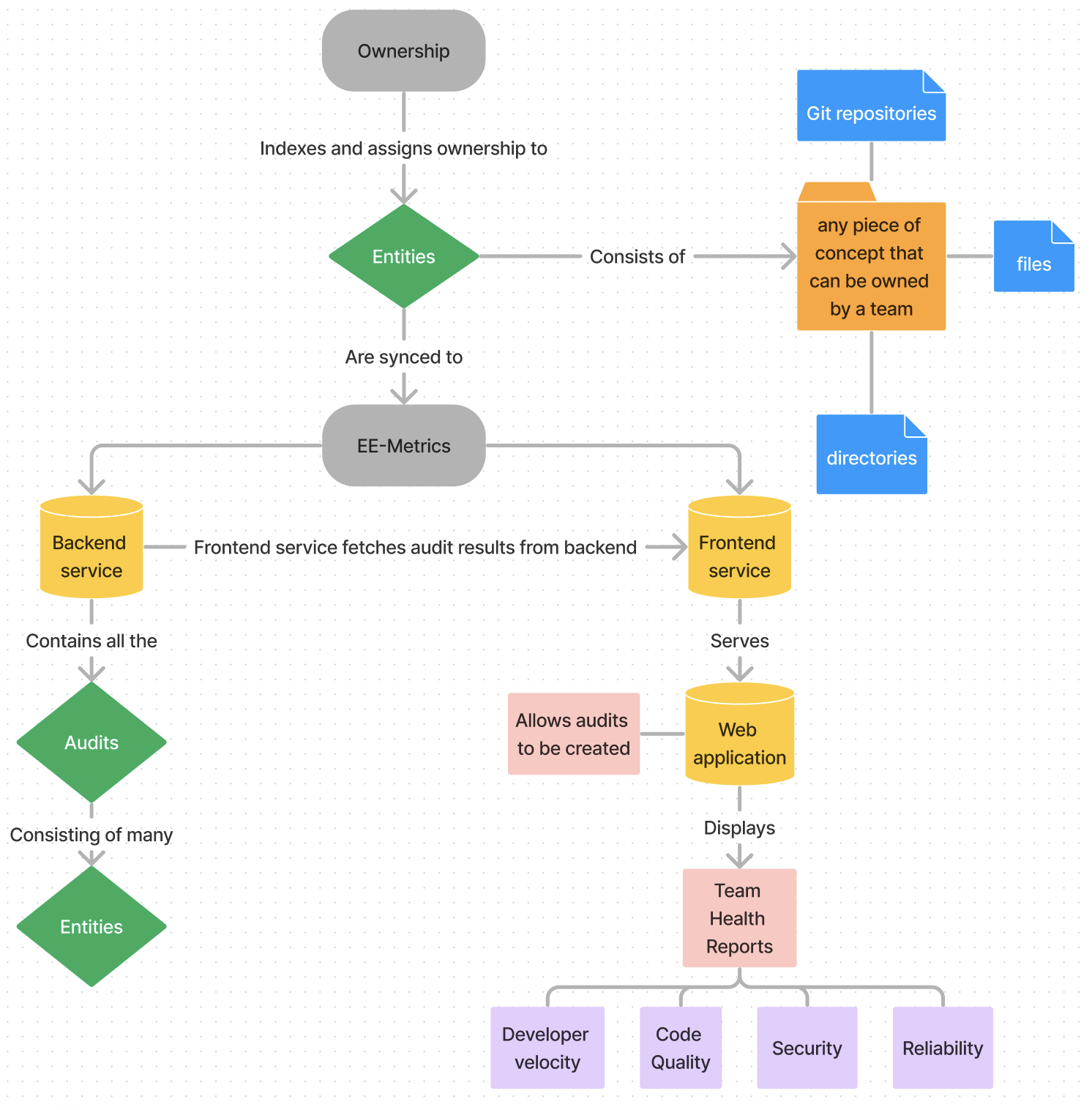
Figure 2: High level overview of the architecture of EE Metrics
EE Metrics contains two key components - a backend service that collects and calculates audit results, and a frontend service that exposes a web application. The primary interface used by users is the web application. The web application allows audit authors to create audits. These audits can be viewed in full detail within their respective pages and are surfaced through Team Health Reports. Team Health Reports attempts to analyze the teams’ health in various categories and identify areas of improvement which forms the primary purpose of EE Metrics.
Team Health Reports
The Team Health Reports act as a data-driven communication platform between infrastructure teams and product teams. There are two primary categories of metrics that comprise “Audits” in EE Metrics. First, there are org-wide initiatives called “Migrations” that are created by infrastructure teams. These initiatives include code and infrastructure updates/changes that improve the health of software projects from a velocity, quality, reliability, and security perspective. Another set of org-wide initiatives that EE Metrics surfaces are called “Health Checks’’. These tend to be recurring long-term metrics that teams attempt to keep within certain thresholds. An example would be Test Run Times. By keeping the run times of all owned services under a certain threshold, this ensures that the team has confidence that they can continue to ship features reliably and quickly.
The EE Metrics Team Health Report allows teams to view the overall health of a team’s developer velocity, code quality, reliability, and security and gives teams their top priority action items to improve in each of these areas. This helps with balancing the pressure of shipping new product features versus maintenance work.
How do team health reports work?
Team Health Reports are driven by a series of audits that are run against all of a team’s entities (services, libraries, files, directories, etc.). Entities can be any piece of technology or concept that can be owned by teams. To help assign audits to teams, we use the Ownership service to determine what entities fall under the team’s health report (for more information about ownership, check out our blog post on Ownership). Once the health report is generated for a team, it lists the action items teams can take to make improvements, ranked in order of impact and priority. The results of these audits are collected once a day and can be viewed in the EE Metrics web application, or through a monthly email report sent to the team and org leaders. The status of previous audits are also preserved so that users can view the historical results of audits to figure out if there are any trends.
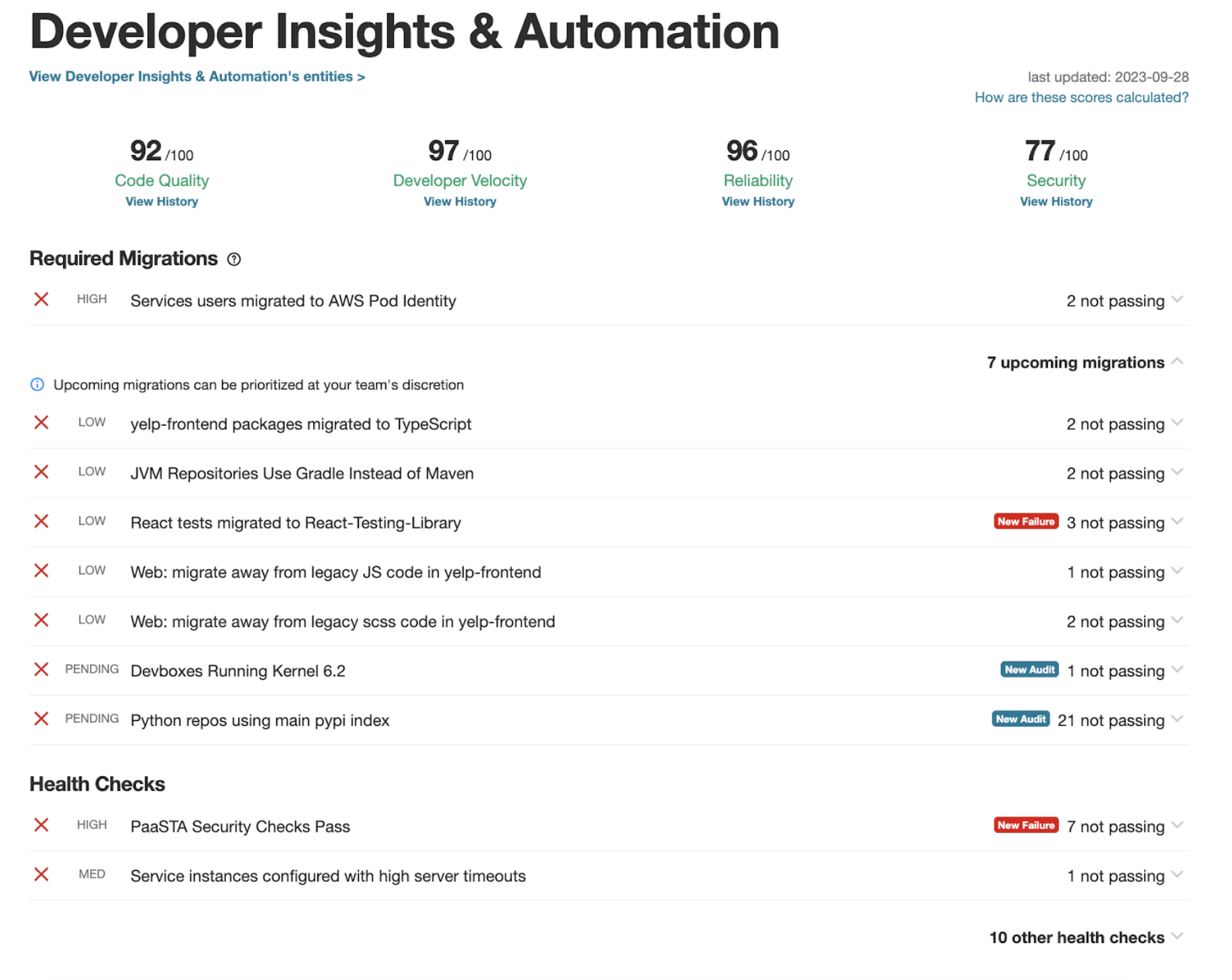
Figure 3: This is a snapshot of a team’s health report as seen in the web application
What are these scores?
The scores in the figure above (figure 3) represent how effective your team is based on the amount of audits outstanding or completed. Audits have a weight assigned to them based on their priority. This helps users understand which audits require more immediate attention. These scores are primarily driven by this factor:
- 60% of your score is attributed to audits weighted as HIGH.
- 30% of your score is attributed to audits weighted as MED.
- 10% of your score is attributed to audits weighted as LOW.
There are other factors that affect scores such as whether a migration is overdue or not, if it’s an informational audit, or if it is a pending new audit. Primarily, we came up with this scoring to ensure that if a team has completed all their high weighted audits, they are deemed to be in good standing.
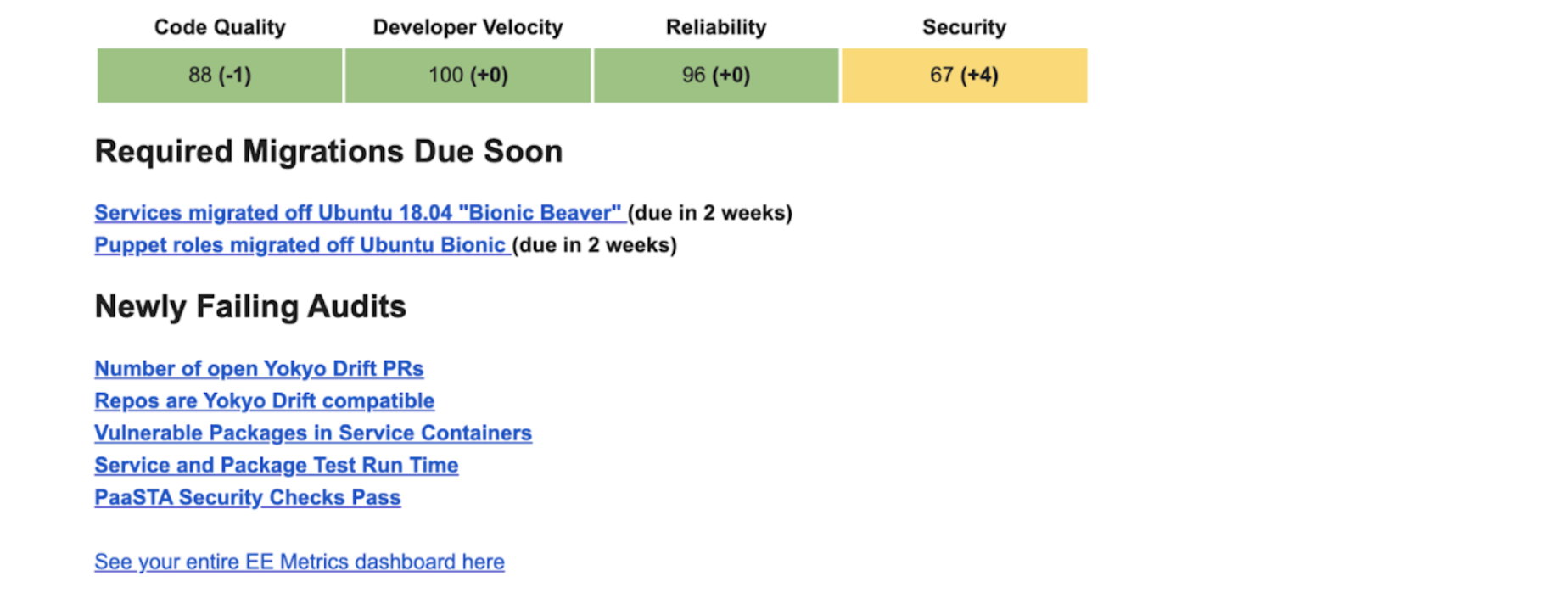
Figure 4: This is a snapshot of a team’s health report in the form of an email surfacing important notes
Audit Creation and Guidelines
Audits are created by infrastructure teams. These can be one-time initiatives such as migrating off a deprecated service. Audits can also be long term measurements of metrics that must pass a specific threshold or be within acceptable bounds. An example would be measuring how often a test fails during the release process. If the amount of test failures exceed a specific threshold, this would suggest unreliable test coverage and therefore would need to be addressed.
Infrastructure teams are empowered to add new audits to EE Metrics when they are trying to enact change in their areas of ownership. These audits are powered by various data sources collected by the EE Metrics Events Pipeline and additional platform services: these are called metrics and are required for audits to determine the state of an entity. Once a metric is tracked, writing a new audit to the platform is simple. After many iterations of audits, we came up with a set of guidelines when writing a new audit:
- Audits should contain enough context for teams to address and solve - if certain audits require a lot of external context, teams are to be directed to additional documentation to help them understand the requirements of the audit.
- Audits should be actionable by the teams themselves. If improvements require heavy lifting from an infrastructure team, the infrastructure team should directly drive those improvements.
- Audits should be targeted at the team level across the engineering organization. For example, checking for a particular antipattern one specific developer introduced is not the goal for audits.
Once a new audit configuration is deployed, the Team Health Reports are updated to include the new audit.
We’ve taken a democratic approach of allowing infrastructure teams to define their audits’ thresholds and impact levels by establishing defined criteria and providing guidance. While we initially had concerns that infrastructure teams would view their audits as always having the highest impact, we found metric owners have a good understanding on how their audits play in the bigger picture in the overall health of a team.
Required Migrations
Required Migrations are any engineering efforts highlighted at the organizational level that are deemed important. These are engineering initiatives that are to be completed by their respective due dates. Some examples of a Required Migration could be an internal migration of services from a deprecated technology to a new technology or organization level upgrades to repositories. These are migrations for technologies that pose the most risk or have outsized benefits across the entire engineering org.
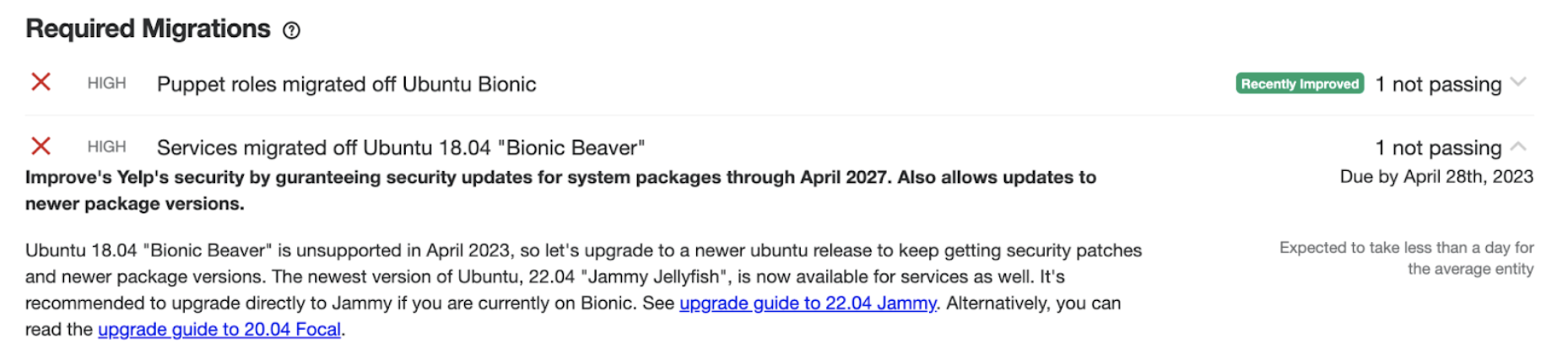
Figure 5: Example of failing Required Migrations
Why is EE Metrics important for Required Migrations?
It can be difficult to highlight and keep track of engineering initiatives that are important to be done at the organization level. Since EE Metrics collects and displays audit results, this can be leveraged to provide an accurate assessment on the completion of an engineering initiative. This aims to provide a platform to keep track of and send detailed reports on the progress of these initiatives at the team and organization level. Teams often do not have the bandwidth to address all of the audits surfaced. To alleviate this, Required Migrations serve as a way to prioritize engineering initiatives. Required Migrations are part of the roadmap planning process org-wide where teams must commit time to addressing these migrations. The goal of EE Metrics is to further increase visibility of these initiatives within the organization.
What is the process to designate a migration as ‘Required’?
Determining whether a migration is a top initiative or not depends on several factors. Generally, the overall process is as follows:
- Migration authors discuss with their Engineering Manager to propose the escalation of migrations based on importance, severity, and potential consequences if left undone.
- Various EMs, TPMs, and Directors coordinate the tentative list of required migrations.
- VPs approve the list of migrations and it is labeled as Required Migrations.
- Migration authors are designated as the owner foreseeing the completion of their migration. A corresponding migration and audit are created in the EE Metrics services for each Required Migration.
As teams and organization leaders are aware of the required migrations that need to be accomplished, it becomes easier to ensure completion of these migrations are done by a specific date.
How has EE Metrics helped Yelp?
EE Metrics serves as a hub for employees to easily identify engineering initiatives and issues that need to be resolved. By handling these issues and performing migrations early on, this reduces technical debt and improves developer effectiveness. As an organization grows and expands, identifying engineering initiatives and potential issues becomes harder to echo without a centralized platform.
A team at Yelp had a cohorting issue with an experiment they were running. This caused a lot of headaches: identifying the problem was difficult and unclear. The team in question checked their EE Metrics Team Health Report and found the audit pointing out deficiencies in their experiment.

Figure 6: The audit that was pointing out that one of their experiments was deficient
The team was able to solve their issue and strived to continue to improve their EE Metrics scores. This had been helpful for their team that they decided to share their experiences with us about EE Metrics and how it had helped them.

The team at Yelp provided a nice testimonial for our team
What’s next for EE Metrics?
We’re delighted by all the internal usage of EE Metrics and we will continue to iterate and develop tools to better surface visibility of debt at the company. We hope to see EE Metrics continue paving the path to become a powerful tool when we’re addressing technical debt.
Acknowledgements
We would like to send a warm thank you to all past, present and future individuals who have contributed to the development of EE Metrics.
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job