Loading data into Redshift with DBT

-
Christopher Arnold, Software Engineer
- Nov 6, 2024
At Yelp, we embrace innovation and thrive on exploring new possibilities. With our consumers’ ever growing appetite for data, we recently revisited how we could load data into Redshift more efficiently. In this blog post, we explore how DBT can be used seamlessly with Redshift Spectrum to read data from Data Lake into Redshift to significantly reduce runtime, resolve data quality issues, and improve developer productivity.
Starting Point
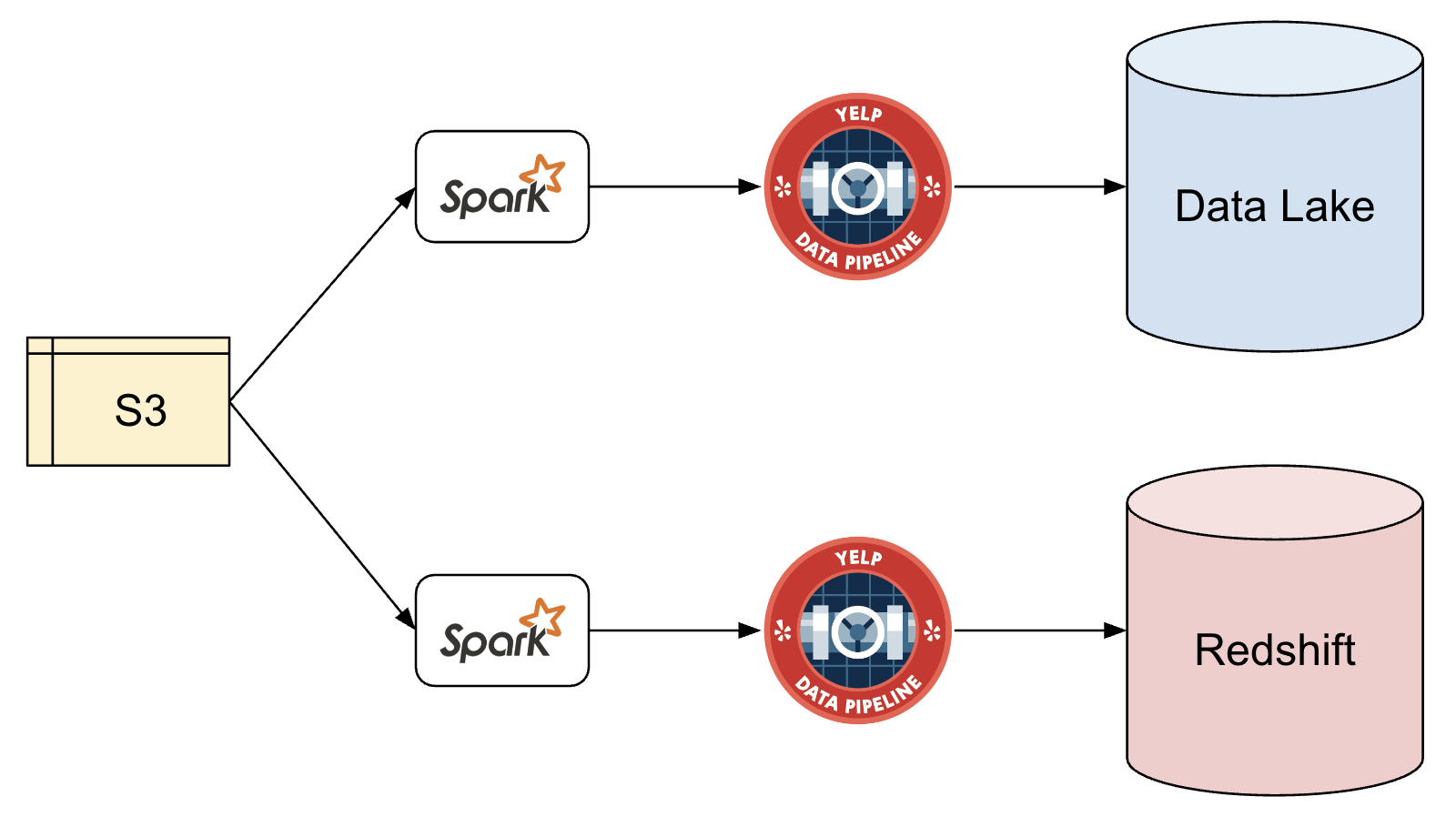
Our method of loading batch data into Redshift had been effective for years, but we continually sought improvements. We primarily used Spark jobs to read S3 data and publish it to our in-house Kafka-based Data Pipeline (which you can read more about here) to get data into both Data Lake and Redshift. However, we began encountering a few pain points:
- Performance: Larger datasets (100M+ rows daily) were beginning to face delays. This was mostly due to table scans to ensure that primary keys were not being duplicated upon upserts.
- Schema changes: Most tables were configured with an Avro schema. Schema changes were sometimes complex, as they required a multi-step process to create and register new Avro schemas.
- Backfilling: Correcting data with backfills was poorly supported, as there was no easy way to modify rows in-place. We often resorted to manually deleting data before writing the corrected data for the entire partition.
- Data quality: Writing to Data Lake and Redshift in parallel posed a risk of data divergence, such as differences in data typing between the two data stores.
Improving Redshift loads with DBT
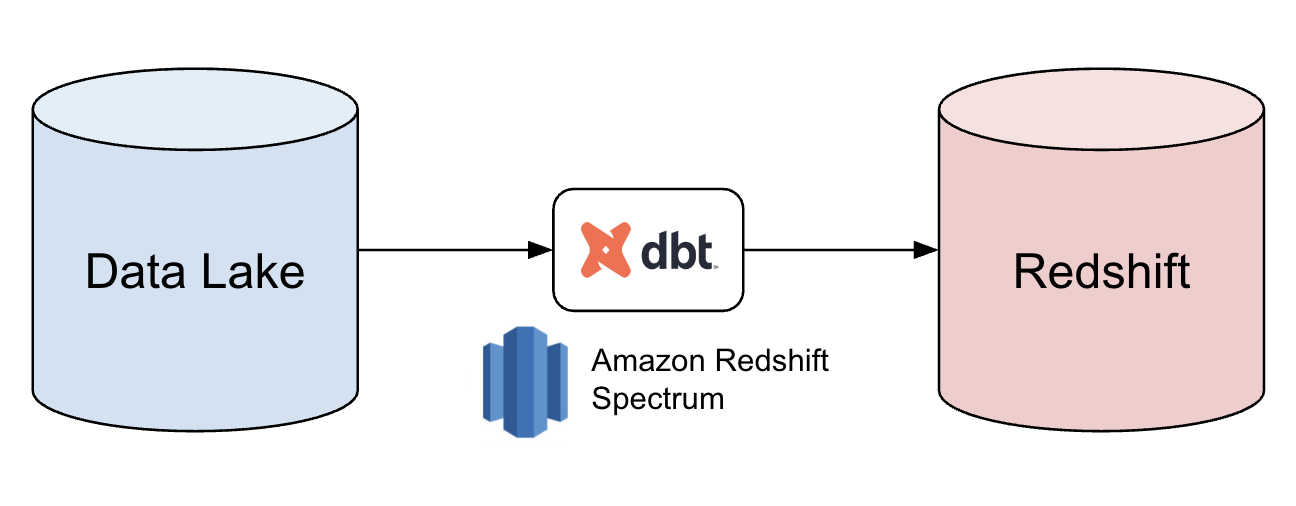
When considering how to move data around more efficiently, we chose to leverage AWS Redshift Spectrum, a tool built specifically to make it possible to query Data Lake data from Redshift. Since Data Lake tables usually had the most updated schemas, we decided to use it as the data source instead of S3 for our Redshift batches. Not only did it help reduce data divergence, it also aligned with our best practice of treating the Data Lake as the single source of truth.
For implementation, Spectrum requires a defined schema, which already exists in Glue for our Data Lake tables. The only other additional setup needed was to add the Data Lake tables as external tables, making them accessible from Redshift with a simple SQL query.

We had already started adopting DBT for other datasets, but it also seemed like the perfect candidate to capture our Redshift Spectrum queries in our pipeline. DBT excels at transforming data and helps enforce writing modularized and version controlled SQL. Instead of a Spark job reading from S3 to Redshift, we used DBT to simply copy the data from Data Lake directly to Redshift. Not only did DBT provide its usual trademark benefits of reproducibility, flexibility and data lineage, but it also helped us combat some of the pain points mentioned above.
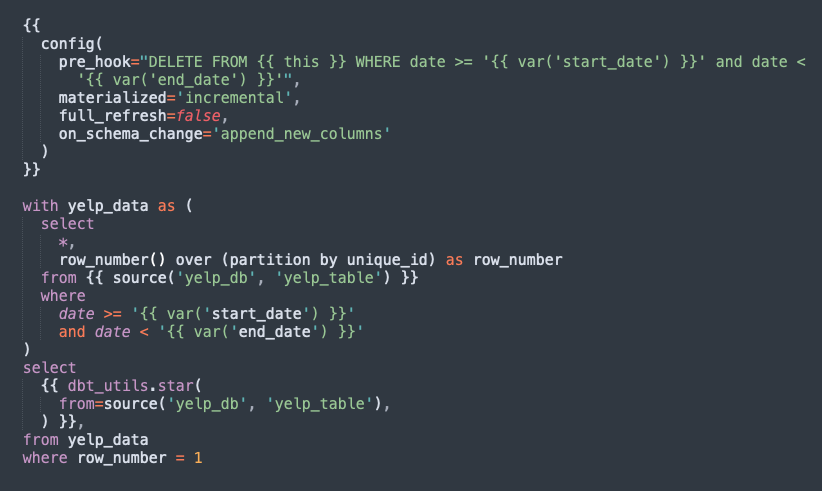
Simplified schema changes
To simplify schema changes, we took advantage of DBT’s on_schema_change configuration argument. By setting it to append_new_columns, we ensured that columns would not be deleted if they were absent from the incoming data. We also used DBT contracts as a second layer of protection to ensure that the data being written matched the model’s configuration.
Backfills less manual
Backfilling also became a lot easier with DBT. By using DBT’s pre_hook configuration argument, we could specify a query to execute just before the model. This enabled us to delete the data for the partition about to be written more automatically. Now that we could guarantee idempotency, backfills could be done without worrying about stale data not being removed.
Data deduplication

To tackle duplicate rows, we added a deduplication layer to the SQL, which was validated with a DBT test. While DBT has built-in unique column tests, they weren’t feasible for our large tables since they required scanning the entire table. Instead, we used the expect_column_values_to_be_unique function from the dbt_expectations package. This allowed us to specify a row condition to scan only the rows recently written.
Performance Gains
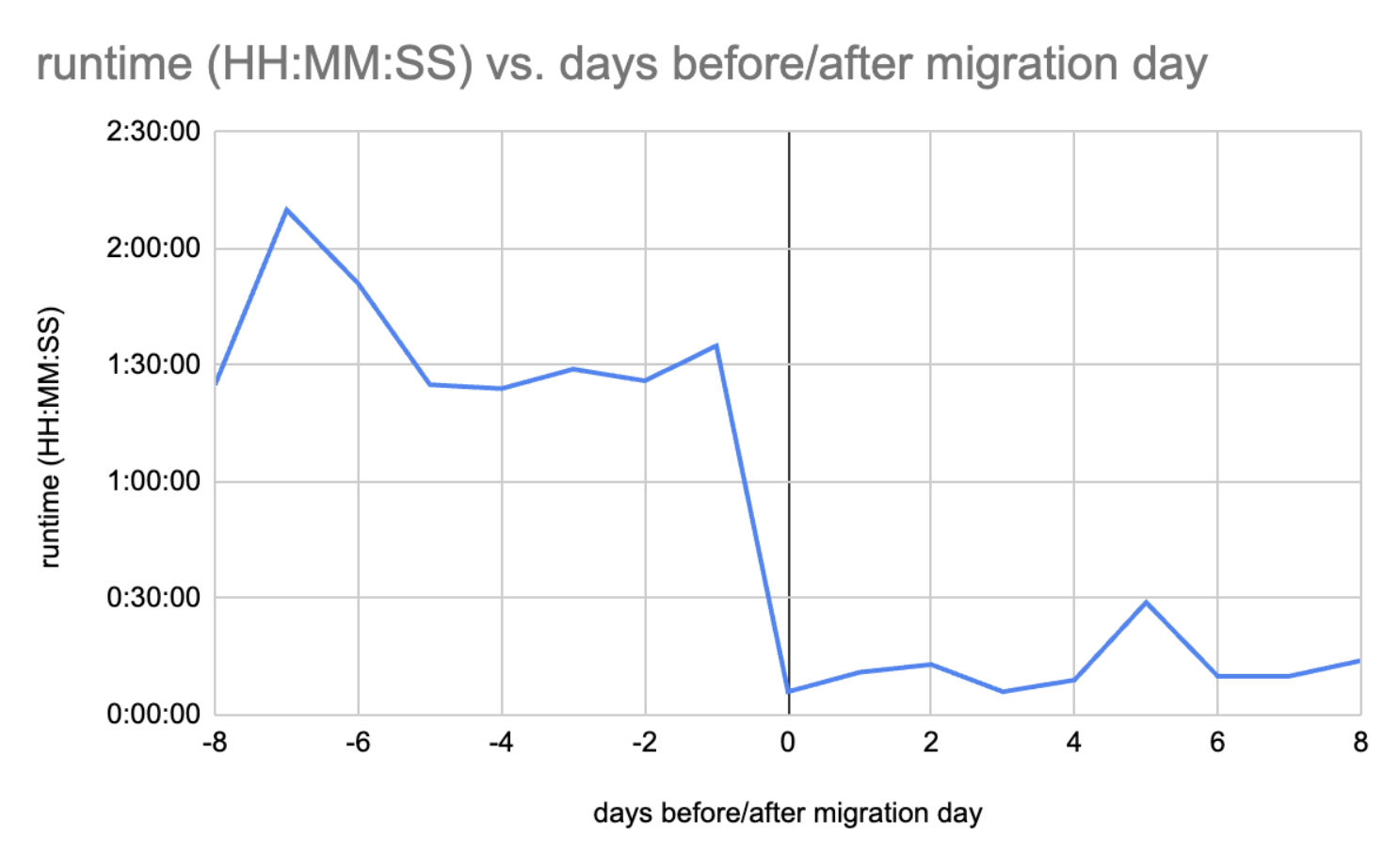
The most noticeable win was in performance, especially for our largest and most problematic Redshift dataset:
- Writing used to take about 2 hours, but now it typically runs in just 10 minutes.
- Before, there were sometimes up to 6 hours of delays per month. Now we no longer experience any delays! This has greatly reduced the burden on our on-call incident response efforts.
- Schema upgrades used to be a longer multi-step process. This has been improved to a 3-step process that only takes a few hours.
Better data consistency
By eliminating the forking of data flows, we increased our confidence that data wouldn’t diverge between different data stores. Since any data entering Redshift must first pass through Data Lake, we could better ensure that Data Lake remained our single source of truth.
Conclusion
Following the success of the migration, we rolled out these changes to approximately a dozen other datasets and observed similar benefits across the board. By leveraging tools like AWS Redshift Spectrum and DBT, we better aligned our infrastructure with our evolving data needs, providing even greater value to our users and stakeholders.
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job