Revisiting Compute Scaling

-
Ilkin Mammadzada and Ankit Tripathi, Site Reliability Engineers
- Dec 13, 2024
As mentioned in our earlier blog post Fine-tuning AWS ASGs with Attribute Based Instance Selection, we recently embarked on an exciting journey to enhance our Kubernetes cluster’s node autoscaler infrastructure. In this blog post, we’ll delve into the rationale behind transitioning from our internally developed Clusterman autoscaler to AWS Karpenter. Join us as we explore the reasons for our switch, address the challenges with Clusterman, and embrace the opportunities with Karpenter.
Clusterman and its challenges
At Yelp, we used Clusterman to handle autoscaling of nodes in Kubernetes clusters. It is an open-source tool we initially designed for Mesos clusters and later adapted for Kubernetes. Instead of managing entire clusters, Clusterman focuses on the management of pools, wherein each pool comprises groups of nodes backed by AWS Auto Scaling Groups (ASGs). These pools are governed by a config called the setpoint, representing the desired reservation ratio between “Requested Resources by Workloads” and “Total Allocatable Resources.” Clusterman actively maintains this reservation ratio by adjusting the desired capacity of ASGs. It has also got some nifty features for safely recycling nodes, using custom signals to scale clusters, and a simulator to experiment with different scaling parameters.
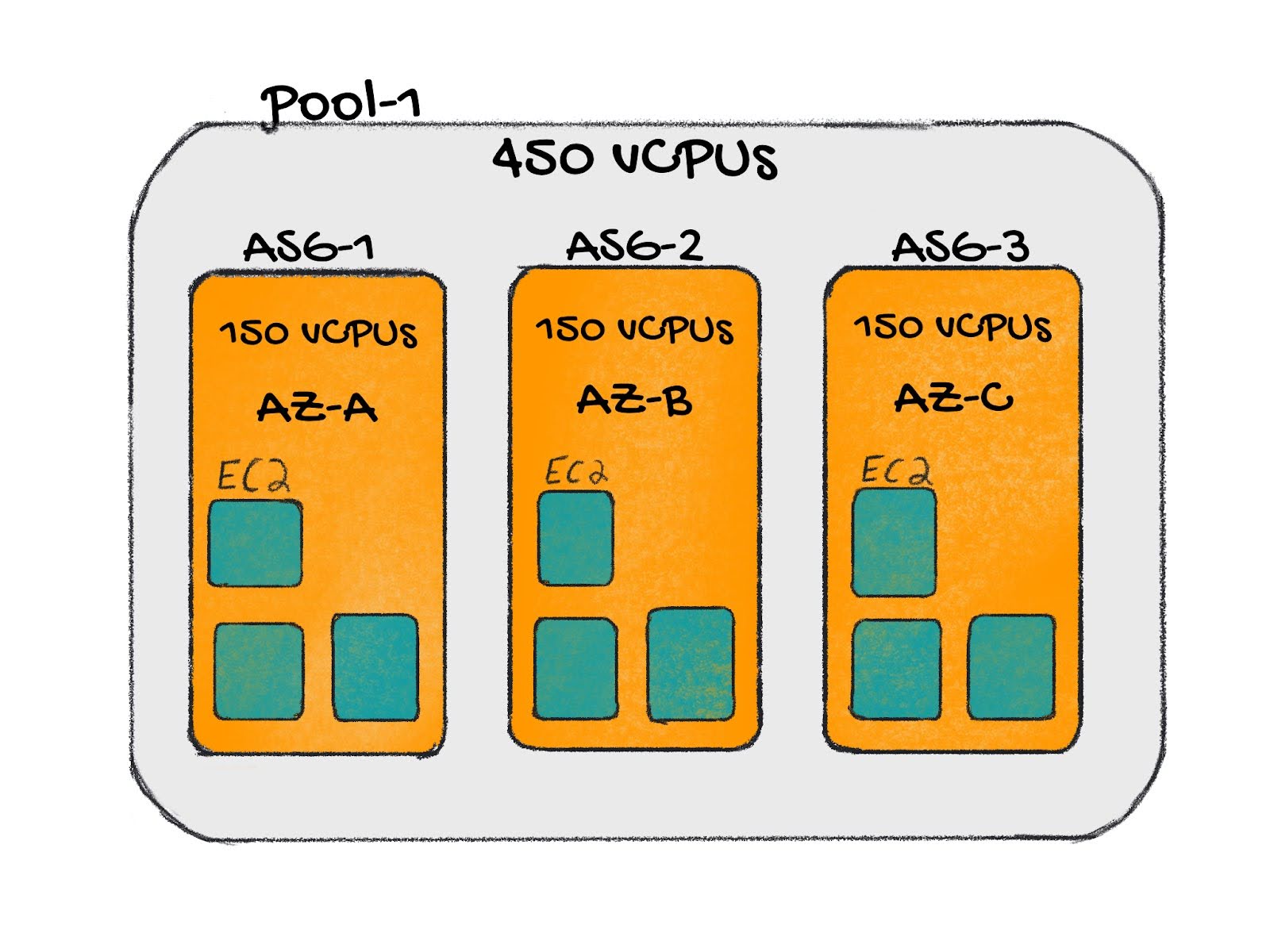
Despite its capabilities, Clusterman had its challenges. If your clusters are frequently being scaled up or down, finding the perfect setpoint can be a tricky task. Choosing a lower setpoint ensures cluster stability but runs at a higher cost. Conversely, a higher setpoint might lead to difficulties in maintaining the desired ratio of resources. When Clusterman attempted to maintain the setpoint, it would sometimes delete nodes (and the pods on those nodes) to increase the ratio, causing the deleted pods to become unschedulable due to insufficient resources in the pool. To address these unschedulable pods, Clusterman would launch new instances. However, this process could lead to an endless cycle of scaling up and down, as Clusterman continuously tried to balance the cluster. This cycle could result in inefficiencies and resource management issues, making it difficult to achieve a stable and cost-effective scaling strategy.
Another hitch was workload requirements. Clusterman relies on ASGs, and it doesn’t consider the specific needs of your pending pods. If those pods demand certain resources like ‘R category EC2s,’ it’s often a matter of luck if the ASG will give you R category EC2s. Consequently, when dealing with such specific requirements, you’d often find yourself creating new pools and specifying the instance types in the ASGs which also results in managing another Clusterman instance for the pool. This method of managing the pools and its requirements eventually increases the operational cost of managing Kubernetes clusters.
Furthermore, Clusterman had its speed issues. Due to its interval-based logic that iterated every ‘X’ minutes, it sometimes struggled to keep up with rapidly changing workload demands, making it less than ideal for dynamic clusters. Lastly, customizing recycling criteria meant tinkering with the code, making it less flexible for unique requirements like recycling G5 family instances.
Replacement autoscaler
Requirements
As the challenges with Clusterman became increasingly apparent, we embarked on a mission to gather input from various teams that run workloads on Kubernetes. We discovered numerous specific requirements that highlighted the burden of managing Clusterman. These requirements included:
- The need for an autoscaler capable of identifying the availability zone of stateful pending pods’ volumes and launching new instances in the corresponding zone.
- Diverse machine learning workloads, each with different GPU requirements.
- The importance of accommodating workload constraints, such as topology spread constraints and affinities. The overarching theme among the teams’ requirements: ‘Find the right instances for my dynamic workload requirements’.
In addition to these, we had our own set of demands:
- The ability for the autoscaler to react to pending pods in a matter of seconds.
- Ensure that autoscaling remains cost-efficient.
Alternative options
In our quest for an alternative to Clusterman, we explored two primary options: Kubernetes Cluster Autoscaler and Karpenter.
We opted against Kubernetes Cluster Autoscaler as we would have faced similar problems as we experienced in Clusterman. Notably, it organizes nodes into groups where all nodes must be identical, posing a challenge for our diverse workloads with varying requirements.
Karpenter is an open-source node lifecycle management project built for Kubernetes, developed by AWS. Karpenter not only launches the boxes for our requirements but also brings some features to the table:
- Better Bin Packing: Clusterman relied on ASGs when it came to deciding the instance types and sizes for workload, which resulted in higher cost and lower resource utilization, Karpenter on the other hand has a far better approach by creating batches of pending pods and considering workload resource requirements before launching instances.
- Pool Based Segregation: In Karpenter, by having the same status quo for pool based segregation and using nodepools we had a better migration path (as other Yelp infrastructure relies on the pool based approach).
- Customizable TTL: Karpenter empowers you to specify a Time-to-Live (TTL) for your nodes, enabling graceful node recycling after a designated time (e.g., ‘Please recycle my nodes after 10 days’) while respecting Pod Disruption Budgets (PDB).
- Cost Optimization: Karpenter can be your partner in cost efficiency. It offers features like:
- Automatically deleting a node if all of its pods can run on available capacity of other nodes in the cluster.
- Replacing on-demand instances with more cost-effective options when available.
- Terminating a couple of instances to replace them with larger, more cost-efficient ones.
- Enhanced Scheduling: Karpenter enriches nodes with useful labels, contributing to smarter workload scheduling. Now workloads don’t need to create a new pool for their specific EC2 requirements. They can just add requirements (EC2 category, family, generation etc. visit Well-Known Labels for the list) to node selector/affinity.
- Fall-back mechanism for spot market: With Clusterman, managing periods of high spot market demand (e.g., Black Friday week) was challenging, requiring us to manually adjust our ASG specifications. But Karpenter can run spot and on-demand instances in the same pool. It will launch on-demand instances if there is no spot capacity in the region/availability zone. It helped us handle Black Friday week.
- Insightful Metrics: Karpenter provides a suite of useful metrics to help you gain a deeper understanding of the autoscaling state and compute costs. Understanding the cost impact of changing auto scaling specifications was difficult without real-time cost metrics.
In choosing Karpenter, we found a solution that not only meets our fundamental requirements but also equips us with the tools and features to navigate the ever-evolving landscape of infrastructure management.
Migration Strategy
As we began our transition from Clusterman to Karpenter, a key consideration was the reliance of Clusterman on ASGs (with Attribute-Based Instance Type Selection), where you can specify a set of instance attributes that describe your compute requirements instead of manually choosing instance types. Our ASGs were attribute-based, making it relatively straightforward to convert ASG requirements to Karpenter nodepools. However, it’s essential to note that nodepools in Karpenter don’t mirror all the attributes present in ASGs. For instance, we couldn’t directly match attributes like CPU manufacturers.
Early in the migration process, we explored the possibility of transferring ownership of nodes from ASGs to Karpenter to ensure a seamless transition. Unfortunately, we discovered that this approach wasn’t feasible with Karpenter.
Instead, we decided to gradually replace nodes by scaling down the ASG capacity which allowed Clusterman to delete nodes at a slower pace. While node deletions led to unschedulable pods in the pool, Karpenter efficiently detected these unschedulable pods and quickly scaled up the necessary resources to make sure that there is no unschedulable pods in the pool, ensuring the smooth scheduling of pods on the newly provisioned nodes.
However, the transition was smoother than anticipated due to some strategic decisions we had made previously. We had proactively added Pod Disruption Budgets (PDBs) for all our workloads to protect workloads from voluntary disruptions. These PDBs played a pivotal role in mitigating any potential issues for our workloads during the migration.
To closely monitor and track the migration process, we developed a comprehensive dashboard. This dashboard included various charts and metrics, such as:
- ASGs’ capacity compared to Karpenter’s capacity.
- Hourly resource cost to keep a close eye on spending.
- Spot interruption rate for monitoring instance stability.
- Autoscaler spending efficiency to ensure cost-effectiveness.
- Scaling up and down events.
- Insights into unschedulable pods and pod scheduling times.
- Workload error rates.
Lessons Learned
Allocation strategies for Spot Instances
One valuable lesson we learned during the migration process revolved around allocation strategies for Spot Instances. In our previous setup, we had a few AWS Auto Scaling Groups (ASGs) configured with the lowest-price allocation strategy. However, AWS Karpenter utilizes a price-capacity-optimized allocation strategy, and what’s more, it’s not configurable.
At the outset of our migration journey, this seemingly rigid strategy prompted some concerns. We worried that it might lead to increased costs, as our expectations leaned toward unpredictability. However, as our experience with Karpenter unfolded, we were pleasantly surprised. Its capabilities ensured not only a significant reduction in spot interruptions but also cost-effectiveness.
Keeping free room for critical services’ HPAs
One key lesson we learned during our Clusterman journey was the need to ensure we had some free resources available for our critical workloads. These workloads could require more replicas in a short amount of time, especially during sudden spikes in demand. We can easily solve this by reducing a setpoint setting. However, AWS Karpenter, while highly efficient, didn’t provide a built-in feature to reserve free capacity explicitly.
To address this challenge, we decided to run dummy pods with a specific ‘PriorityClass.’ This PriorityClass allows the Kubernetes scheduler to preempt those dummy pods if there are any unschedulable pods, creating space for our critical services’ Horizontal Pod Autoscalers (HPAs). This approach effectively ensured that we always had some buffer capacity available for our high-priority workloads.
Aligning Karpenter with Cluster Configuration Practices
A crucial lesson we gained from our migration experience was the significance of addressing workloads with high ephemeral-storage requirements. As stated above, we are using ASGs in our setup and ASGs use Launch Templates to get EC2 configurations (e.g. ami-id, network, storage etc.). We increased storage information (the instance root volume) in our launch templates. However, this volume size cannot be discovered by Karpenter even though we specified our launch template name in the Karpenter configuration. Karpenter wasn’t aware of these modifications and assumed that all instances had a standard 17 GB storage. This caused those workloads to stay unschedulable indefinitely.
This misunderstanding presented a roadblock as Karpenter struggled to find suitable instances for workloads with high ephemeral-storage needs. To overcome this challenge, we initiated an evaluation process to explore the use of blockDeviceMappings in each NodeClass. By utilizing this Karpenter feature, we aim to provide Karpenter with the necessary information about our instances’ actual volume sizes.
We also encountered another ephemeral-storage issue with our Flink workloads pool. Since Flink workloads demand fast and large storage operations, we selected EC2 instances with local NVMe-based SSD block-level storage (e.g., c6id, m6id, etc.). However, Karpenter was unable to recognize the local SSD storage as ephemeral storage for pods, which blocked our Flink pool migration. Fortunately, the Karpenter team addressed our concern and released a new version that introduced the instanceStorePolicy setting to resolve this issue.
Another noteworthy aspect of our migration involved the realization that Karpenter wasn’t inherently aware of our kubelet settings, which reside in our configuration management system. For instance, we had specified that 2 vCPUs and 4 GB of memory should be reserved for system processes using the ‘system-reserved’ configuration. Unfortunately, Karpenter lacked awareness of these specifics, leading to miscalculations in resource allocation. Additionally, we encountered disparities between our ‘max-pods’ setting and Karpenter’s internal calculations. The nuanced differences in how our configuration management system and Karpenter interpreted these settings highlighted the need for a more seamless integration between external configurations and Karpenter’s resource management algorithms.
These experiences taught us how important it is to follow Karpenter native configurations. When we make sure that AWS Karpenter understands our workload needs and the resources we have, it can do a much better job at managing everything efficiently.
Performance and Scalability
AWS Karpenter is faster than Clusterman. The key distinction lies in their approaches to resource monitoring. Clusterman relies on periodic checks (minimum 1 minute), causing delays in detecting and responding to unschedulable pods. Instead, Karpenter leverages the power of Kubernetes events, allowing it to promptly detect and react to unschedulable pods in real-time (a couple of seconds). This event-driven model significantly enhances performance, ensuring a more responsive and dynamic scaling experience.
Karpenter not only outshines Clusterman in performance but also takes the lead in scalability. Clusterman, with its memory-intensive approach of storing all pod and node information, faces challenges as the cluster size grows. The potential for Out-of-Memory errors looms, impacting its scalability. Conversely, Karpenter adopts a more streamlined approach by storing only essential information in memory. Moreover, Karpenter avoids the performance bottleneck of reading all resources from the kube-apiserver, making it a more scalable solution as your cluster expands. This dual focus on enhanced performance and scalability positions Karpenter as a reliable and efficient choice for managing Kubernetes clusters.
We created a new metric (spending efficiency) to track the computing cost improvements during the migration. The spending efficiency is the price of running one unit resource: CPU/Memory. Karpenter improved our spending efficiency by an average of 25% across all pools.
Conclusion
Initially, Clusterman was an optimal and practical solution for us at Yelp, especially during our transition from Mesos to Kubernetes. At that time, extending Clusterman’s capability from Mesos to scaling Kubernetes workloads was a strategic decision. This made Clusterman the only open-source autoscaler that supported both Kubernetes and Mesos workloads, simplifying our migration process.
However, as we moved all workloads to Kubernetes, maintaining Clusterman became an overhead and lacked key features required to run current workloads. This was particularly true when superior open-source autoscalers such as Karpenter became available, offering more advanced features and better support for Kubernetes.
Acknowledgments
This was a team project inside Yelp’s Compute Infrastructure team. Many thanks to Ajay Pratap Singh, Max Falk and Wilmer Bandres for being the part of the project, and to the many engineering teams at Yelp that contributed to making the new system a success. Additionally, thanks to Matthew Mead-Briggs for his managerial support.
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job