How Partition Access Visualizations Reduced our Data Lake S3 Cost by 33%

-
Nick Del Nano, Data Streaming
- May 21, 2026
Introduction
In large analytics environments, data teams often struggle to answer deceptively simple questions, like who their stakeholders are and how their data is being used. At Yelp, we address this by visualizing access patterns, plotting time-based partition key values against access event timestamps. These visualizations reveal distinct usage signatures – ad hoc queries, daily batch jobs, and periodic backfills – allowing data owners to understand their stakeholders and use cases. This deeper insight into data usage has enabled high-impact platform initiatives including migrating thousands of tables to Apache Iceberg format and identifying storage efficiencies which reduced the cost of our petabyte-scale data lake by 33%.
Without data-driven usage attribution, teams rely on stakeholder conversations, documentation, and word of mouth – sources that quickly become out of date. This makes it difficult for data owners to effectively steward their data and limits the support that platform teams can autonomously offer. Granular usage attribution solves this problem by enabling clear insight into how data is consumed and unlocks opportunities for significant cost efficiencies.
Visualizations
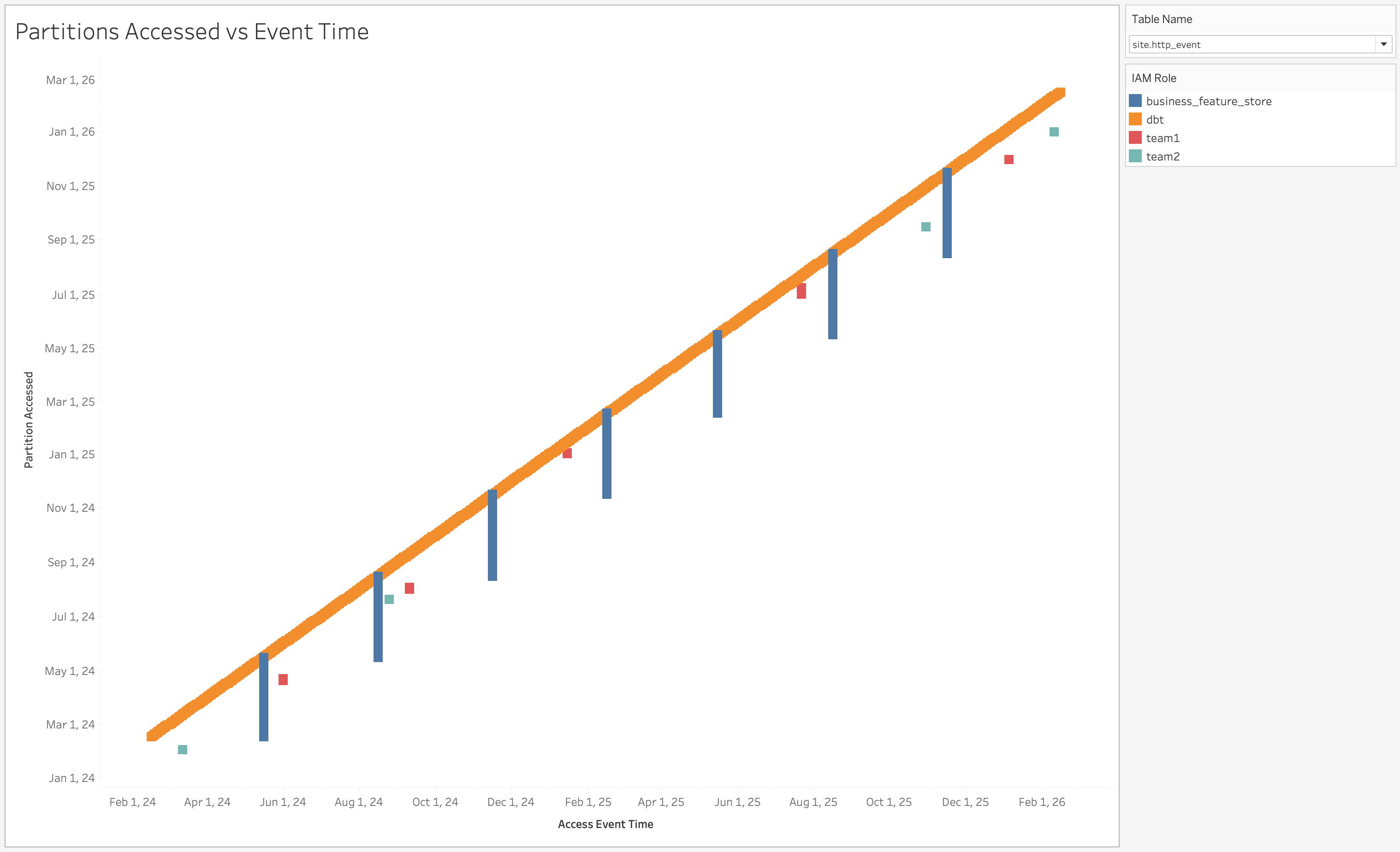
Given an analytics table partitioned by date (dt=yyyy-mm-dd), we can plot partitions accessed against event time.
- Daily batch consumers present a diagonal line showing y=x. Today’s job reads today’s partition, yesterday’s job reads yesterday’s partition, and so on.
- Backfill events that scan many partitions present a vertical line.
- Ad hoc queries appear as scatter points with no clear pattern. We commonly see this type of access from roles attributed to internal engineering teams – often inspecting data to confirm it meets expectations.
We include the entity accessing the data in the visualization. Since Yelp runs on AWS, our entities are IAM roles, with role names linked to services or teams.
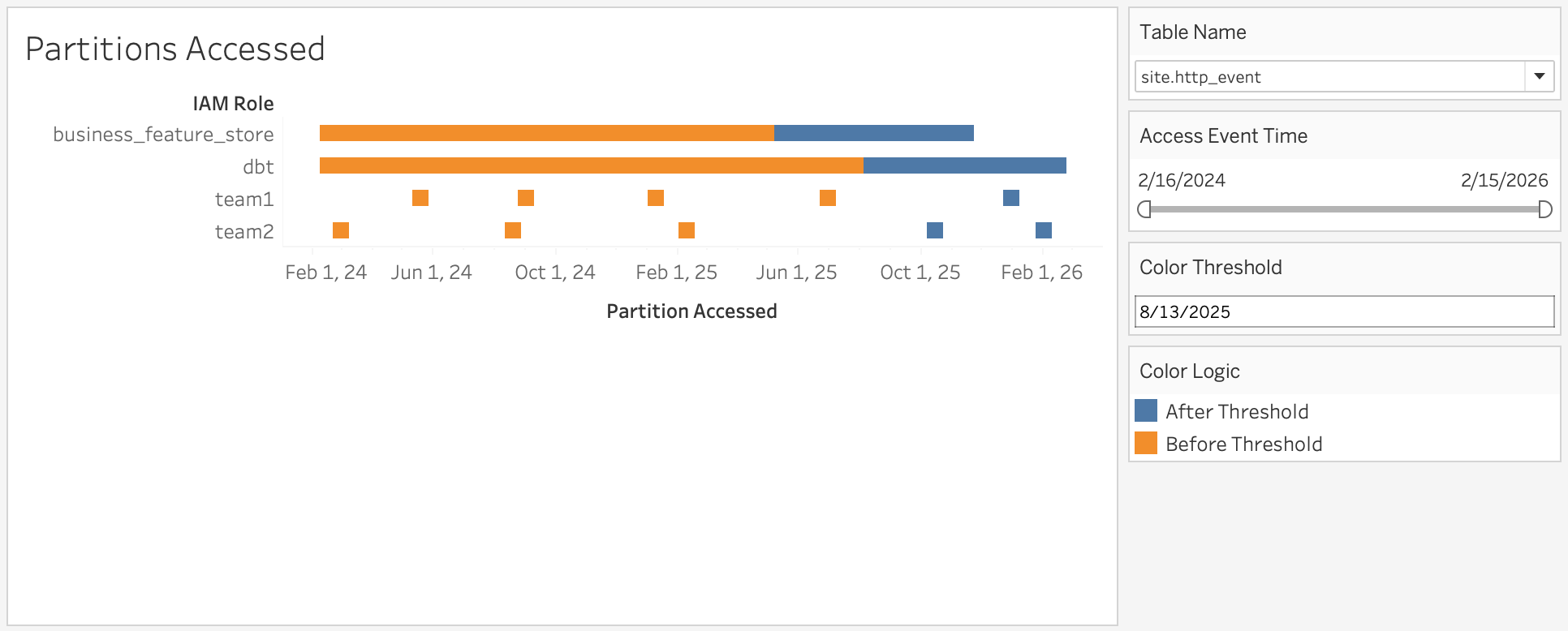
Data owners are also usually interested in access patterns over time such as “what are the access patterns for table X in the last N months?”. A second visualization answers this question:
What Were Our Goals?
We set out to identify active tables and partitions to prioritize our adoption of Apache Iceberg, but we soon realized that the opportunity was larger: partition-level usage data would deliver meaningful improvements across the three main pillars of a platform team:
- Customer value: Data platform users received a new feature to definitively track table consumers and usage patterns, giving data owners confident answers about who consumes their tables
- Business value: Usage attribution enabled the platform team to recommend more efficient S3 Storage Classes and further encourage deletion-based retention policies. This effort made our data lake significantly more cost-effective – reducing S3 storage cost by 33%.
- Platform efficiency: By identifying the most frequently accessed data, the data platform team was able to focus our migration efforts on active tables and partitions that would add the most customer value. This enabled the team to provide Apache Iceberg’s read performance benefits to the most valuable use cases first.
Storage Cost Effectiveness
Without well-defined access patterns, it can be difficult for data owners to further increase deletion-based retention due to the possibility of changing requirements. Similarly, it can be difficult to commit to cold storage policies when the cold storage product has minimum storage durations and per-access fees.
We found that granular usage data enables teams to confidently make these decisions. This granular data enabled expansion of deletion-based retention and more cost-effective S3 Storage Classes, resulting in a 33% reduction in our S3 storage cost.
Leveraging S3 Storage Classes with Known Access Patterns
We default to S3 Intelligent Tiering when datasets have unpredictable access patterns. Its key advantage is that cost scales down automatically with reduced access, and there is no penalty if access patterns change. This is in contrast to cold storage classes (e.g., S3 Glacier) that impose minimum storage durations and retrieval fees that can negate savings if you access data more than you expected to.
Savings from S3 Intelligent Tiering can be significant: objects not accessed for 30 days decrease in cost by 40%; objects not accessed for 90 days decrease in cost by 81%. The latter approaches the cost of S3 Glacier!
With granular usage data revealing actual access patterns, data owners were able to confidently assign more cost-effective storage classes to their analytics tables.
Default Access Retention
We introduced a middle ground for cases where data owners could not further expand deletion-based retention or cold storage due to uncertain future requirements: define an expected access window and implement access-based retention.
Data beyond the Default Access Retention period remains in S3 but is gated behind a restrictive S3 bucket IAM policy that requires an explicit process to gain access. The data consumer raises a Terraform PR to request temporary access to restricted partitions and estimates the associated cost using a dashboard built on S3 Inventory. The dashboard estimates the cost of access using the amount of data in scope and the current S3 Storage Classes. Certain approval levels are required based on the magnitude of the cost. This has the following benefits:
- Unexpected or accidental query patterns do not reset the flow of objects through Intelligent Tiering tiers. Storage cost is guaranteed to decrease after the initial 30 day period of Intelligent Tiering.
- Data consumers acknowledge associated costs of reading data from cold Intelligent Tiers, ensuring that it is justified by the business value of the analysis. If a consumer accesses a partition that is beyond the Default Access Retention period, their query fails with an Access Denied exception.
- For our largest tables, full table scans could add significant S3 costs by accessing PBs of data from cheap Intelligent Tiers like Archive Instant Access. This is not obvious to users who are writing SQL to inspect data!
Usage Attribution Implementation
Since Yelp runs on AWS, the usage attribution system is built on Amazon S3 server access logging. Check out our Engineering Blog post on S3 server access logs to learn how to enable this cost-effectively at scale. With server access logs available in a data lake table, we can use a SQL engine to aggregate usage data per table, partition and entity (IAM role).
Our batch-driven architecture is described below:

A high-level overview of the SQL transformation:
INSERT INTO table_usage_aggregated
SELECT
COUNT(1) AS ct,
requester AS iam_role,
"timestamp" AS event_time,
KEY_TO_TABLE_NAME(key) AS table_name, -- Change to function relevant to your data storage structure
KEY_TO_PARTITION_VALUE(key) AS partition_value -- Change to function relevant to your data storage structure
FROM
s3_server_access_logs_compacted
WHERE
bucket_name IN ('BUCKET1', 'BUCKET2') -- Change to your bucket names
AND "timestamp" = 'yyyy/mm/dd' -- Access event time
AND operation = 'REST.GET.OBJECT'
AND key LIKE 'prefix_to_include%'
GROUP BY
2, 3, 4, 5
Instead of functions KEY_TO_TABLE_NAME and KEY_TO_PARTITION_VALUE, you may join against your catalog metadata containing database name, table name, table location, and partition spec.
You may find it additionally useful to join against S3 Inventory to understand how usage relates to the defined storage classes for your analytics tables.
Conclusion
By building partition-level access visibility into our data platform, our data platform team was able to move faster on migrating active analytics data to Iceberg, strengthen data stewardship practices at Yelp, and deliver significant cost efficiencies to our petabyte-scale data lake. If you store analytics data at scale, you may also benefit from this approach. Inspired by the success of this effort, we are investing in other areas of our data infrastructure to further enhance lineage and granular usage attribution.
Acknowledgements
Thanks to Rishi Madan for contributing to the development work in this effort, Yelp’s Infrastructure Security team (Vincent Thibault, Quentin Long, Nurdan Almazbekov) for enabling S3 Server Access Logs across Yelp’s AWS infrastructure, and to all of the teams owning large analytics tables who collaborated on this effort.
Join Our Team at Yelp
We're tackling exciting challenges at Yelp. Interested in joining us? Apply now!
View Job