Lessons from A/B Testing on Bandit Subjects

-
Shichao Ma, Applied Scientist
- Dec 21, 2022
Abstract Compared to full-scale ML, multi-armed bandit is a lighter weight solution that can help teams quickly optimize their product features without major commitments. However, bandits need to have a candidate selection step when they have too many items to choose from. Using A/B testing to optimize the candidate selection step causes new bandit bias and convergence selection bias. New bandit bias occurs when we try to compare new bandits with established ones in an experiment; convergence selection bias creeps in when we try to solve the new bandit bias by defining and selecting established bandits. We discuss our strategies to mitigate the impacts of these two biases.
We have many multi-armed bandits running at Yelp. They help us select the best contents we show on our webpage, choose the optimal ad rendering format on our app, and pick the right channel and timing to reach our users and business owners.
We typically use the Thompson Sampling method. Thompson Sampling is a Bayesian method that combines the domain knowledge we have via prior distributions and the real-world observations we collected for each arm. It is easy to understand for broader audiences and simple to implement. It also introduces noises throughout the day even though our bandits are typically updated nightly. Compared to its alternatives, research has shown that it performs better in the real world (Chapelle and Li 2011).
Compared to machine learning (ML) models or ML based contextual bandits, simple multi-armed bandits1 (bandits henceforth) have several important infrastructural and logistical advantages:
- Code light: our bandit implementation is a Python function with only a couple of lines. At serving time, user teams only need to pass in the prior distribution and the real observations of each arm as a dictionary.
- Setup light: compared to serving a model, bandits do not require a separate service call to make predictions. Typically user teams only need to set up a Cassandra table that stores past observations. Past observations can be computed via a nightly batch and piped into the aforementioned Cassandra table.
- Resource light: unlike models, bandits do not require features to learn. This means the product owner does not need to staff a sizable team building a feature engineering pipeline and researching the model architecture.
- Maintenance light: bandits do not need heavy monitoring and alerting because it has no complex dependency. By design, bandits balance exploration and exploitation gracefully. With an appropriate data retention window, bandits can also handle data drifts without human intervention. From our experience, for bandits to work correctly, the oncall person only needs to ensure the bandits are updated correctly, which typically is a light task.
Because of these advantages, bandit is a sweet spot for many teams to try out before they fully commit to ML. For some applications, the bandit performance may be good enough such that teams choose to stay in the bandit world.
A seemingly minor drawback
As with all the good things in life, bandits do not come without drawbacks. One drawback we face is the difficulty of handling too many items (the curse of dimensionality). When having too many arms, the exploration requires too much data and takes too long from a practical perspective.
A common practice to mitigate this issue is performing a candidate selection step and sending only top results to the bandit. The candidate selection step can be anything from a simple heuristic, a rule based formula, to a simple model, or a hybrid of all. We only require it to be mostly stable day to day so that bandit’s historical learnings are still useful today. Because of such freedom, a lot of work can be done to optimize the candidate selection step.
This seemingly innocuous candidate selection step causes many challenges when it comes to A/B testing different candidate selection models. To show this point, let’s first materialize the case of advertising photo selection as an example.
When advertisers choose “Let Yelp optimize” for their advertising photos, we test different photos and learn which one gets the most clicks. Under the hood, this is achieved by a bandit system. In particular, each pull is an impression while each success is a click. We use the standard Beta-Bernoulli Bandit with K arms (K is a small fixed number). Because many advertisers simply have too many high quality images for the bandits to learn within a reasonable time window, we have a candidate selection step before the bandit.
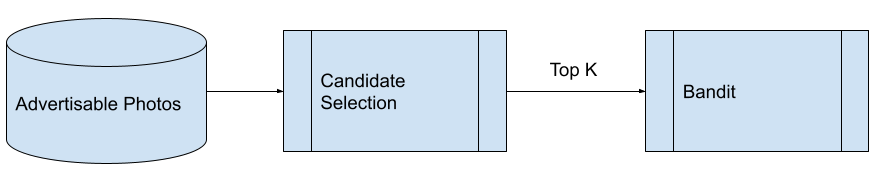
A high level summary of Yelp’s advertising photo selection pipeline
For the illustration purpose, let’s assume the status quo candidate selection method is a rule based formula while the challenger is a light-weight model trained on some pre-computed image embeddings. Because these two approaches are quite different, they typically produce distinct top K images.
To verify the new model selects better performing candidates, we set up an A/B experiment diverted by advertiser_id.
If we stop here and naively run this experiment as is, we may reach a false conclusion caused by the new bandit bias.
New bandit bias
Let’s examine the following mock up example. In this example, the top 3 photos produced by the status quo rule are (1, 2, 3) while the top 3 photos resulted from the new model are (4, 5, 6). Let’s assume that the true click-through rate (CTR) of 1, 2, 3 are 0.2%, 1.5%, and 1.0% while the true CTR of 4, 5, 6 are 0.3%, 2.0%, 1.0% respectively. So the new model is superior by construction.
However, because the bandit has no data about (4, 5, 6), it has to start from scratch. In particular, at the beginning of the experiment, the bandit will evenly allocate impressions to all three. On the contrary, the bandit in the status quo cohort has figured out photo 2 is the best among (1, 2, 3) and most traffic is allocated to photo 2 already. The following table shows a possible scenario on day 1 of the experiment. Notice on day 1 the CTR of the status quo group is 1.3% but the treatment group is only 0.9%. The bandit will eventually figure out photo 5 is a better performing one and allocate more traffic to it. But until then, the treatment will continue to underperform.
| photo_id | True CTR | Cohort | Day 1 impressions | Day 1 clicks | Observed CTR |
|---|---|---|---|---|---|
| 1 | 0.2% | Status Quo | 40 | 0 | 1.3% |
| 2 | 1.5% | 356 | 5 | ||
| 3 | 1.0% | 61 | 1 | ||
| 4 | 0.3% | Treatment | 161 | 0 | 0.9% |
| 5 | 2.0% | 149 | 3 | ||
| 6 | 1.0% | 147 | 1 |
What if we wipe out the bandit history in the status quo group as well before the experiment? This indeed is the cleanest way to compare the two groups, but we will nuke the performance of the whole system, which typically is not acceptable from a business perspective.
What if we remove bandits from the equation during experimentation since we’re comparing the candidate selection methods? This idea does not work. The treatment is the middle step of the system but the success metric is defined only after the bandit does its magic. Because we don’t know which photo will give us the highest CTR a priori, we cannot remove the step that is designed to find the highest CTR. In other words, our experimentation subject has to be the whole system, bandit included.
Some bandits will have more data and hence learn faster than others. In practice, we typically observe a big performance plunge from the treatment group at the beginning but it will be gradually improving throughout the experiment. The real difficulty is to tell when the new bandit bias is small enough such that we can attribute the difference between treatment and control groups to our new model.
In summary, the first lesson we learned is that bandits need to be converged to be comparable. So we came up with a definition of convergence such that when a bandit is declared converged, it won’t cause major new bandit bias.
The 80-80 rule of convergence
Intuitively, if a bandit is considered converged, it must be done with exploration and be mainly working on exploitation. We believe this intuition can be further broken down into two subdimensions:
- If there’s a clear best performing arm, then the bandit has found it.
- If the bandit can’t distinguish multiple arms, then the bandit must have enough evidence to show they have similar enough performance.
Notice for the bandit to move on to exploitation, it does not need to exactly pinpoint the performance of each arm. For worse performers, knowing “they are worse” is enough.
Inspired by the Upper Confidence Bound algorithm, we use confidence intervals2 (CI) of posterior distributions to define convergence. Our definition of convergence for advertising photo selection is as follows. Note that this definition is not necessarily appropriate for your case. But you can use it as an inspiration.
- Compute the 80% CI of the posterior distribution for each arm.
- Apply the merge interval algorithm (see, e.g., LeetCode 56) on 80% CIs. That is, put all arms into one group if their CIs have some overlap. If there is no overlap, then the arm is its own group.
- Rank the groups by their posterior means. This ranking is well defined because all groups are separated after the previous step.
- [80% CI no overlap] Examine the group with the highest CTR (top group henceforth). If the top group has only one arm for the past 7 days, then we call the bandit converged.
- [80% CI width drop] Otherwise, if all CIs in the top group are less than 20% width of the prior distribution’s CI for the past 7 days, then we call the bandit converged.
- Once the bandit is considered converged, its data may be used for analysis purposes starting from the next day.
The 80% CI no overlap rule captures the case when there is a clear winner. Based on our experience, once any arm’s 80% CI is separated from others, the underperforming ones stop receiving much traffic even if their performance estimates still contain much uncertainty (a.k.a., knowing “they are worse” is enough).
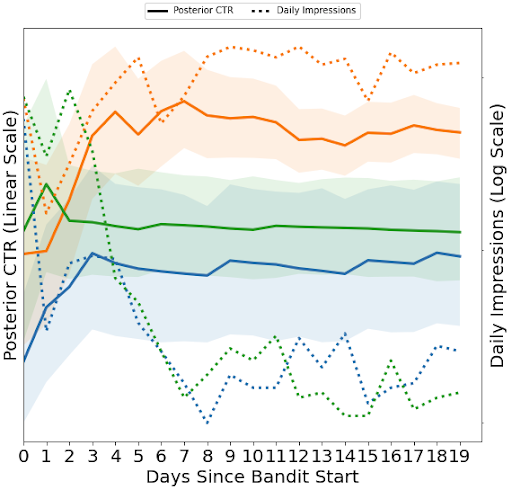
The posterior and traffic plot of a newly created bandit that converged under the 80% CI no overlap rule. The solid lines are posterior CTRs of photos and the shaded areas are their corresponding 80% CIs. They are plotted on the linear scale. The dotted lines are impressions the bandit allocated to each arm, in log scale. In the initial phase, the bandit is mostly working on exploration so each arm gets a decent amount of traffic. On day 7, the orange arm’s CI is separated from other arms’ and the other arms only receive about 1-5% of the traffic.
The 80% CI width drop rule captures the case where the difference between multiple arms are not practically significant. In this case, bandits will continue to allocate traffic to all arms in the top group so typically the CI width drop in the top group is fast.
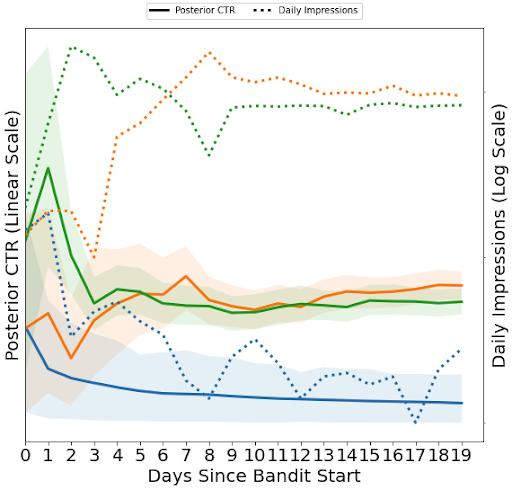
The posterior and traffic plot of a newly created bandit that converged under the 80% CI width drop rule. At day 5, the green & orange arms’ CIs are separated from the blue arm’s. While the bandit stops allocating traffic to the blue arm, the bandit cannot significantly differentiate the green and orange arms so both continue to receive significant traffic.
Under our definition, the new bandit bias is usually of a smaller magnitude than our usual effect size. Moreover, a usual t-test cannot distinguish newly converged bandits and fully converged bandits permitted by data retention period.
Convergence selection bias
Unfortunately, even though it may help reduce the new bandit bias, just applying the definition of convergence introduces another bias: convergence selection bias. To explain this bias, let’s consider the following example.
| advertiser_id | Cohort | Observed CTR | Is Converged | Average CTR of Converged Bandits |
|---|---|---|---|---|
| 1 | Status Quo | 0.7% | Yes | 1.0% |
| 2 | 1.4% | Yes | ||
| 3 | 0.9% | Yes | ||
| 4 | Treatment | 0.8% | Yes | 0.9% |
| 5 | 1.5% | No | ||
| 6 | 1.0% | Yes |
This example is constructed such that treatment has a superior performance. Notice all bandits in the status quo cohort are converged because they have been collecting data for a longer period while only some bandits are converged in the treatment cohort as they are shorter lived. If we compare average CTR of converged bandits in the two groups, then we would falsely conclude that the treatment is doing worse.
You might dismiss this example since we conveniently mark the best performing bandit unconverged and remove it from comparison. This is not the case; it is a real concern. If we apply the bandit convergence algorithm, then the converged bandits will typically NOT be representative of the whole population. Converged bandits are associated with more traffic in general, and more traffic is associated with more advertising budget, certain advertiser types, more densely populated geolocation and probably some other unknown factors. Because of these factors, the treatment and control balance no longer holds and we re-introduce confounding into a randomized experiment.
Formally, we are running into the selection on post-treatment variables issue. That is, in the analysis, we pick samples based on variables that may be affected by the treatment in some unknown way. Such variables may be correlated with the outcome variable in some unknown way. Therefore, the selected sample for analysis is, in some sense, cherry picked, which is absolutely not okay in experiment analysis. Moreover, because we have to define convergence based on post-treatment variables, in general we cannot get around the post-treatment selection with any definition of convergence.
Coming up with an experimental design
We may frame the convergence selection bias as a form of missing data bias: the data from the unconverged bandits are missing. Therefore, we can draw some insights from the missing data literature.
After doing some literature review, we conclude that a carefully implemented matched pair design with pairwise deletion can help minimize the bias in this situation. In particular, King et al’s (2007) matched pair design insulates their policy experiment from certain selection bias of missing data. Fukumoto (2015) examined the missing data bias in detail for matched pair design. According to Fukumoto, pairwise deletion has a smaller bias compared to all other methods. Imai and Jiang (2018) developed a sensitivity analysis that provides a bias bound for the matched pair design.
We combined the recommendations from these papers. Our matched pair design with pairwise deletion and sensitivity analysis goes as follows:
- Compute the feature set with respect to the population of interest. In the advertising photo selection case, we actually can get this step for free because Yelp has other ML feature pipeline running for advertisers.
- Match subjects as much as possible. Two advertisers in the same pair should have the same value for categorical variables. For numerical values, we may use Mahalanobis distance for their matching. After this step, all observed confounders are accounted for.
- Within the same pair, apply treatment to one subject and control to the other randomly. This step is to randomize the unobserved potential confounders.
- Apply pairwise deletion. That is, if both bandits in a pair are judged converged, add them into the analysis pool; otherwise drop both from the analysis.
- In the event of advertiser churn, perform pairwise deletion as well.
- Perform sensitivity analysis as in Imai and Jiang (2018) Section 2.4, Theorem 3.
Unfortunately, this design is no panacea. First, as stated in Fukumoto (2015), the matched pair design can help reduce the bias, but it cannot guarantee bias free.
Second, the result we get after pairwise deletion is not an estimate of the average treatment effect. The pairs that have little chance to converge within the experiment window are less represented in the final analysis pool and hence we count their treatment effects less. Formally, the pairwise deletion estimand can be interpreted as a weighted average treatment effect, where the weights are the relative ex ante probability of convergence. But in practice, it means it is difficult to communicate how much effect we can expect if we ship the experiment to the whole population.
Third, this design is complicated and time consuming to perform. So in our work we actually do not perform it unless we have to. Because of the new bandit bias, a negative is not necessarily a true negative but a positive is a true positive. So if a vanilla A/B experiment read (dropping the early period) provides a positive finding already, then we will conclude and ship the experiment.
Conclusion
Compared to full-scale ML, multi-armed bandit is a lighter weight solution that can help teams quickly optimize their product features without major commitments. However, because of its inability in handling high cardinality, we have to couple bandits with a candidate selection step. This practice creates two biases whenever we want to improve the candidate selection step: new bandit bias and convergence selection bias.
Our current recommendation to experimental design has two components: a 80-80 definition of bandit convergence and a matched pair design with pairwise deletion. The former reduces the new bandit bias and the latter minimizes the selection bias. Working together, they deliver a successful A/B experiment on bandit subjects.
References
- Chapelle, Olivier, and Lihong Li. “An empirical evaluation of Thompson sampling.” Advances in neural information processing systems 24 (2011).
- Fukumoto, Kentaro. “Missing data under the matched-pair design: a practical guide.” Technical Report, Presented at the 32nd Annual Summer Meeting of Society for Political Methodology, Rochester, 2015.
- Imai, Kosuke, and Zhichao Jiang. “A sensitivity analysis for missing outcomes due to truncation by death under the matched‐pairs design.” Statistics in medicine 37, no. 20 (2018): 2907-2922.
- King, Gary, Emmanuela Gakidou, Nirmala Ravishankar, Ryan T. Moore, Jason Lakin, Manett Vargas, Martha María Téllez‐Rojo, Juan Eugenio Hernández Ávila, Mauricio Hernández Ávila, and Héctor Hernández Llamas. “A “politically robust” experimental design for public policy evaluation, with application to the Mexican universal health insurance program.” Journal of Policy Analysis and Management 26, no. 3 (2007): 479-506.
Acknowledgements
The content of this blog is a multi-year effort and we have lost track of all our talented colleagues who have contributed to this problem space. An incomplete list of contributors (with a lot of recency bias) is: Wesley Baugh, Sam Edds, Vincent Kubala, Kevin Liu, Christine Luu, Alexandra Miltsin, Alec Mori, Sonny Peng, Yang Song, Vishnu Sreenivasan Purushothaman, Jenny Yu. I also thank Marcio Cantarino O’Dwyer for reviewing and helpful suggestions.
Notes
1: Multiple simple bandits and a lookup table based finite state contextual bandit are equivalent. For example, if we set up a simple bandit for each advertiser, it is equivalent to setting up a contextual bandit with the context vector being onehot(advertiser_id). On the contrary, having a lookup table based contextual bandit is equivalent to setting up one multi-armed bandit per state. Therefore, we do not distinguish them in this blog post.
2: Technically, we should use the term credible interval. But we maintain the terminology confidence interval because, in this context, the difference between the two only introduces unnecessary complications to people who are less familiar with Bayesian statistics.
Become an Applied Scientist at Yelp!
Are you intrigued by data? Uncover insights and carry out ideas through statistical and predictive models.
View Job