Modernizing Ads Targeting Machine Learning Pipeline

-
Rahul Dubey, Machine Learning Engineer
- Jan 30, 2020
Yelp’s mission is to connect users with great local businesses. As part of that mission, we provide local businesses with an ads product to help them better reach out to users. This product strives to showcase the most relevant ads to the user without taking away from their overall search experience on Yelp. In this blog post, we’ll walk through the architecture of how this is made possible by using one of the largest machine learning systems at Yelp: Ads Targeting System.
The Ads Targeting System is a machine learning (ML) system designed to serve only the most relevant ads to users based on their intentions and context on Yelp. There are two primary types of ML models in the ads targeting domain: Click Through Rate (CTR) prediction, and Objective Targeting (OT). Both help determine the likelihood of downstream actions, such as calling a business after clicking on an ad.
In this post, we’ll primarily focus on architecting ML systems at scale rather than on algorithmic details or feature engineering. For more info on the algorithmic side of our CTR prediction model, check out one of our previous posts where we discuss optimizations made to the XGBoost prediction library.
Historical Context on Ads Targeting System
Below is a simplified version of the Ads Targeting and Delivery System:
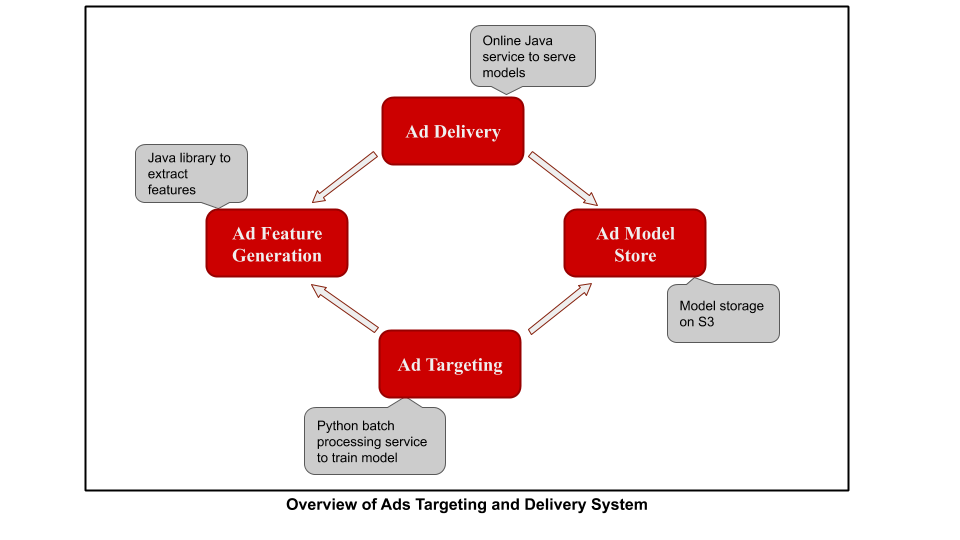
The Ad Delivery service is a low-latency online service written in Java that processes incoming ad requests. It generates features for the incoming request using the Ad Feature Generation library, loads the model from the Ad Model Store, generates CTR prediction, and then ranks ads accordingly.
The Ad Targeting service is a batch processing service written with MR Job: Python Map-Reduce library open-sourced by Yelp. This is the service that we’ll discuss and redesign in this blogpost. Its main features include processing logs using the same Ad Feature Generation library, training ML models, and storing them in the Ad Model Store. MRJob also comes with a feature that allows you to call Java code from Python to carry out map reduce operations (as can be seen here). Using the same Feature Generation library ensures that all feature computation, both on and offline, remains consistent.
This blog post on CTR prediction illustrates how the Ads Targeting Machine Learning Pipeline used to look:
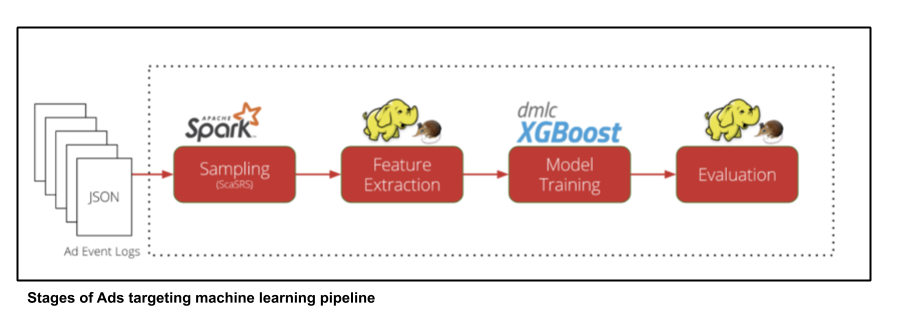
We processed Ad Event JSON logs, downsampled them in Spark, and extracted features from the set of logs with Hadoop MR jobs. We then proceeded to Model training with XGBoost and model evaluation with Hadoop MR jobs using AWS EMR as the compute infrastructure. This pipeline served us well and helped us iterate in an ad hoc fashion to create newer and better ad targeting models. That being said, we did face several issues as the system matured due the following:
- As all stages of the pipeline were closely coupled, failure in any of the intermediate steps required restarting the pipeline
- This close coupling also meant that changing the feature generation logic or sampling strategy required running the entire pipeline
- The pipeline was closely linked with certain EMR instance types and AMI images that restricted either our upgrade to newer versions of Java or trying newer EMR instances (e.g., upgrades in other Java dependencies and online Java services wouldn’t work with the current Ad targeting service, making it impossible to retrain a model or add a new feature)
- As our system matured and we started adding more models to our ads targeting system, the cost of training grew
Redesigning the Ads Targeting Pipeline with Spark
To solve the above issues, we decided to re-architect the Ad Targeting Service and its interaction with the other main components of the Ad Targeting and Delivery Systems. Keeping an eye on the big picture and setting goals is very important when re-designing a system as large as this. For us, that meant focusing on:
- Making it easy to retrain existing models
- Making feature generation cheaper, easier, and faster
- Leveraging Yelp’s internal Spark tooling and infrastructure (rather than relying on EMR)
- Improving monitoring and alerting, and providing easy promotion of models in production
We decided to use Spark as the underlying engine for this ML system as it allowed us to leverage our own in-house Spark on Mesos infrastructure. This infrastructure provides us with a quick and cheap way to spin up clusters and get started with writing big data workflows. Moreover, moving away from Hadoop map-reduce jobs on EMR increased speed and cut costs. This, coupled with the availability of PySpark (the official Python API for Spark), made the decision even easier, since most of our code and infrastructure is built with Python.
Armed with better infrastructure and tooling around Spark and its natural fit to our big data ML use-case, we decided to rewrite the Ads Targeting Service in PySpark. The new service now contains the same stages as before: Sampling -> Feature generation -> Training -> Evaluation, just with all the stages computed with PySpark.
Overview of Modernized Architecture Based on Spark
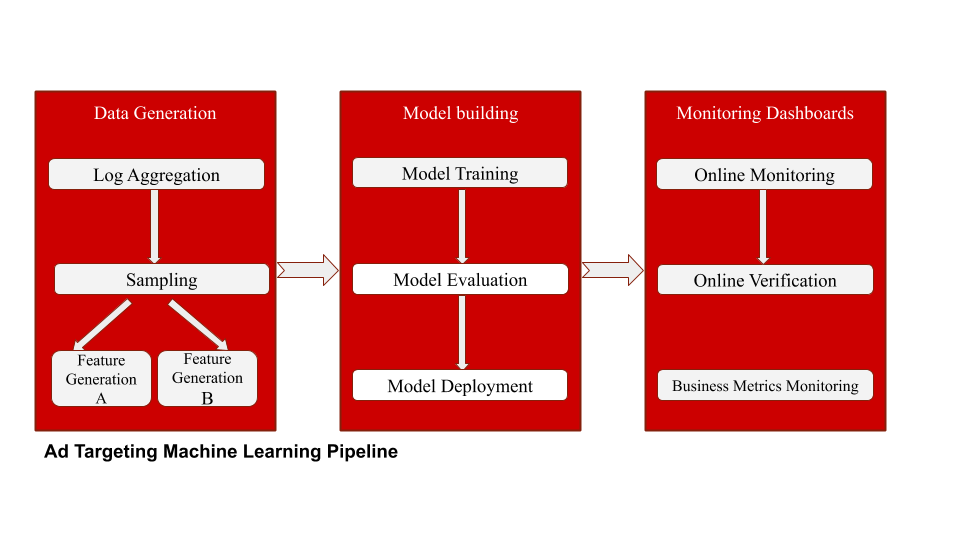
Above is the current machine learning pipeline powered by the updated Ad Targeting Service. Three significant changes were made here:
Use Spark as the Compute Infrastructure
Spark batches were more efficient both in terms of time and cost. Moving to Spark allowed us to leverage the existing infrastructure at Yelp that enabled us to write ETL jobs and carry out distributed machine learning with XGBoost. This was a very cost-effective move since now we only pay for spot EC2 compute resources (and not for the EMR stack on top of it!).
Decouple the ML Pipeline into Stages
The batches we created process logs, perform sampling, and generate features that are scheduled to run daily and checkpoint results on S3. Decoupling these batches gave us flexibility: we now have different feature generation strategies on top of the same sampling output, whereas in the older architecture each new feature generation strategy required re-computing sampling output. It also made the system relatively robust; since failure in later stages (say training/evaluation) didn’t disrupt the whole pipeline, engineering and operating costs were reduced.
Automated Monitoring and Alerting
We leveraged Yelp’s modernized Data Landscape (1, 2, 3) and built our monitoring capabilities on top of this infrastructure. Instead of manually running Jupyter notebooks to monitor metrics, we computed these in batches, loaded them to our AWS Redshift data warehouse, and created Splunk dashboards on top of it. This made it really easy for PMs and engineers to make model promotion/deployment decisions.
Feature Generation with Java and PySpark
The online Ad Delivery Java service and the offline Ad Targeting Python service share the same Ad Feature Generation Java library. From there the question then arises: how are we leveraging PySpark to generate features? Hint: What language is Spark written in? Let’s unpack this!
DataFlow in PySpark:
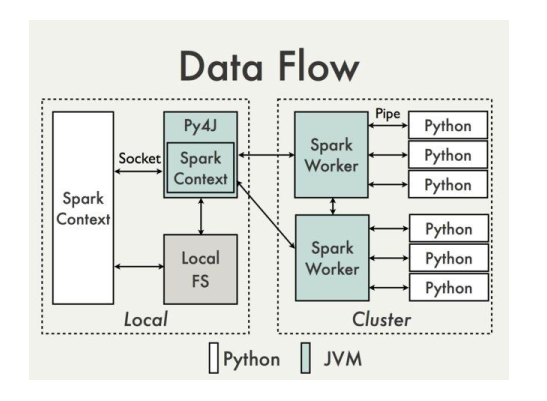
Spark is written in Scala (a JVM language), and PySpark is a Python wrapper on top of it. PySpark relies on Py4J to execute Python code that can call on objects that reside in the JVM. To do that, Py4J uses a gateway between the JVM and the Python interpreter, and PySpark sets it up for you with SparkContext. This SparkContext has access to the JVM and all packages and classes known to the JVM. You can see where this is heading…
To carry out distributed feature generation via PySpark, all we had to do was add our feature generation JAR to the Spark JVM and use SparkContext to refer to these classes. Since Yelp executes Spark within Docker, we added the JARs to our service’s Docker images, then loaded the image in Spark drivers and executors. We then had a feature generation Java library accessible via PySpark! The diagram above, taken from the PySpark Wiki, illustrates the above design. As you can see, Py4J essentially carries out all data communication with the JVM.
Implementation:
You can imagine a simple example of a Java class with a method that prints “Hello World!” that is then called from PySpark to get the printed string: “Hello World!”. This implementation was illustrated in this blog (in Scala, but the same principle applies for Java), so we won’t get into it here. Instead, we’ll demonstrate how to apply this principle to our use-case.
Say we have some JSON logs containing information about ads that can be read in PySpark as PythonRDD. Now, we want to extract/transform features from these logs using our Java library. One way of doing this is via Java UDF (as is illustrated here). However, there’s a limitation to this approach: it requires Java classes to have a zero-argument constructor. This can be seen in the official Spark UDF Registration code. Since for our use case we wanted to have the ability to parameterize our classes, this approach didn’t work for us.
Hence, we went with the following: first, we created a Java class that extends flatMapFunction interface. This allowed us to generate any number of output rows per row of the input RDD by passing an object of this class to Spark’s mapPartitions function. The Java class also gets a list of Java mappers that we want to apply to the input RDD to generate the output fields. One of these Java mappers calls into the feature generation library to extract the transformed features. The library itself essentially consists of simple Java classes that can extract features by applying simple transforms or business logic on raw JSON logs.
Now that we have all the Java classes ready, we can do the following on the Python side:
from pyspark.mllib.common import _java2py
from pyspark.mllib.common import _py2java
# Step 1: First convert the PythonRDD object into a java RDD object.
java_rdd_object = _py2java(python_rdd.ctx, python_rdd)
# Step 2: Get the Java class that implements flatMapFunction interface, initialize it,
# and pass some mappers to it to apply on the Java RDD
java_flat_map_function_object = flat_map_function_package.ClassWithFlatMapFunctionInterface(
initParamA,
initParamB,
[
MapperA(arg_a),
MapperB(arg_b),
MapperForFeatures(),
MapperForLabels()
]
)
# NOTE: As one can see above, we can parameterize our mappers as opposed to JavaUDF functions
# Step 2: Call mapPartitions on that java object (effectively calling java code)
# and get the output as a java RDD instance.
mapped_java_rdd_object = java_rdd_object.mapPartitions(
java_flat_map_function_object
)
# The above mapped_java_rdd_object now consists of results of all the 4 mappers above applied
# Step 3: Convert the java RDD object back into a python RDD object.
mapped_python_rdd = _java2py(python_rdd.ctx, mapped_java_rdd_object)
Voila! Now we have a PythonRDD of features that was generated via the Java feature generation code.
Model Training with Distributed XGBoost on Spark
We use MLFlow-tracking to track and log our model training runs. This provides us with a lot of visibility into our model training metrics, an easy way of logging and visualizing hyperparameters and even sharing the model-training reports. Another cool feature of MLFlow-tracking is the ability to query the model-training runs and retrieve the best models based on metrics. We leverage this feature to automate our evaluation and monitoring pipelines.
To train our ads targeting models, we heavily rely on XGBoost. However, distributed training with XGBoost on Spark took some work to accomplish. Since the official library (version <= 0.9) doesn’t provide a Python/PySpark interface, we wrote our own wrapper on top of XGBoost4J-Spark. We also implemented a SparseVectorAssembler instead of using the VectorAssembler provided by Spark, since the default implementation doesn’t integrate well with XGBoost on Spark (issues dealing with missing values). Another limitation of XGBoost on Spark is that it’s not as fault-tolerant as native Spark algorithms. This becomes an issue when trying to use AWS Spot instances for model training, since at times when the spot instances became unavailable, the training job dies. Thus, we created a separate pool of on-demand resources to carry out large-scale distributed training with XGBoost on Spark.
Automated Retraining, Monitoring, and Alerting
We use Yelp’s Tron scheduler to schedule our batch processing jobs. The entire new pipeline is scheduled via Tron, where log-processing and feature generation batches run daily and model-training runs every few days. Through running A/B experiments, we’ve observed that pure retraining of models with newer data leads to ~1% improvement in our primary metric, which then compounds over time.
While scheduling model retraining is simple, deployment, monitoring and alerting can be a more difficult process. To instill confidence among developers and PMs to go in production with newly trained models, we developed a solid monitoring infrastructure that does the following:
- Daily model evaluation that replays traffic for all models in production and models yet to be deployed in production(this helps us capture model drift and decays)
- Live Splunk dashboards of business, online model, and offline model evaluation metrics
- Scoring verification systems that verify online and offline scoring matches and ensures that features don’t drift between online and offline modes
Having a good monitoring infrastructure improves developer velocity in deploying newly trained models. It’s analogous to having a good CI/CD infrastructure for code deployment.
With this newly designed service and regular retraining-deployment cycle, we’ve seen a vast improvement in our model metrics that has further translated to improving business metrics such as click-through-rate, sell-through-rate, and lower cost per clicks for our advertisers.
This means that we’ve not only improved serving more relevant and useful ads to our users, but have also reduced the cost for our advertisers to serve ads, making Yelp a more cost-effective platform for their business.
Conclusion
- Designing large ML systems is hard due to additional complexities introduced by data and models, but it’s especially important when it’s a big part of your product
- Sometimes ML systems need to evolve (from Hadoop MR to Spark); ML engineers shouldn’t shy away from this just because it’s infrastructure and not modeling
- Decouple system components and checkpoint data often so that each component can be independently worked and improved upon
- Create infrastructure such that training+evaluating+monitoring models are easy and automated. Make this infrastructure instill confidence in developers to deploy newly trained models
- Retraining models with newer data can provide good gains with almost zero effort, so take advantage of it!
Acknowledgements
A huge thanks to engineers from the Applied ML, Core ML, and Ads Platform teams, without whom such a broad cross-team collaborative effort wouldn’t have been possible. Credit to the contributors: Chris Farrell, Jason Sleight, Aditya Mukherjee, Abhy Vytheeswaran, Vincent Kubala.
Become a Machine Learning Engineer at Yelp
Want to build state of the art machine learning systems at Yelp? Apply to become a Machine Learning Engineer today.
View Job