Overview of JupyterHub Ecosystem

-
Manpreet Singh, ML Compute Tech Lead
- Jul 25, 2023
At Yelp, Apache Spark and JupyterHub are heavily used for batch processing and interactive use-cases, such as in building feature models, conducting ad-hoc data analysis, sharing templates, making on-boarding materials, creating visualizations, and producing sales reports.
Our initial deployments of Jupyter at Yelp were iPython notebooks managed at an individual level. Later on when Jupyterlab was released (2018), our notebook ecosystem was extended to Jupyter Servers running on dev boxes, which was managed by individual engineering teams. Over time with growing use-cases and data-flow, this introduced unnecessary version variability, became error-prone due to the number of manual steps, caused config duplicacy, lacked comprehensiveness in resource usage and cost monitoring, created security issues, and added maintenance overload at an organizational level.
In this blog post, we will discuss the evolution of our Jupyterhub ecosystem which is now managed by a single team and presents an easy to use, scalable, robust, and monitored system for all engineers at Yelp. This blog will focus on each major component as part of the ecosystem and describe its purpose and evolution over time. Finally, we will illustrate the evolution of all the components in a unified chronological order in a diagram.
JupyterHub Ecosystem: An Introduction
The Yelp JupyterHub ecosystem encompasses JupyterHub, our internal notebook archiving service Folium, Papermill, Spark on PaaSTA, and a Spark Job Scheduling Service (e.g. Mesos or Kubernetes). We solved many of our problems through a combination of novel feature development, extension integrations, and migrations of infrastructure components, all while trying to maintain minimal impact to existing Jupyter workflows. The diagram below shows the most common workflow for a user to launch a notebook and upload it to Folium.
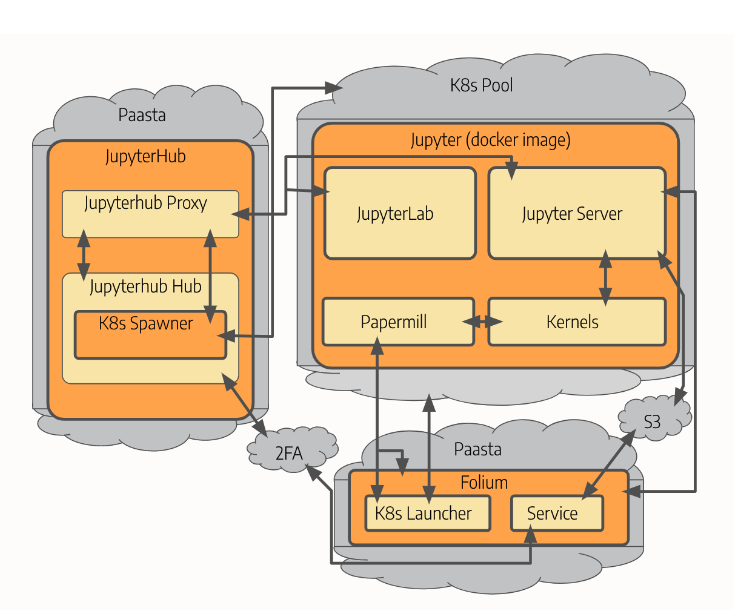
High-level Architecture of JupyterHub Ecosystem at Yelp
Scale: Over the years, we have scaled our usage of the JupyterHub ecosystem to several teams owning thousands of batches. To put this into perspective, Spark batch runs have doubled every year, almost following Moore’s law. As of today, over 100 service owners own more than 1200 batches and hundreds of Jupyter and Folium notebooks are executed daily. These run across different underlying hardware (EMR, gpu, spot, on-demand), processing billions of messages and terabytes of data on a daily basis.
Underlying Infrastructure Evolution
Jupyter notebook usage started at Yelp through users launching notebook servers from within a service virtual environment on individual dev boxes. As mentioned earlier in this post, as the scale of usage of our ecosystem increased, it brought a bunch of challenges, making it harder to manage use-cases at an organization level.
As a result, our Spark and JupyterHub infrastructure went through a plethora of migrations to adapt to newer technologies. The chronological stages of the migrations are as below:
- The Jupyterhub setup used as part of individual dev boxes was later extended by running team based Jupyterhub instances on team dev boxes, which utilized the open source docker spawner to launch user servers. This led to teams sharing a common shared infrastructure without a single user having to maintain and set-up their own servers.
- A Centralized JupyterHub Ecosystem was built which ran on top of PaaSTA. We started with launching and managing our Jupyter notebooks using marathon spawner. Spark Cluster used a Mesos scheduler to launch its executors. This meant a single team was able to manage the JupyterHub ecosystem, while also providing a single point of entry for launching Spark sessions integrated with PaaSTA infrastructure.
- We then adopted a more industry-wide and well-maintained open-sourced orchestration platform, Kubernetes.
- The initial phase involved launching Jupyter notebooks with the aim of moving away from Marathon Spawner in favor of using Kubespawner. At this stage, Spark jobs launched on Jupyter notebook ran Spark drivers on Kubernetes while executors were still running on Mesos. Moving to Kubespawner opened doors for many features. It provided smarter bin packing, centralized management, and improved monitoring of Jupyter nodes inside a Kubernetes cluster.
- The next phase involved migration of Spark schedulers running executors from Mesos over to Kubernetes. This took us one step further towards Mesos deprecation and auto-scaling of executor instances with Dynamic Resource Allocation. This opened doors to integrate security-related improvements such as enabling adding IAM roles for containers through Pod Identity for Spark Drivers..
All this was done under the hood, without impacting the user-experience and not requiring any service based migrations.
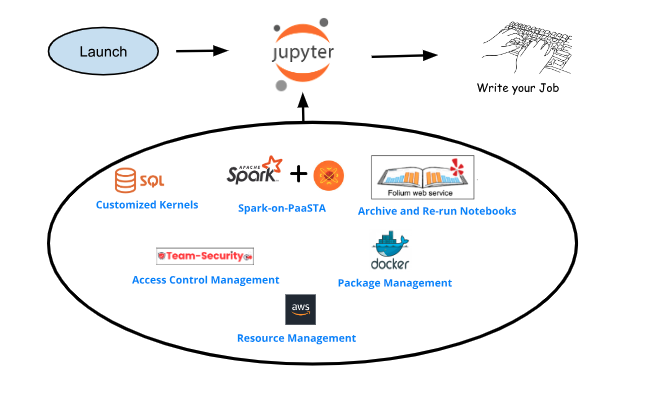
Launching Jupyter notebook and writing Spark job without having to deal with underneath components
Simplifying User Accessibility
One of the goals of the ML Compute team – a team focused on batch and machine learning infrastructure – is to continuously work in the direction of a ‘one-click-set-up-everything’ philosophy. This helps Jupyter and Spark users to shift their focus to notebook development instead of infrastructure management. This starts with providing a single web url entry-point for any internal user as shown in the diagram below. The entry-point lets the user launch a Jupyter Server after logging in with their LDAP credentials and using two-factor authentication (2FA).
The Jupyter Server is run from a docker image, which users can use directly or customize based on their requirements. These images have all the permissions, environment, packaging, and most recommended configurations required to install and run Spark, an otherwise onerous task.
Customizations to our Jupyter launcher set up user credentials based on assigned AWS roles to access various internal database resources (S3, Redshift), as well as allowing users to select between GPU vs CPU pools with custom resource configurations at the time of launch.
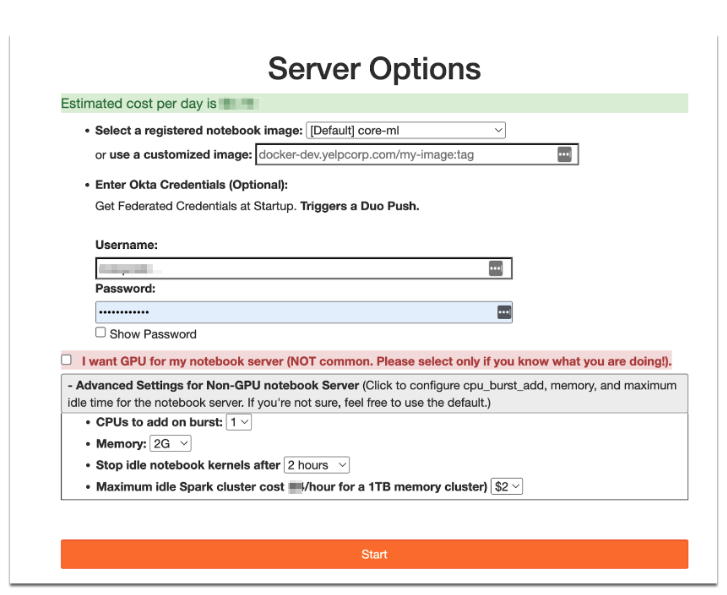
Single entry point to launch secured and customized notebook server
Customized Jupyter Kernels
The single entry-point leads to spawning a JupyterHub server. Most users have to select the right coding environment (python, sql, etc.) with relevant dependencies installed, often referred to as Kernels. Jupyter notebook comes with a default ipykernel built on top of IPython. We built our own internal custom standard Kernels for IPython and SQL, catered towards data-science and other Yelp Jupyter users. Our Sql Kernel provides an option for users to connect to multiple Datalake or Redshift Clusters and execute SQL queries interactively.
Creating Spark Session
Now that we have a notebook server ready to use, one can create a Spark Session with a single api call, create_spark_session. Besides returning an active Spark Session, this api internally takes care of the following:
- Deduces the final set of relevant Spark parameters based on different input sources
- Deduces the optimal default AWS resource and docker container configurations
- Takes care of setting up the environment variables (example: AWS creds)
- Emits resource usage monitoring link, spark history link, estimated cost
- Sends request to our other internal system Clusterman to spin-up a Spark Cluster in our shared Spark pool
Once the Spark session is created, a notebook user can focus on developing and iterating Spark batches, building data-science models onto the live Spark cluster. The diagram below shows a sample example of launching a Spark Cluster to use through a single api call.
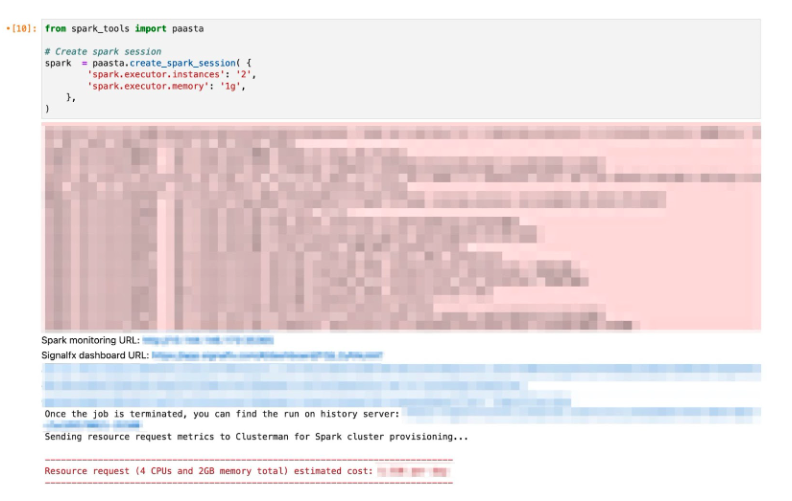
Creating a Spark Session
Managing Access Controls
Notebook users often want to connect to various AWS resources like Yelp’s Datalake, S3 paths, and Redshift. For a secured Yelp infrastructure, we want to make sure that each notebook developer can only access a designated set of clusters and resources based on their team-roles or privileges. Each user at Yelp has a designated set of roles giving them required access controls to AWS resources and databases, with session based creds accessible only after 2FA. To ensure that development experience is not impacted through manual, multi-step, and error-prone setup to manage the desired access controls, we provide easy UI based prompts and reminders for initializing and refreshing session based credentials.
During early years of our JupyterHub usage, we relied on syncing up each users’ static AWS credentials at the time of the launch of Jupyter Servers from a secured S3 location. Later on we moved towards using federated creds for batches run by human users. The lifespan of these federated creds is less than 12 hours and needs to be refreshed once the old credentials expire. Notebook extensions were added for users to refresh dev or prod credentials with a bunch of button click cycles as shown in the diagram below. The refresh mechanism generates federated credentials, also referred to as temporary credentials, using two-factor authentication linked to one of the designated roles associated with the triggering user. Later on this multi-step process was improved for users to generate credentials as part of a single sign-on process for their designated role. The future plan involves expanding this to auto-refresh credentials on expiry, so that their ongoing job execution or jobs requiring 12 hour runtimes don’t get impacted.
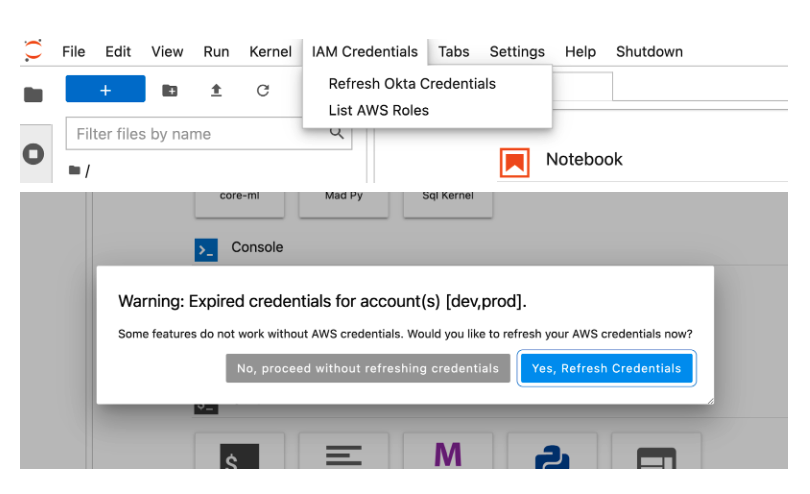
Pop-up option to refresh the credentials using 2FA authentication
Folium: Enabling Reproducible Notebooks
Many use-cases of the JupyterHub ecosystem involve re-running notebooks by multiple users with different inputs over time. As an example, data scientists receive multiple requests to recreate a past report with different sets of inputs. Relying solely on Jupyter notebooks involved a lot of manual steps. Some of these manual steps included starting a Jupyter server, finding their notebooks locally or in S3 buckets, updating the code, running them manually, and emailing the outputs to stakeholders. These steps took up a lot of development time and coordination, and were also error-prone and reduced developer velocity.
To solve this challenge, we built a notebook archiving and sharing service called Folium. Folium integrates with Jupyterhub to enable notebook reproducibility and improve developer velocity. A notebook developer can upload their notebook to Folium to share or re-run a notebook with a single click to get desired results (e.g., business data, machine learning model outputs, graphs). Later versions of Folium introduced tagging, grouping, and versioning of notebooks followed by integration of generation of temporary AWS role based credentials for the user re-running the notebook. For more details, refer to our previous engineering blog on Folium: Introducing Folium: Enabling Reproducible Notebooks at Yelp.
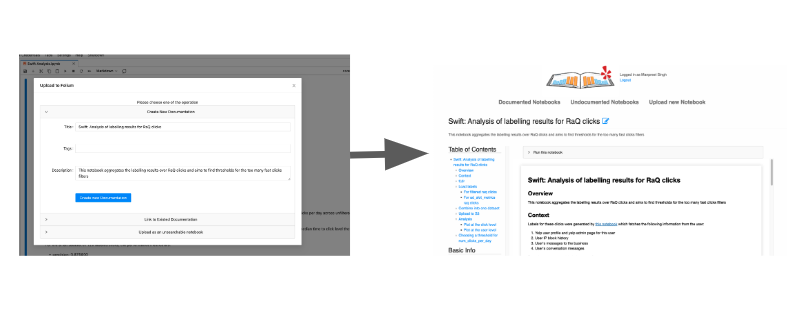
Typical workflow for uploading notebook to Folium
Parameterizing Notebook Reruns
We used the open-source Papermill library for parameterizing and executing Jupyter notebooks. The built-in support from Papermill only allows input/output to/from the local filesystem, and only supports running notebooks on the local machine. Our integration allowed users to directly rerun a templated notebook with different parameters in Folium, without the need to start up a Jupyter server, update notebook code with different inputs or monitor the running status manually. To do this, we adapted Papermill to use an I/O handler, letting the papermill read input notebooks from Folium and write output notebooks with computed results back to Folium, and provided a UI that launches new k8s pods for running individual notebooks.
Features and Extensions
Providing a smooth user-experience is one the key goals of our JupyterHub ecosystem’s evolution. As our ecosystem scaled in terms of its usage and teams, and with the integration of more systems like Folium, Papermill, and Federated Creds, it became necessary to add new features and extensions.
Here is a summary of some of the JupyterLab extensions and features we added as part of JupyterHub ecosystem:
- Monitoring
- Slack Notifications for long-running and expensive Jupyter notebooks.
- Open-source JupyterLab extension Spark Monitor shows the live status of the Spark job action execution within consecutive cells of Jupyter, which help us focus on the current job execution status without having to switch between SparkUI and Jupyter notebook.
- Cluster-level Monitoring on SignalFx/Prometheus: Active notebook run count, percentage of pool (CPU, GPU, on-demand) usage, individual notebook resource usage, data for all the customizations (like kernel, container, user) being used.
- Usability
- Menu buttons to upload and download notebooks from Folium.
- Menu buttons to refresh or generate AWS temporary creds for both development and production access
- Menu button to list available aws roles assigned and identify the privileges assigned to a user.
- Features
- Cost Savings
- Extension of the cull idle notebook server script to identify, report and kill long-running Spark Clusters to save cost. This is besides our regular cron job to kill idle notebook servers.
- Dynamic Resource Allocation integration to scale down the Spark Cluster when no spark action is in progress.
- Shutdown Server Menu Button option to enable users to manually shutdown or restart their server.
The diagram below summarizes the evolution of different components in the JupyterHub ecosystem in a timeline view at Yelp.
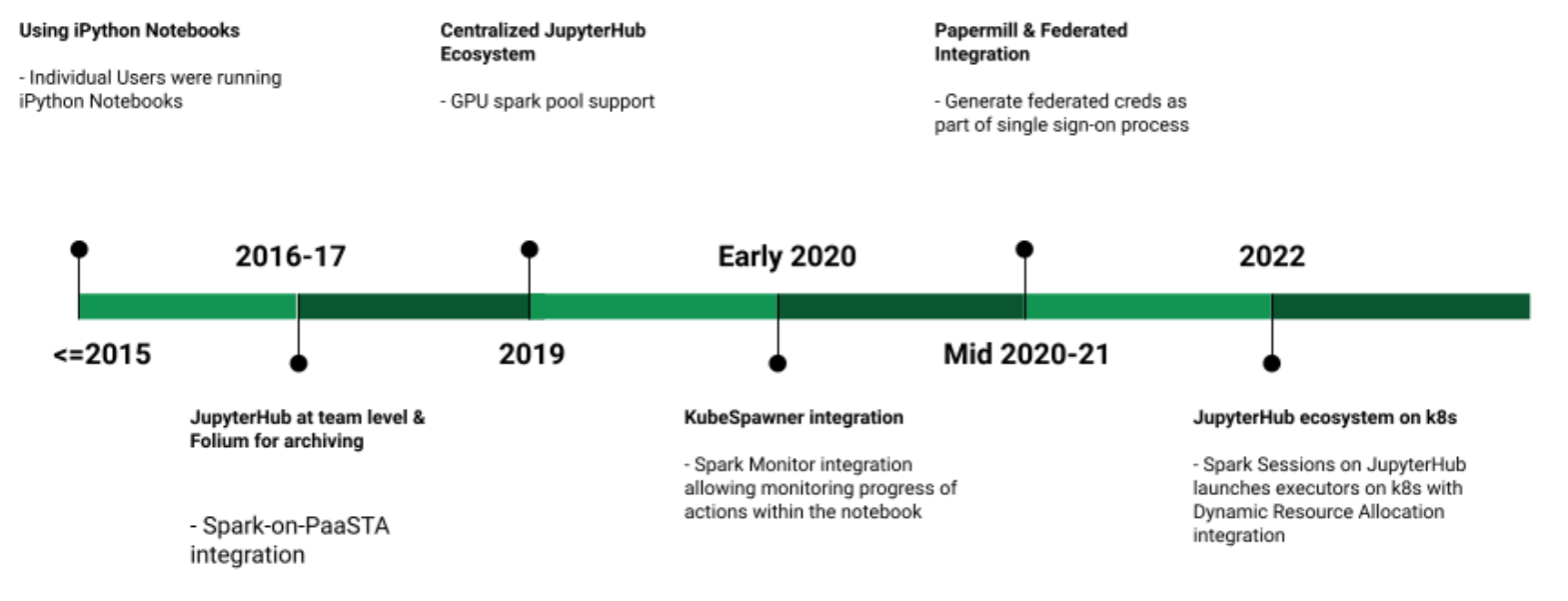
Timeline flow graph of JupyterHub ecosystem evolution
Conclusion
At Yelp, our team is committed to continuous evolution of the JupyterHub ecosystem. We have scaled usage of the JupyterHub ecosystem from an individual engineer, to team based deployments, to our current organization-wide deployments. In the process, we learned a lot about reducing complexity and increasing reliability, allowing our current setup to be maintained and evolved by an individual machine learning compute infrastructure team.
Our vision of increasing the development velocity and ease-of-use of our systems, reducing onboarding time, and ensuring security is at the forefront of our team’s continuous efforts and roadmap. We have accomplished this through a combination of adapting open source projects and current best practices to Yelp infrastructure, while focusing our internal development towards developer pain points specific to Yelp’s internal ecosystem.
Some of our future initiatives include enabling code navigation, expanding support for different types in parametrized notebooks, making Folium notebooks schedulable, increasing adaptation of GPU servers for model processing, and auto-refreshing federated credentials.
Acknowledgements
Special thanks to everyone on the Core ML, Compute Infrastructure, Security and other dependent teams for their tireless contributions in the bringing and continuous evolution of JupyterHub Ecosystems to keep it up-to-date. Thanks to Zeke Koziol, Blake Larkin, Jason Sleight, Ryan Irwin and Jonathan Budning for providing insightful inputs and sharing historical context and reviewing the blog.