Nrtsearch 1.0.0: Incremental Backups, Lucene 10, and More

-
Sarthak Nandi and Andrew Prudhomme
- May 8, 2025
It has been over 3 years since we published our Nrtsearch blog post and over 4 years since we started using Nrtsearch, our Lucene-based search engine, in production. We have since migrated over 90% of Elasticsearch traffic to Nrtsearch. We are excited to announce the release of Nrtsearch 1.0.0 with several new features and improvements from the initial release.
Glossary
- EBS (Elastic Block Store): Network-attached block storage volumes in AWS.
- HNSW (Hierarchical Navigable Small World): A graph-based approximate nearest neighbor search technique.
- Lucene: An open-source search library used by Nrtsearch.
- S3: Cloud object storage offered in AWS.
- Scatter-gather: A pattern where a request is sent to multiple nodes, and their responses are combined to create the result.
- Segment: Sub-index in a Lucene index which can be searched independently.
- SIMD (Single Instruction, Multiple Data): CPU instructions that perform the same operation on multiple data points, can make some operations like vector search faster and more efficient.
Major Changes
Incremental Backup on Commit
Nrtsearch now does an incremental backup to S3 on every commit, and this backup is used to start replicas. The motivation behind this change and more details are discussed below.
Initial Architecture
A quick refresher of the Nrtsearch architecture from the first Nrtsearch blog - the primary flushes Lucene index segments to locally-mounted network storage (Amazon EBS in our case) when commit is called. This guarantees that all data up to the last commit would be available on the EBS volume. If a primary node restarts and moves to a different instance, we don’t need to download the index to the new disk; instead, we only need to attach the EBS volume, allowing the primary node to start up in under a minute and reducing the indexing downtime. We call the backup endpoint occasionally on the primary to backup the index to S3. When replicas start, they download the most recent backup of the index from S3 and then sync the updates from the primary. When the primary indexes documents, it publishes updates to all replicas, which can then pull the latest segments from the primary to stay up to date.
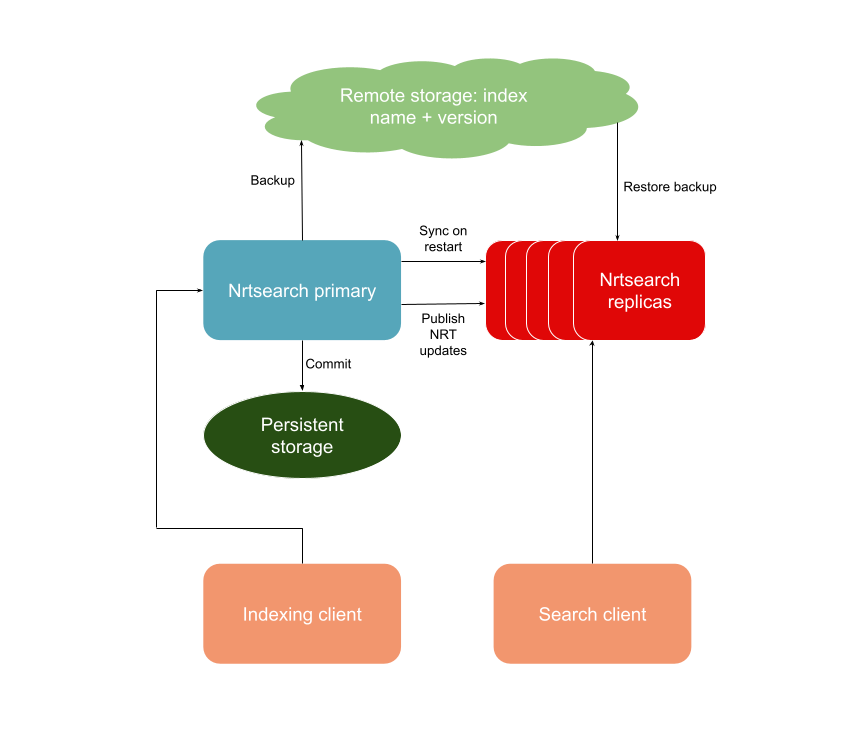
Initial Nrtsearch architecture
Drawbacks of Architecture
This architecture mostly worked well for us, but there were some drawbacks:
- EBS volume was the source of truth. If the EBS was lost, corrupted, or took too long to resize, we would have to reindex all data.
- The EBS movement was not as smooth as expected. At times, the EBS volume would not be correctly dismounted from the old node, and then the new node would take some time to mount it.
- Ingestion-heavy clusters would need to back up the entire index frequently so that replicas did not have to spend too much time catching up with the primary after downloading the index.
Switching to Ephemeral Local Disks and Incremental Backup on Commit
To avoid these drawbacks, we wanted to use an ephemeral local disk instead of an EBS volume. There were two blockers for using local disk:
- Ensuring that restarting the primary wouldn’t result in losing changes made between the last backup and the most recent commit
- Making sure the primary could download the index quickly enough to remain competitive with the speed of mounting an EBS volume.
To ensure that primary retained all changes until the last commit, we needed to backup the index after every commit instead of doing it periodically. To do this in a feasible manner, we switched to incrementally backing up individual files instead of creating an archive of the index. Lucene segments are immutable, so when we perform a backup, we only need to upload the new files since the last backup. On every commit, Nrtsearch checks the files in S3, determines the missing files, and uploads them. This makes a commit slightly slower, as we are now uploading files to S3 while we were only flushing them to EBS before. The additional time is generally a few ms to 20 seconds depending on the size of the data, which is trivial enough to not cause any issues.
To address the second blocker, we started downloading multiple files from S3 in parallel to make full use of the available network bandwidth. Combined with a local SSD, this yielded a 5x increase in the download speed. With both blockers resolved, we were able to stop using EBS volumes in favor of local disks.
We still have the ability to take full consistent backups (snapshots) to use in case the index gets corrupted. Instead of having the primary perform this operation, we now directly copy the latest committed data between locations in S3. Since these full backups are not involved in replica bootstrapping, they can be less frequent than before.
The updated Nrtsearch architecture can be seen below. Large Nrtsearch indices are split into multiple clusters, and Nrtsearch coordinator directs all requests to the correct Nrtsearch primaries and replicas. It also does scatter-gather for search requests if needed. On the ingestion side, Nrtsearch coordinator receives index, commit, and delete requests from indexing clients, and forwards the requests to the correct Nrtsearch primaries. Check out Coordinator - The Gateway For Nrtsearch blog for more information about sharding in Nrtsearch.
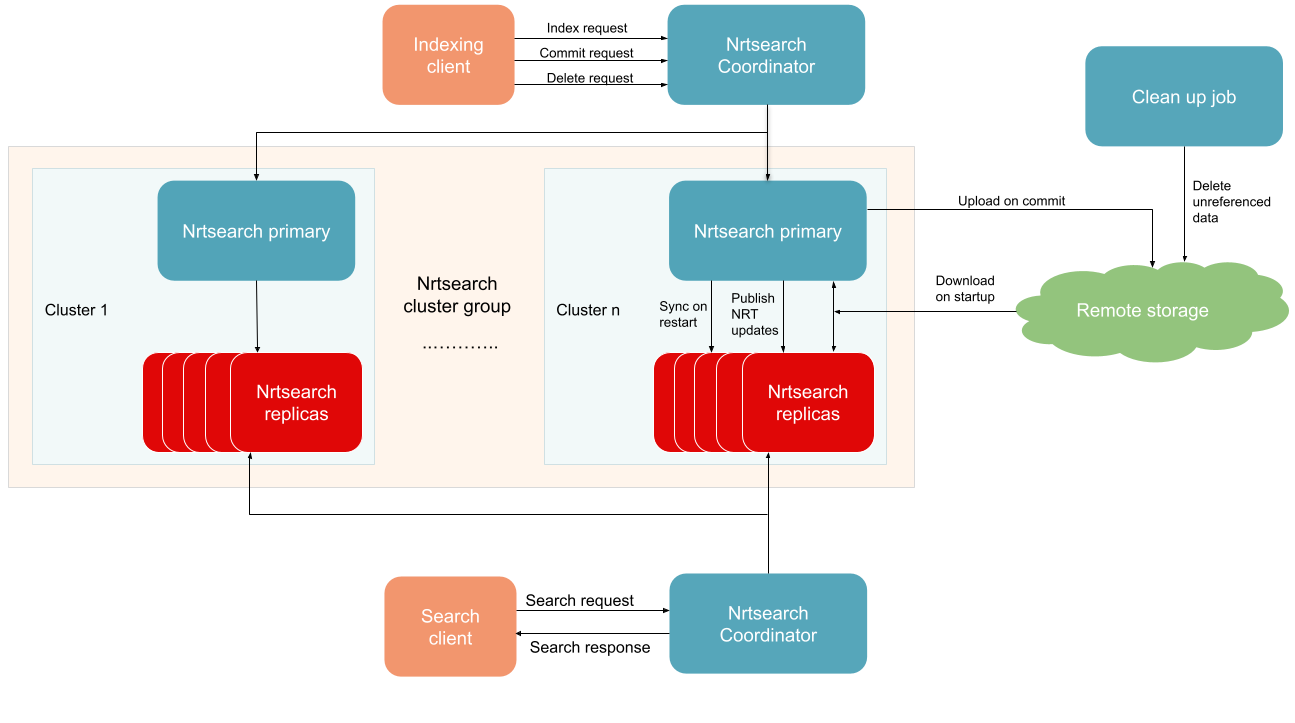
Updated Nrtsearch architecture
Lucene 10
We used the latest version of the Lucene library available during the initial development of Nrtsearch, version 8.4.0. We have now updated to use the latest release of Lucene 10 (10.1.0). This update includes a host of improvements, optimizations, bug fixes, and new features. The most notable new feature is vector search using the HNSW algorithm. Additionally, combined with our update to Java 21, Lucene 10 can leverage newer java features such as SIMD vector instructions and the foreign memory API.
Overhaul of State Management
Legacy State Management
The original management of cluster and index state was simplistic and difficult to work with.
The cluster state only contained the names of the indices that had been created. The servers did not know which of these indices should be started, so it was up to the deployment manager (Kubernetes operator) to start the necessary indices during server bootstrapping. This resulted in more complexity for the operator.
Index state is composed of three main sections:
- Settings: properties that can only be configured before an index is started
- Live settings: properties that can be updated dynamically
- Fields: index schema specifying the field types and their properties
The process for updating index state on a cluster was time consuming and error prone:
- Issue requests to the primary to change index state
- Issue an index commit request on the primary, which makes the data and state durable on local storage (EBS)
- Issue a backup request on the primary, which makes the latest committed state and index data durable in remote storage (S3)
- Restart all cluster replicas to load the latest remote state and data
Pain Points
There were several issues with the state update process:
- The commit of index state and data were coupled together. This was unnecessary, since the only allowed state changes were backwards compatible with previous data. Specifically, new fields can be added to the index, but existing fields cannot be removed or modified.
- State changes were not durable until after a commit request. This meant that an update could be lost if the primary server restarted between the state modification and the commit.
- The local disk (EBS) on the primary was the source of truth for cluster state. However, there is only a single primary, which is unavailable during restarts and re-deployments. Since the state was sometimes inaccessible, building tools around it was difficult.
- Needing to backup an index and restart all replicas significantly extended the time needed to fully propagate state changes across a cluster.
Internally, when a state change was applied, it was not done in an isolated way. As a result, state values may change when sampled multiple times during the processing of a single request. This could lead to inconsistencies and more edge cases to handle.
New State System
The state management system was redesigned to address the above issues.
The cluster state was updated to include additional information about the indices. The ‘started’ state of each index is tracked. This allows the necessary indices to be automatically started during server bootstrapping, removing the need for external coordination. The state also contains a unique identifier for each index to isolate data/state in the case that an index is recreated.
Committing state changes are decoupled from committing data. Because of this, state changes are now committed within the life of the update request. This prevents changes made by successful requests from being lost. Clients will also no longer see state values applied to the primary that have not yet been committed.
The location of state data can be set to either local (EBS) or remote (S3). Setting the location to remote means that the local data is no longer the source of truth for state, and the primary disk no longer needs to be durable to maintain cluster state.
The ability to hot reload state was added to replicas, allowing the application of changes without needing a server restart. The state update process is now simplified to: Issue requests to the primary to change state Hot reload state on all replicas This greatly reduces the time needed to apply a change to the whole cluster.
Internally, the index state was changed to build into an immutable representation. When a change is processed, it is merged into the existing state to produce a new immutable representation. After the change is committed to the state backend (EBS or S3), the new state atomically replaces the reference to the old state. This prevents changes from being observed before they are committed. Client requests retrieve the current state once, and reference it for the remainder of the request. Since the state object is immutable, changes will not be visible during the processing of a single request.
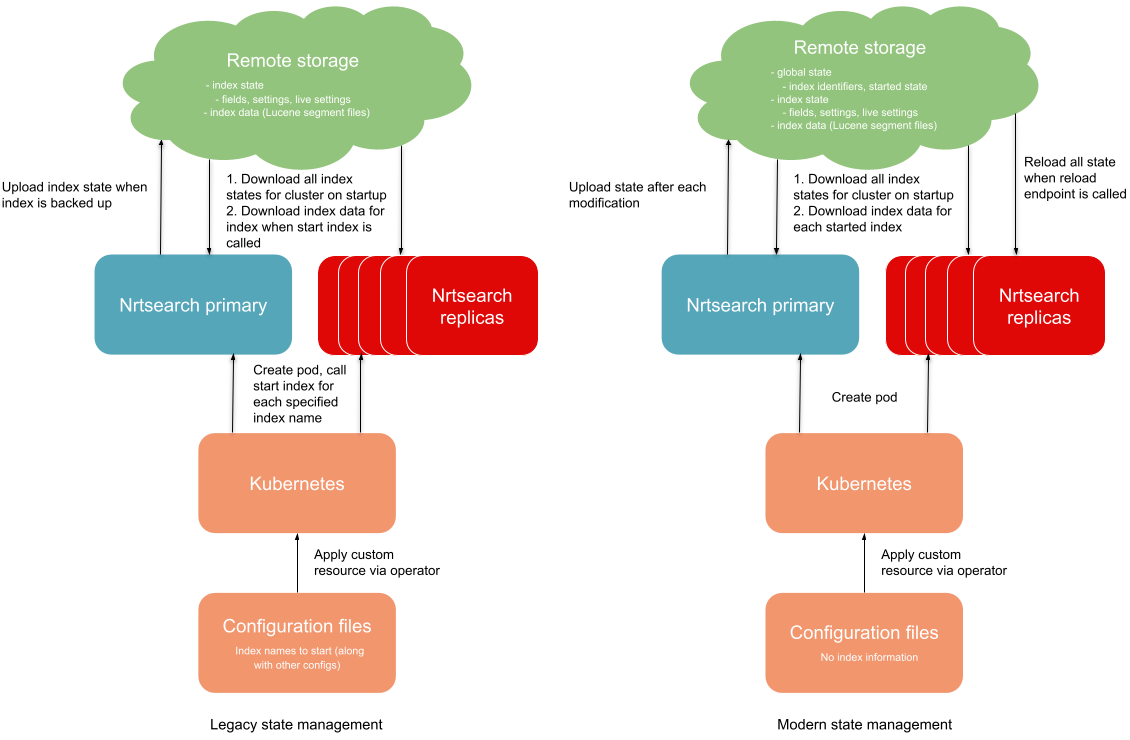
Legacy vs modern state management
New Features
Vector Search
Starting in major version 9, Lucene added support for vector data and nearest neighbor search with the HNSW algorithm. Nrtsearch leverages this api to provide kNN vector search for float and byte vector data with up to 4096 elements. A number of different similarity types are available: cosine (with or without auto normalization), dot product, euclidean, and maximum inner product.
Nrtsearch also exposes several additional advanced features:
- Float vectors may be configured to use scalar quantized values for search, allowing a tradeoff between accuracy and memory usage
- Vector search is available for fields in nested documents
- Intra merge parallelism may be configured to speed up merging vector graph data
- Optimized SIMD instruction support, provided by Java, can be enabled to accelerate vector computations
See Vector Search and Embeddings in Nrtsearch for more details.
Aggregations
One of the requirements for migrating our existing search applications from Elasticsearch was providing limited support for aggregations. We initially tried to replicate any needed functionality by using and extending Lucene facets. This worked for some of the more simple use cases, but was not suitable for more complex and/or nested aggregations.
There were two main issues with using facetting. Complex aggregation logic could be added using the Nrtsearch plugin system. However, this required creating custom code for every use case, which was not a scalable or maintainable process. Additionally, facet processing was not integrated with parallel search. Collecting and ranking documents is done in parallel by dividing the index into slices. However, facet result processing happened after collection and is single threaded. For large indices with complex aggregations, this could noticeably add to request latency.
As an alternative to facets, we added an aggregation system that integrates with parallel search. Aggregations are tracked independently for each index slice. When a slice document is recalled and collected for ranking, it is also processed by the aggregations to update internal state (such as term document counts).
When parallel search finishes for each index slice, it performs a reduce operation to merge all the slice top hits together to form the global document ranking. This reduction also happens for the aggregations. The aggregation state from each slice is merged together to produce the global state. The global state is used to produce the aggregation results returned to the client in the search response. In the case where aggregations are nested, this merge happens recursively.
Currently, this system supports the following aggregations:
- term (text and numeric) - creates bucket results with counts of documents that contain the terms
- filter - filter documents to nested aggregations based on a given criteria
- top hits - top k ranked documents based relevance score or sorting
- min - minimum observed value
- max - maximum observed value
Support for More Plugins
Nrtsearch is highly extensible and supports a variety of plugins, enabling customization and enhanced functionality. Some of the key plugins include:
- Script - custom scoring logic written in Java (simple custom logic can also be specified using Lucene javascript expressions without a plugin)
- Rescorer - allows custom rescore operations to refine search results by recalculating scores for a subset of documents.
- Highlight - provides custom highlighting to emphasize relevant sections in search results.
- Hits Logger - facilitates custom logging of search result hits, useful for collecting data to train machine learning models.
- Fetch Task - enables custom processing of search hits to retrieve and enrich data as needed.
- Aggregation - custom aggregation implementation These plugins empower users to tailor Nrtsearch to their specific search and retrieval requirements.
Expanded search queries
We have exposed more Lucene query types in our search request. We are still missing some queries though, and we plan to add more query types on an as-needed basis. You can find the currently available query types in our documentation.
Future Work
We are planning to do NRT replication via S3 instead of gRPC to allow replicas to scale without the primary being a bottleneck. We are also planning to replace virtual sharding with parallel search in a single segment, a feature added in Lucene 10.
Become a Data Backend Engineer at Yelp
Do you love building elegant and scalable systems? Interested in working on projects like Nrtsearch? Apply to become a Data Backend Engineer at Yelp.
View Job