Streaming Cassandra into Kafka in (Near) Real-Time: Part 1

-
Andrew Prudhomme, Software Engineer and Harshal Dalvi, Engineering Manager
- Dec 5, 2019
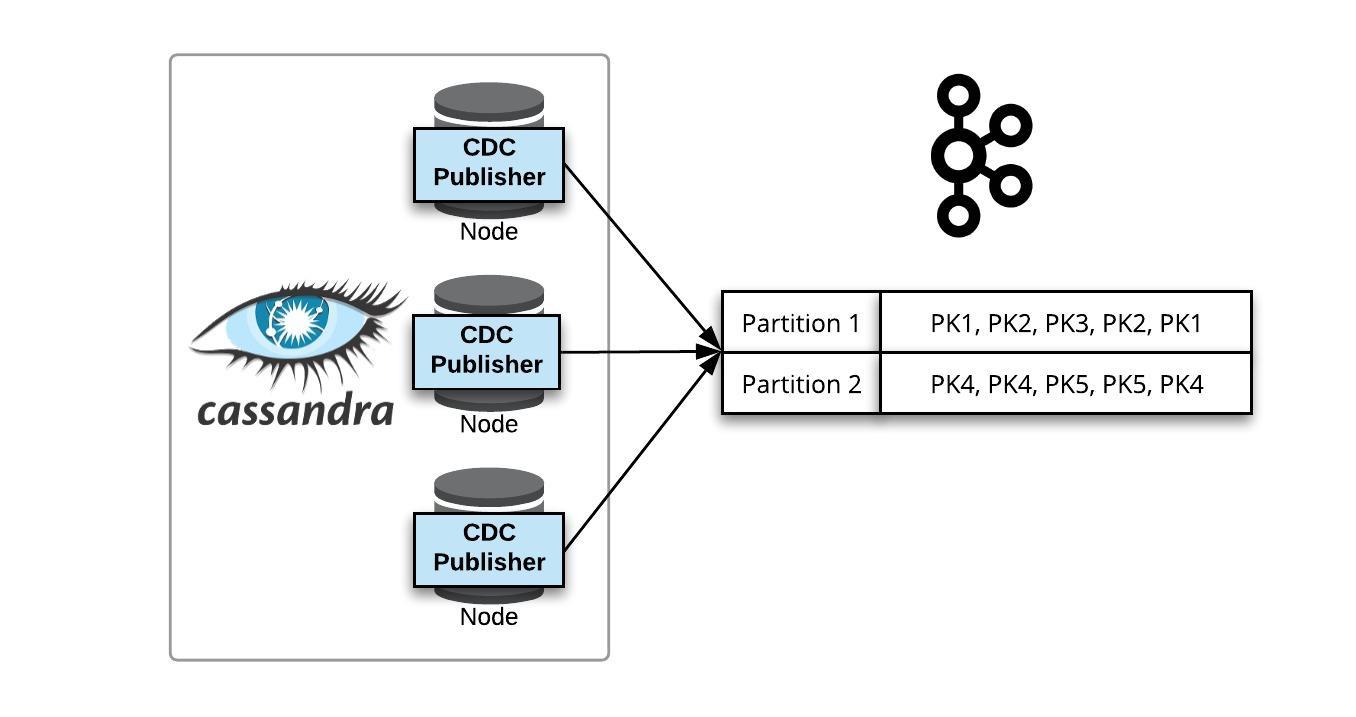
At Yelp, we use Cassandra to power a variety of use cases. As of the date of publication, there are 25 Cassandra clusters running in production, each with varying sizes of deployment. The data stored in these clusters is often required as-is or in a transformed state by other use cases, such as analytics, indexing, etc. (for which Cassandra is not the most appropriate data store). As seen in previous posts from our Data Pipeline series, Yelp has developed a robust connector ecosystem around its data stores to stream data both into and out of the Data Pipeline. This two-part...