Boosting ML Pipeline Efficiency: Direct Cassandra Ingestion from Spark

-
Muhammad Junaid Muzammil, Software Engineer; Arnold Ziesche-Blank, Machine Learning Engineer
- Sep 19, 2024
Machine Learning Feature Stores
ML Feature Store at Yelp
Many of Yelp’s core capabilities such as business search, ads, and reviews are powered by Machine Learning (ML). In order to ensure these capabilities are well supported, we have built a dedicated ML platform. One of the pillars of this infrastructure is the Feature Store, which is a centralized data store for ML Features that are the input of ML models.
Having a centralized dedicated datastore for ML Features serves a number of purposes:
- Data Quality and Data Governance
- Feature discovery
- Improved operational efficiency
- Availability of Features in every required environment
ML Models at Yelp are usually trained on historical data and used for inference in real-time systems. Thus we need to be able to serve the Features (which are the inputs for the model both during inference and during training) in real time during inference, and as a historical log of all previous values during training.
The Feature Store is an abstraction over real-time and historical datastores to provide a unified Feature API to the models.
Specifically, our historical Feature Store is implemented in our Data Lake and the real-time Feature Stores are implemented in Cassandra or NrtSearch.
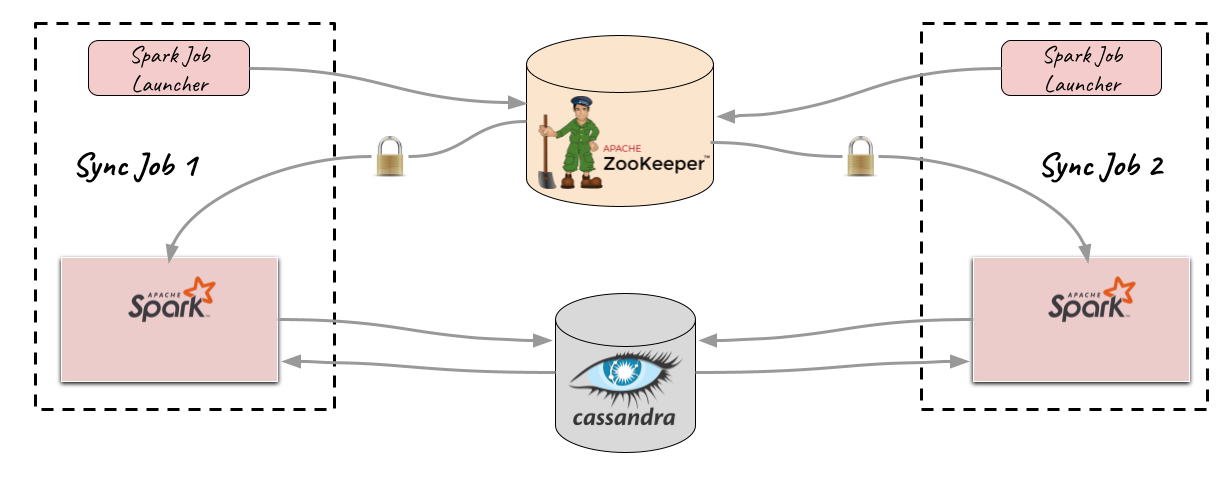
Here, we will discuss how we improved the automated data sync from the Historical Feature in DataLake to the Online Feature Store in Cassandra. At a high level, the data movement is carried out by Sync jobs in between different data stores as depicted below.

Status Quo
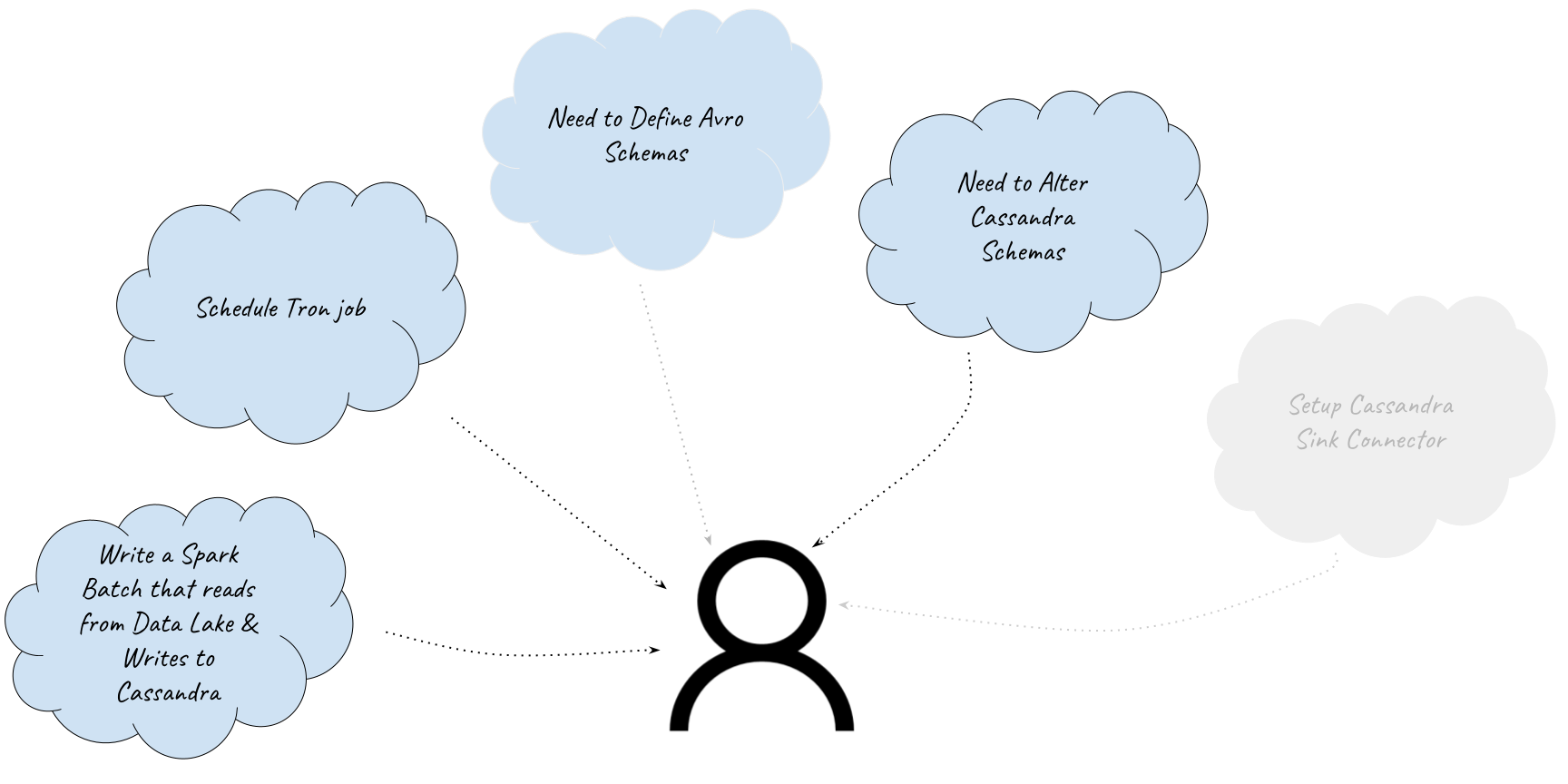
Our Spark ETL framework, an inhouse wrapper around PySpark, did not support direct interactions with any of the online datastores. So any writes had to be routed through Yelp’s Data Pipeline.

Thus, publishing ML Features to Cassandra required a longer route involving multiple steps:
- Create a Sync job that reads Features from Data Lake and republishes them to Data Pipeline.
- Create and register an Avro Schema, which is required for publishing data to the Data Pipeline.
- Schedule the Spark job in Tron, our centralized scheduling system.
- Make Schema changes to add the new Feature columns in Cassandra. We have strict controls in place around Cassandra Schema changes at Yelp which require following a separate process.
- Create a Cassandra Sink connection to push the data into Cassandra from the Data Pipeline.
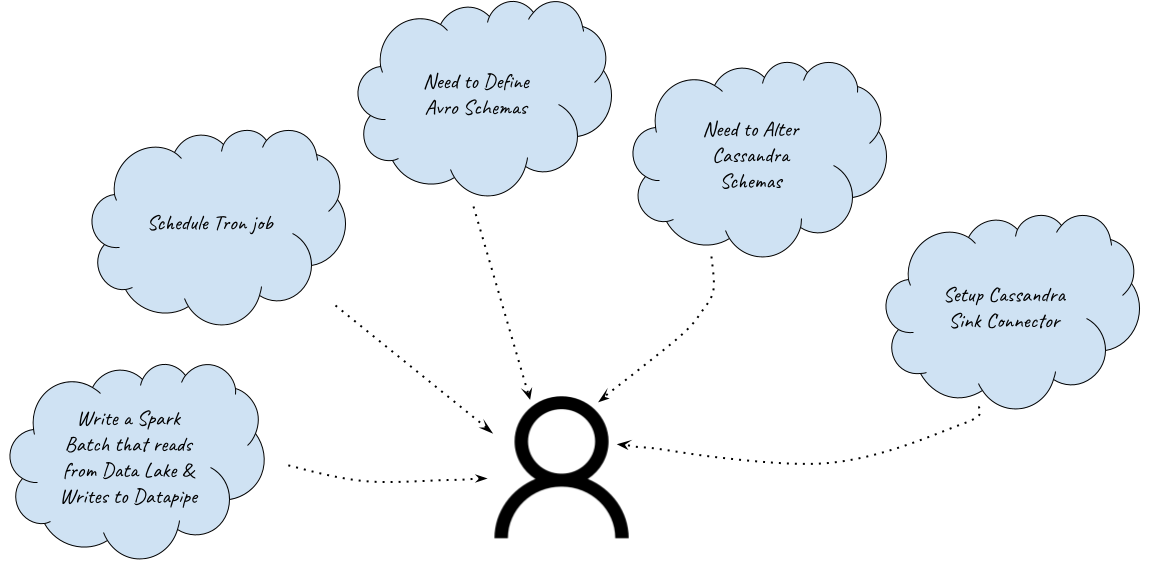
This process had a few disadvantages.
- The data first needs to be duplicated into the Data Pipeline, which has some cost implications.
- The engineer would have to ensure all five steps are executed successfully when publishing the Features.
- Our Cassandra Sink Connector relies on eventual publishing of data from Data Pipeline. This means the engineers often have less visibility when the Feature is completely published and available for reads from Cassandra.
Direct Feature Publication
In order to deal with the above challenges, Cassandra datastore was made a first-class citizen in the Spark ETL framework. The foundation of it has been laid on top of the open source Spark Cassandra Connector, allowing us to ingest Spark dataframes to Cassandra tables as well as extract data from Cassandra to Spark dataframes.
One of the key considerations when supporting Direct Feature Publication was to avoid any impact on the live traffic that our Cassandra clusters serve. One option we considered was spinning up a dedicated datacenter for Spark workloads. We ruled that out primarily for the following two reasons.
- Running Cassandra clusters would contribute additional costs.
- Our Spark workloads rely more on writes to Cassandra than on reads. As data needs to be replicated across datacenters, having a dedicated datacenter doesn’t add much value.
Throughout the rest of the article, we are going to focus on the Cassandra publisher aspects only. A number of design decisions that were made to ensure the reliability of our Cassandra production fleet are discussed below.

Batch Mode Disabled for Cassandra Writes
From our experiments, we found that a Spark dataframe could be partitioned by a column that isn’t a partition key in Cassandra. This means if we enabled batching without re-partitioning, it could result in a request to Cassandra from a Spark job involving multiple different partitions. A re-partition of Spark dataframe appeared to be excessive here, so we kept batching disabled for Cassandra writes.
Limiting Concurrent Writers
Another control we implemented was to limit the number of concurrent writers to Cassandra to avoid putting pressure on Cassandra’s Native Transport Request (NTR) queue, and let Cassandra’s backpressure handle it.
Static Rate-Limiting
One of the major challenges was preventing Spark jobs from overloading the Cassandra cluster. The online nature of the datastore means the impact would be sudden and obvious. This was a challenge as there’s no adaptive rate control mechanism in the Spark Cassandra Connector (SPARKC-594). Spark Cassandra Connector provides static rate-limiting configurations, but those are defined at per executor core level (Spark task). These configuration options look like:
spark.cassandra.output.throughputMBPerSec
spark.cassandra.output.concurrent.writes
A couple of situations where a Cassandra cluster can be stressed out include:
- A Spark job launched with a large number of cores/executors, which means there are a large number of parallel works ingesting or reading from the Cassandra cluster.
- There are many Spark jobs launched in parallel interacting with a particular Cassandra cluster.
To avoid these situations, we configured a few tuning parameters for Spark jobs. A major one was configuring the capability to rate-limit a Spark job irrespective of the number of executors or cores launched. However, with Spark’s Dynamic Resource Allocation (DRA) enabled, it’s tricky to get the exact number of resources. Therefore, we computed the maximum possible executor cores as follows.
max.executor.cores = min(max.executors * max.cores, max.spark.partitions)
Limiting Number of Concurrent Spark Jobs
To effectively limit the number of concurrent Spark jobs accessing a Cassandra cluster, we needed some concurrency control mechanism. We implemented it based on distributed locks with Zookeeper. In addition, we kept the lock contention time configurable so that Spark jobs can wait in case the semaphore lock is fully acquired. The positioning of the lock acquisition was interesting, and we deliberately acquired it just before initiating the Spark job to prevent a scenario where resources are allocated but remain idle in a waiting state. The potential request handling capacity of different Cassandra clusters is proportional to the amount of computational resources allocated to it, so we kept the semaphore maximum count configurable.
Results
The direct Feature publication to Cassandra yields us some significant benefits, which are discussed below.
Infrastructure Cost Savings
We used to have 4 different components that contributed to the cost of moving a feature. These included:
- The cost of computational resources allocated for executing a Spark job.
- The cost of storing data inside Yelp’s Data Pipeline.
- The cost associated with the Cassandra Sink Connection for ingesting data from the Data Pipeline into Cassandra.
- The cost of I/O Operations on the Cassandra side for publishing data.

Using direct Feature publication, we observe the following improvements:
- Spark jobs now take longer to complete, but they use much fewer executors.
- The Data Pipeline is eliminated completely.
- The Cassandra Sink Connection is eliminated completely.
- The cost of I/O Operations in Cassandra remains almost unchanged.
Overall, we observed around 30% in ML Infrastructure Cost Savings.
Developer Velocity
There were also benefits seen in terms of improving Engineering Efficiency. Compared to the previous mechanism, engineers can worry less about setting up the Sink Connections for Cassandra. The requirement for the definition of Avro Schemas also got downgraded from a hard requirement to soft requirement, mainly for assisting the engineer in early data validation and verification. These Avro Schema were primarily needed to define schema for Yelp’s Data Pipeline (more details can be found in our Schema Store blog). In total, there’s a 25% improvement in engineering effectiveness with respect to Feature publishing.
Developer Visibility
As mentioned earlier, our Cassandra Sink Connector relies on eventual publication of data into the Data Pipeline. This means it is slightly more complicated for developers to track when the Feature is completely published to Cassandra with the status quo. Relying on direct ingestion to Cassandra means data is readily available for reads as soon as the Spark job succeeds.
Reducing the complexity of Feature publishing also improved the maintainability of the Feature Store systems.
Conclusion
The transition to direct publication to Cassandra has yielded considerable advantages, enhancing engineering effectiveness and reducing overall infrastructure costs. However, presence of adaptive rate-limiting on the Spark Cassandra Connector could have helped us in improving the developer experience further. A future potential improvement includes a switch to reading/writing data with Spark Bulk Analytics. This will allow us to by-pass Cassandra’s Native Transport Request limits, and theoretically the read/write throughput can reach the max limits supported by the hardware (i.e. disks).
Acknowledgements
We would like to thank Adel Atallah, Manpreet Singh and Talal Riaz for their contribution towards successful completion of this work.
Become an Engineer at Yelp
We work on a lot of cool projects at Yelp. If you're interested, apply!
View Job