Powering Messaging Enabledness with Yelp's Data Infrastructure

-
Billy Barbaro, Tech Lead; John Stimac, Tech Lead
- Apr 5, 2021
In addition to helping people find great places to eat, Yelp connects people with great local professionals to help them accomplish tasks like making their next big move, fixing that leaky faucet, or repairing a broken phone screen. Instead of spending time calling several businesses, users can utilize Yelp’s Request a Quote feature to reach out to several businesses at once, receive cost estimates from those businesses, and ultimately hire the right local professional for the job. This post focuses on how Yelp’s Data Pipeline is used to efficiently compute which businesses are eligible for the feature, and also introduces Yelp’s Data Lake, which we use to track historical values of the feature for offline metrics and analytics.
Background
While most businesses can be reached via the phone number listed on their Yelp business page, only a subset of businesses are eligible for Yelp’s messaging feature (at least for now!). We refer to the ability for a business to receive messages from users as “messaging enabledness” (or sometimes, just enabledness). It is determined by checking several different conditions about the business. For instance, the business owner must opt-in to the feature and they must have a valid email address so they can be notified about new messages, among other things.
Computing messaging enabledness is tricky since checking all the criteria requires joining and fetching values from several different SQL tables. For some features, like deciding whether or not to display the “Request a Quote” button on a business’s page, it’s essential to correctly identify a business’s enabledness, even if it takes extra time to perform all those joins. For other applications of the data, such as analysis or indexing, we can tolerate the risk of a stale value in order to speed things up, so a cached mapping of an identifier for the business (business_id) to its messaging enabledness is stored in its own SQL table. This is kept up to date by a batch which runs periodically to recompute the value for all businesses.
Storing Historical Changes
In addition to storing the current state of enabledness, Yelp is also interested in persisting a historical record of messaging enabledness for businesses. This allows the company to measure the health of the Request a Quote feature in addition to being an invaluable source of information when investigating any pesky bugs that might pop up.
There are millions of businesses listed on Yelp, so storing this history in a SQL table is not efficient in terms of storage cost or query time. Another option was to store a nightly snapshot of the table, but that would have resulted in duplicated information day to day, would have been more difficult to query, and wouldn’t have captured multiple changes to the same business in a single day. What we really want to store is a change log of the table.
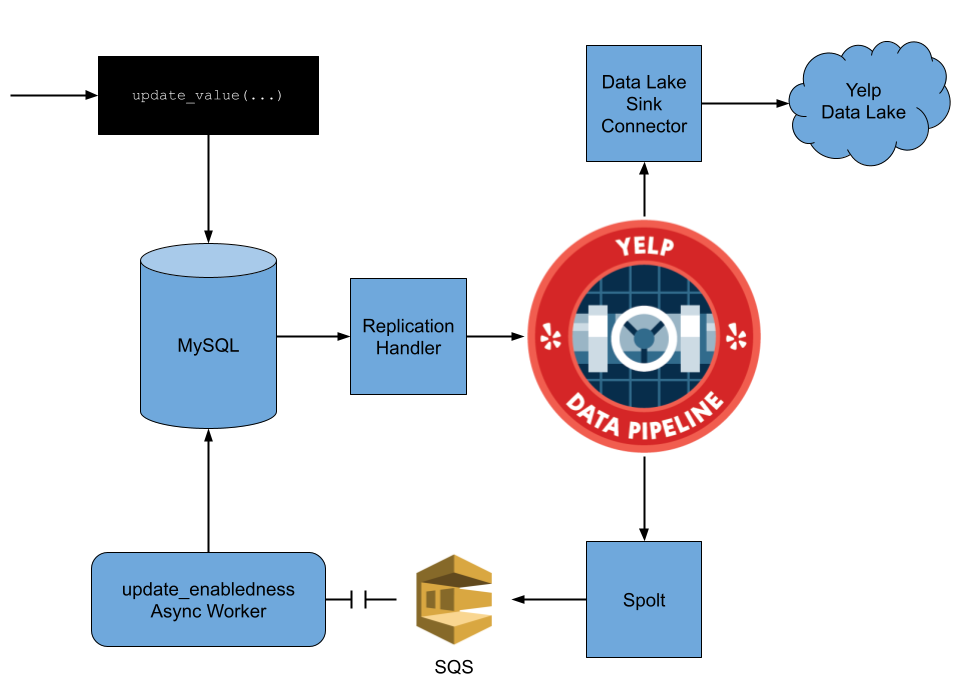
Remember that this data is stored in a SQL table. If you’ve been following along with the Data Pipeline posts on the Yelp engineering blog, you’ll know that Yelp has developed a tool called the Replication Handler which publishes a message to our Kafka infrastructure for every update to a SQL database. By connecting this tool to the table caching businesses’ messaging enabledness, a full history of changes can be written to a Kafka stream. Now if only we had a way to store this stream…
Yelp’s Data Lake
Yelp’s Data Lake is our solution for storing schematized data at scale. Our Data Lake is built on top of the Apache Parquet format, Amazon S3, and Amazon Glue. This S3 based architecture allows us to cheaply store data, making it possible for us to keep records over a long period of time. Our Data Lake implementation also integrates with our in-house schema management system, Schematizer.
Data from Kafka can easily flow into our Data Lake through our Data Lake Sink Connector. The connector provides a fully-managed way for moving data to the Data Lake, without engineers having to worry about any underlying infrastructure. All engineers need to do is specify which data they want in the Data Lake, either though our datapipe CLI tool or through our Pipeline Studio web UI.
$ datapipe datalake add-connection --namespace main --source message_enabledness
Data connection created successfully
Connection #9876
Namespace: main
Source: message_enabledness
Destination: datalake
Once in the Data Lake, data can power a wide variety of analytic systems. Data can be read with Amazon Athena or from Spark jobs. Using Redshift Spectrum, we also allow analytics from Redshift, where Data Lake data can be joined with data we put in Redshift using our Redshift Sink Connector. Redshift Spectrum can also be used to power Tableau dashboards based on Data Lake data.
Getting More Granular
We previously mentioned that the messaging enabledness table was updated periodically. Even though changes to the table are being persisted to the Data Lake, with this approach we’re not able to identify the time the change happened and have no way to tell why the value changed (i.e. which of the criteria triggered this change).
In order to catch these changes in real time, each time an update happens that might affect a business’s enabledness, an asynchronous task can be submitted to recompute the value and store it in the table along with the reason for the change. The code looks something like this:
def update_value(business_id, new_value):
update_value_for_business(business_id, new_value)
update_enabledness_async(business_id, reason)
def update_enabledness_async(business_id, reason):
current_enabledness = get_enabledness_from_cache(business_id)
updated_enabledness = compute_enabledness(business_id)
if not current_enabledness == updated_enabledness:
set_enabledness(business_id, updated_enabledness, reason)
While this works, you might be able to spot a shortcoming: anytime an engineer adds a new way to update a value which might change a business’s enabledness, they also need to remember to call the update_enabledness_async method. Even though this approach might capture all the changes when it is first written, as the code evolves over time a single mistake can cause the data stored in the table to be inaccurate.
def update_value_v2(business_id, new_value)
update_value_for_business(business_id, new_value)
# Something is missing here...
Reacting to the Changes
Looking more closely at the system above, there is something peculiar about the update call. Recomputing enabledness isn’t really an operation that should happen after one of the criteria was updated. Instead it happens as a result of the value being changed. Rather than depending on engineers and code reviewers to remember that the update_enabledness_async function must be triggered manually, what if we could build a system that triggered this update as a result of the change?
Each of the criteria for enabledness is stored in a SQL table, and as we discussed earlier in the post, the Replication Handler can be used to publish changes to those tables to Yelp’s Data Pipeline! Consumers of those topics (specifically, Paastorm spolts) can be set up to call the update_enabledness_async task on any relevant change!
Conclusion
This post introduces the Yelp Data Lake and demonstrates how the Data Lake Sink Connector makes it easy to track the historical value of a business’s messaging enabledness. It also shows how the Streaming Infrastructure you’ve read about in previous blog posts (or at least the ones you’re about to read right after you finish this one!) is used to solve real engineering problems at Yelp, allowing systems to react to data changes without the need to write custom components or complex logic.
Acknowledgements
- Thanks to Mohammad Mohtasham, Vipul Singh, Francesco Di Chiara, and Stuart Elston who assisted at various stages of design and implementation of this project.
- Thanks to Blake Larkin, William O’Connor, and Ryan Irwin for technical review and editing.
Become an Engineer at Yelp
Are you interested in using streaming infrastructure to help solve tough engineering problems?
View Job