Enhancing Neural Network Training at Yelp: Achieving 1,400x Speedup with WideAndDeep

-
Yunhui Zhang, Software Engineer
- Jan 22, 2025
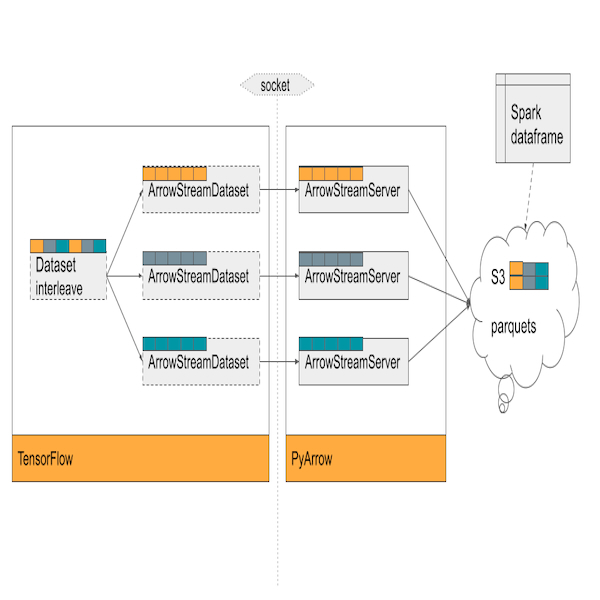
At Yelp, we encountered challenges that prompted us to enhance the training time of our ad-revenue generating models, which use a Wide and Deep Neural Network architecture for predicting ad click-through rates (pCTR). These models handle large tabular datasets with small parameter spaces, requiring innovative data solutions. This blog post delves into our journey of optimizing training time using TensorFlow and Horovod, along with the development of ArrowStreamServer, our in-house library for low-latency data streaming and serving. Together, these components have allowed us to achieve a 1400x speedup in training for business critical models compared to using a single GPU...