Introducing Yelp's Local Graph

-
Tomer Elmalem, Software Engineer
- May 3, 2017
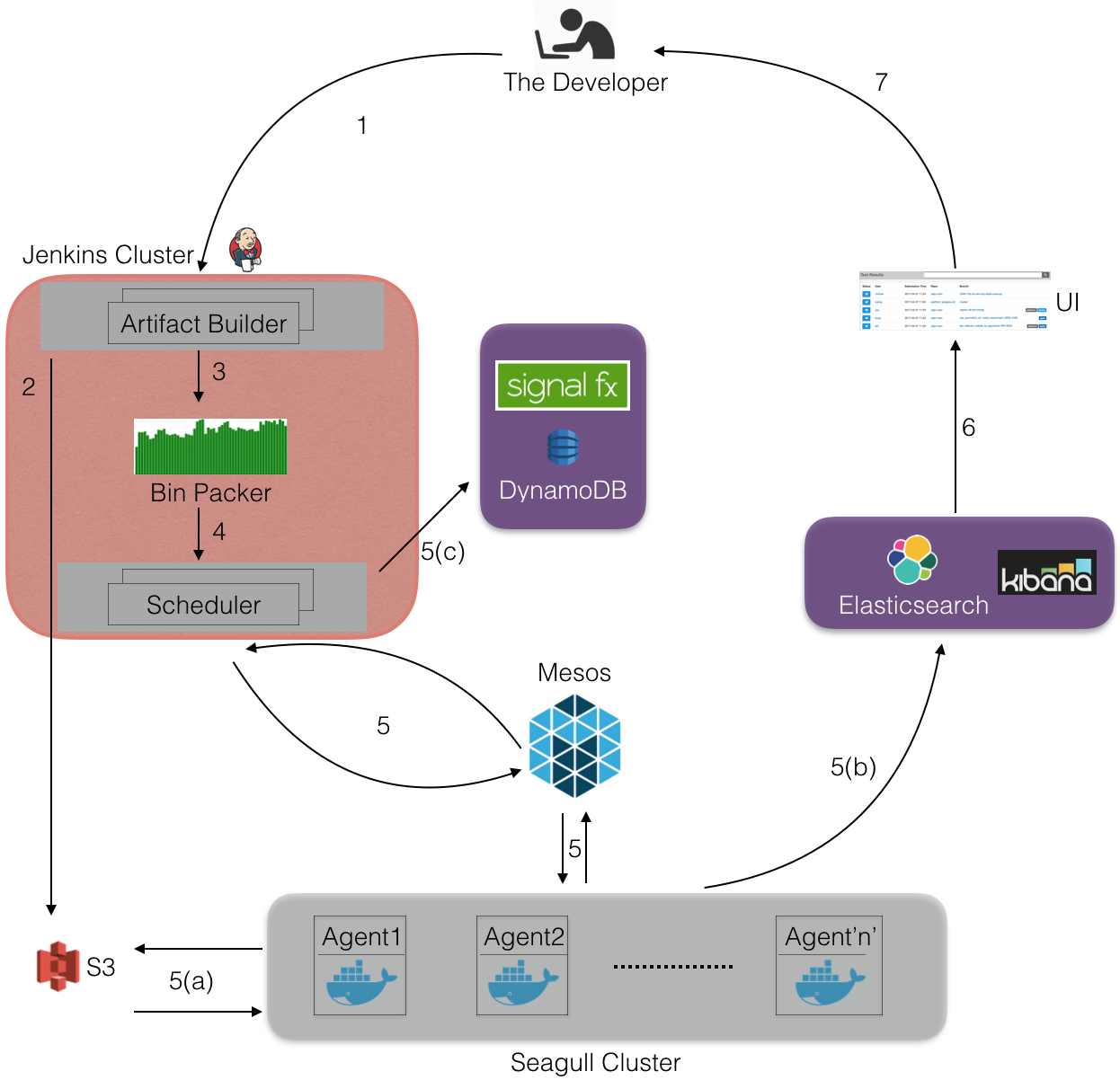
We’re continuously adding new features to our API to make it easier for developers to integrate with our data and share great local businesses through their apps. Today, we’re releasing access to query our data via GraphQL, a graph query language. This is available immediately through our developer beta program. What is GraphQL? GraphQL is a query language for APIs that places emphasis on being able to query for exactly the data you want. I’m sure most of you at some point have thought, “I really wish this endpoint had more data,” or, “I only need one or two pieces...