Keeping track of engineering-wide goals and migrations

-
Jason Tran, Software Engineer; James Flinn, Software Engineer
- Mar 13, 2024
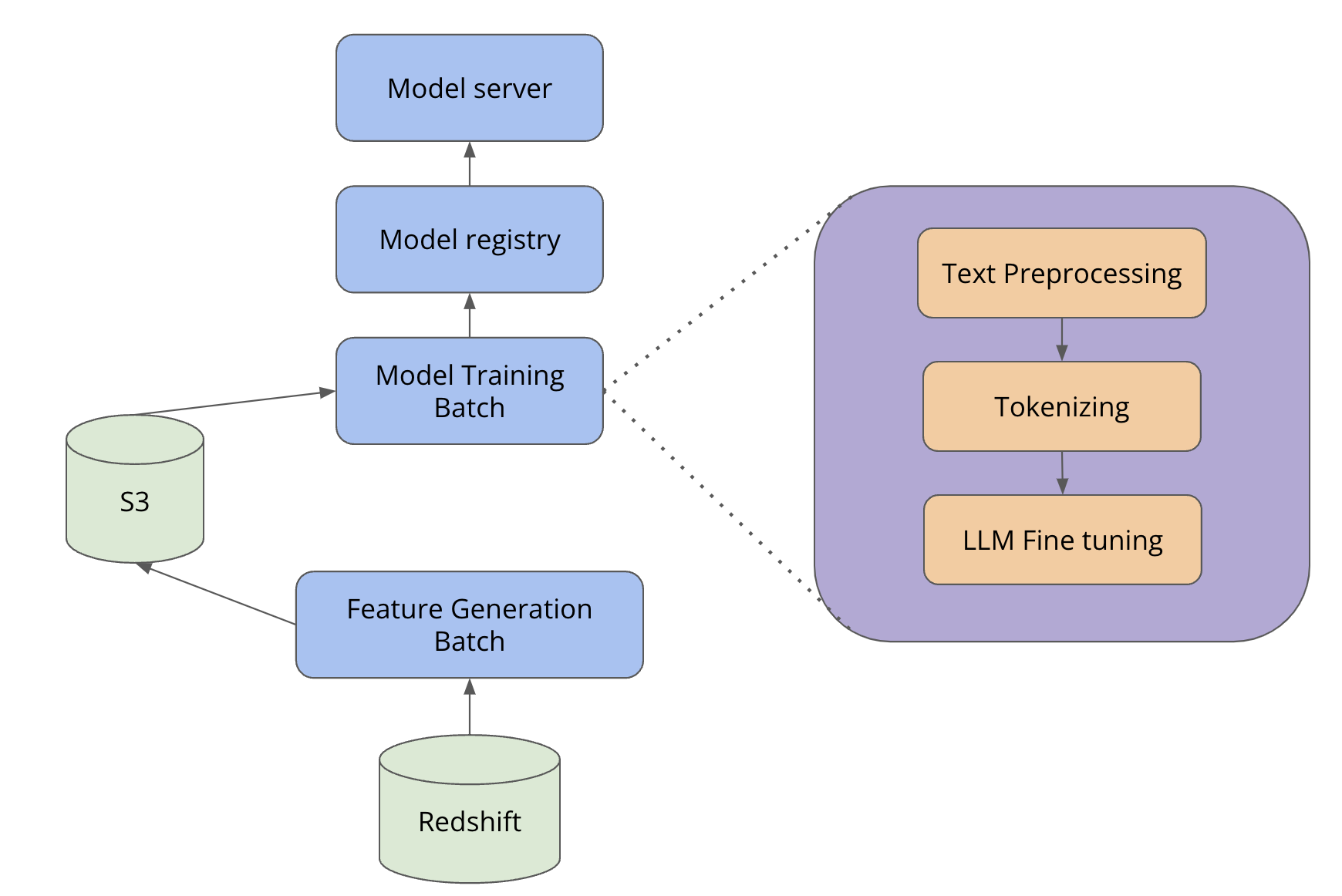
What is Engineering Effectiveness Metrics (EE Metrics)? EE Metrics was envisioned as a hub that helps teams manage their technical debt. EE Metrics provides every team with a detailed web page that contains information about technical debt that needs to be addressed. It also serves as a platform to highlight top engineering initiatives at the organization level. EE Metrics empowers infrastructure teams to surface important migrations or metrics that could improve the health of software projects. Organization-wide migrations of technologies can often be difficult to surface and keep track of. General EE Metrics lifecycle Figure 1: Diagram showing how EE...