How Yelp Built a Back-Testing Engine for Safer, Smarter Ad Budget Allocation

-
Samuele Mazzanti, Applied Scientist
- Feb 2, 2026
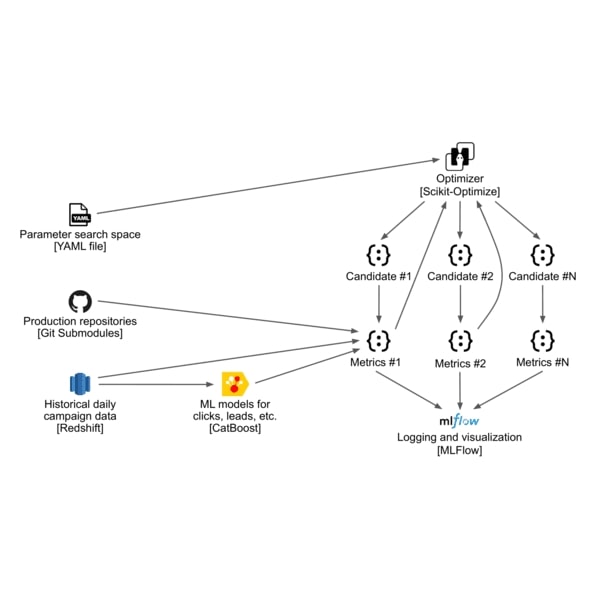
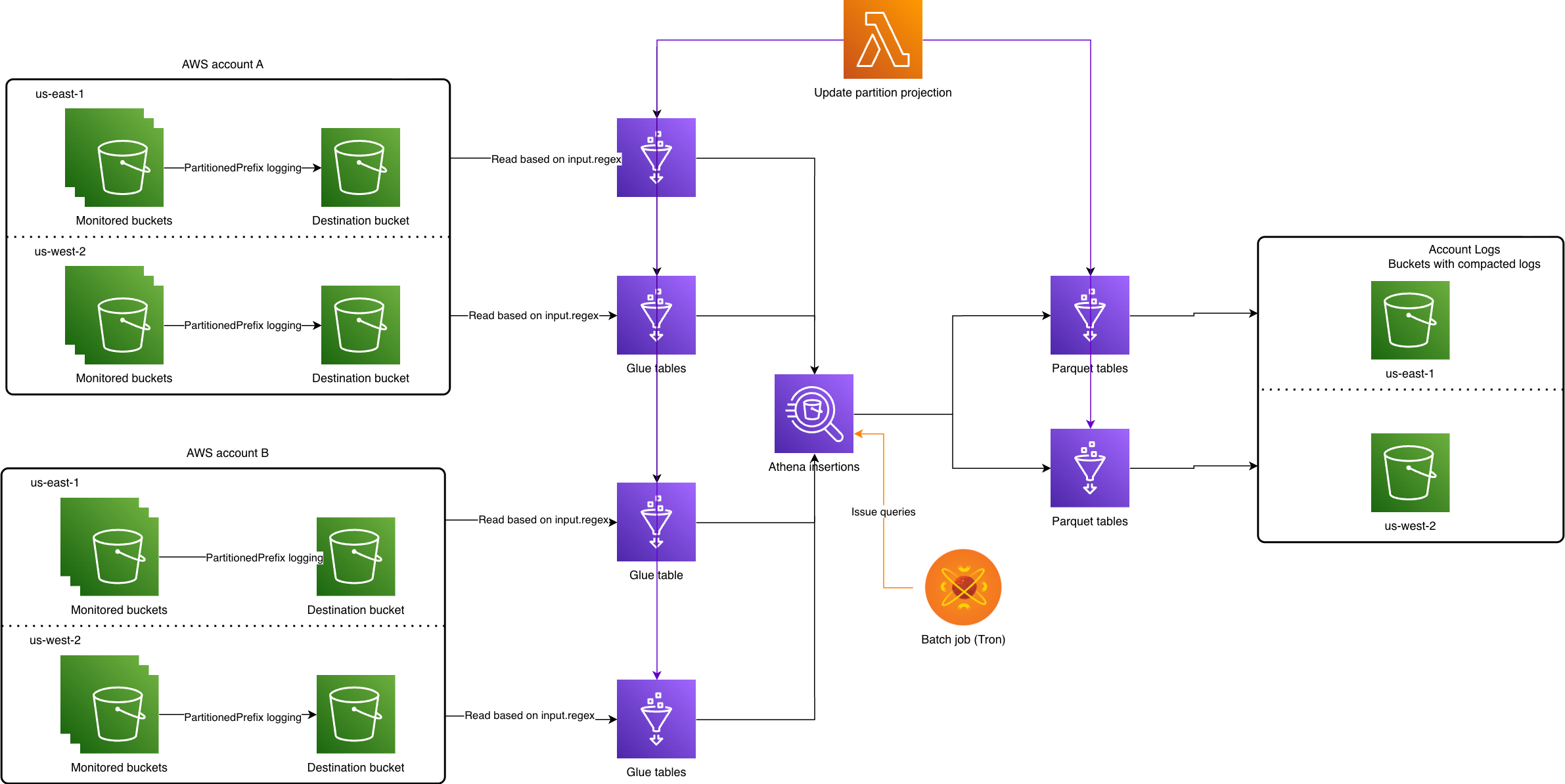
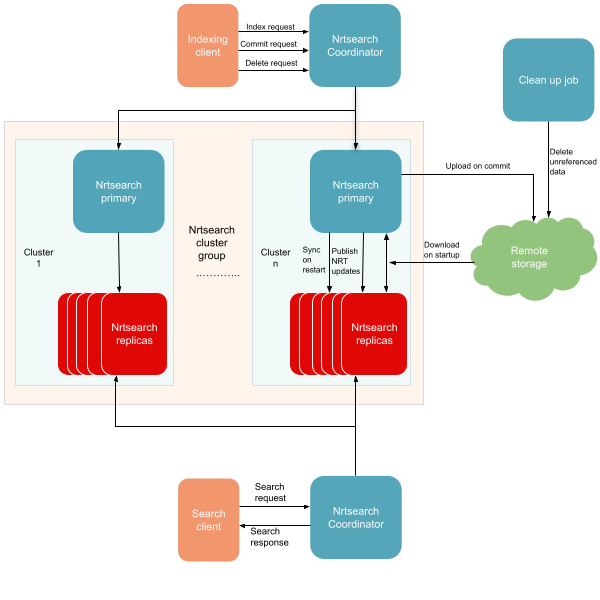
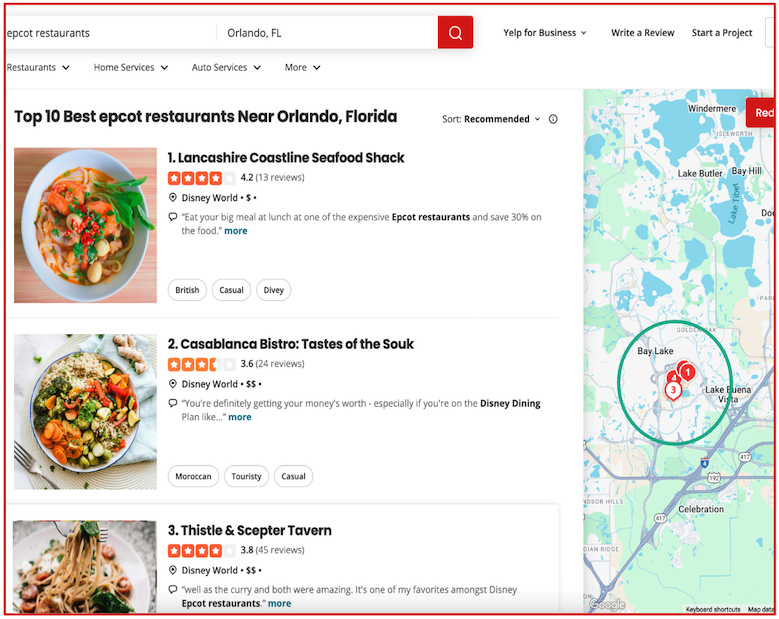
Introduction Modern advertising platforms are fast-paced and interconnected: even small adjustments can have ripple effects on how ads are shown, how budgets are spent, and the value advertisers get from their ad spend. At Yelp, Ad Budget Allocation means splitting each campaign’s spend between on‑platform inventory (our website, mobile site, and app) and off‑platform inventory (the Yelp Ad Network). We optimize this split to meet advertisers’ performance goals while growing overall revenue. Due to the complexity of the budget allocation system and its feedback loop, even small changes can lead to unexpected system‑wide effects. To help us safely evaluate changes,...