Passwordless Login: Reengaging Business Owners with Less Friction

-
Krista Poon, Software Engineer
- Mar 1, 2021
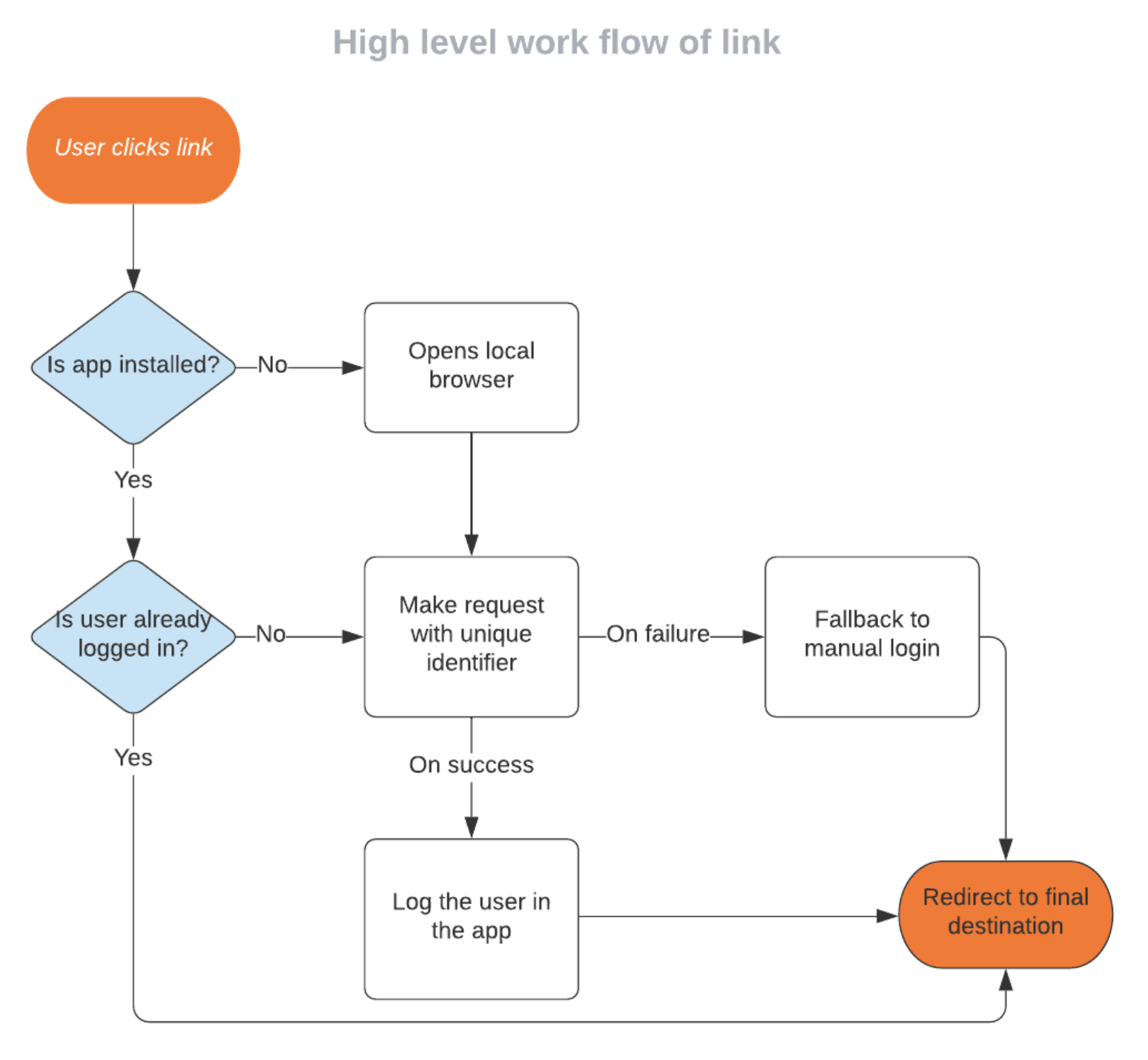
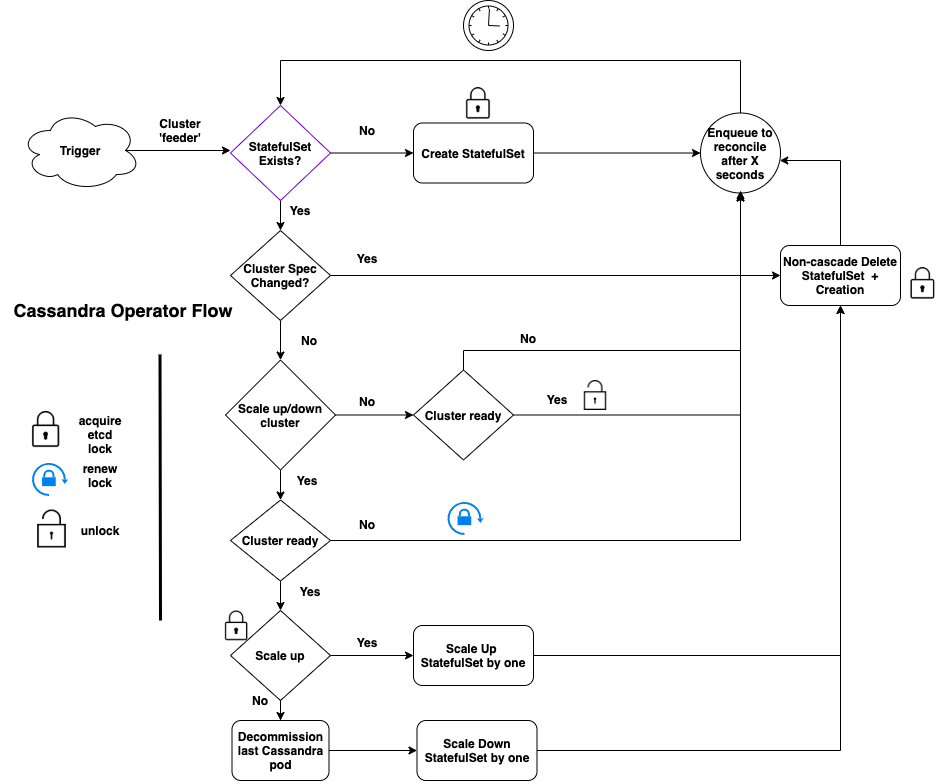
As various teams at Yelp were focused on developing features to help businesses adapt to COVID-19, some teams were looking ahead and developing features that would help businesses in the later stages or after the pandemic. The Challenge Early on in the pandemic, we saw some businesses pause advertising on Yelp as government regulations required many businesses temporarily close or limit their operations. However, businesses quickly adjusted to the local regulations, while implementing health and safety precautions to keep their staff and customers safe. Through this adjustment we wanted to ensure it was easy to restart advertising right where they...