Data Pipeline: Salesforce Connector

-
Ian F., Engineering Manager
- Sep 27, 2016
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
Yelp uses Salesforce, a customer relationship management (CRM) platform, for our 2000+ person sales team. Salesforce provides a range of out of the box features that make it easy to allow our sales leadership team to customize their business processes.
What does our sales team do? They sell advertising packages! Who do they sell them to? Businesses on Yelp! So how do we get that business information from Yelp’s databases to Salesforce’s? You’re about to find out.
Previous approach
Our existing one-way sync infrastructure, dubbed “Bulk Workers” was designed back in 2010 in order to dramatically improve the time it took to send data end-to-end. That design was able to improve sync times from 3 weeks down to 24 hours. Impressive! So what was this approach?
These “Bulk Workers” were cron’d Gearman workers that would crawl through each row in our Business table and transform the data to conform with our Salesforce schemas. These workers would then pass data off to Salesforce using a Salesforce client based on Beatbox that was modified to add support for the Salesforce Bulk API.
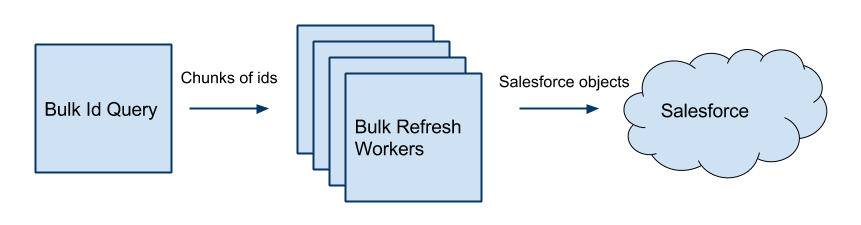
Legacy integration diagram
And all was well… until it wasn’t.
Over the next five years, this infrastructure saw the number of rows synced grow from around 30MM to >100MM across 12 other tables in 2015. The impact on data freshness was significant. Eventually the sync times started to get worse and worse. We knew we had to change our systems to support faster updates.
Enter: Data Pipeline
So we began to gather requirements. We determined we needed a solution with:
- Real time processing
- An at least once guarantee
- Built-in monitoring and alerting
- Configuration driven transformations between schemas
- The ability to easily add new fields and transformations
Around the same time, we had already begun working on our new Data Pipeline leveraging Kafka, a distributed pub/sub messaging system. This pipeline would provide us the first three requirements “out of the box.” All we had left to build was a transform framework that would fulfil the last two requirements and a connector to Salesforce.com.
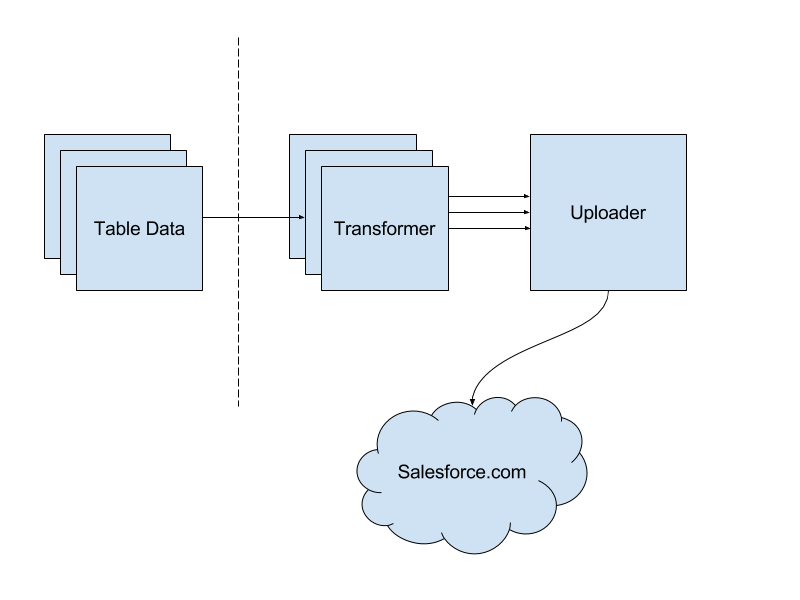
Salesforce Pipeline integration diagram
Transformers
We used a former Yelp Hackathon project that was productionised as the basis for our Kafka-to-Kafka processor, named PaaStorm due to its similarities to Storm and being deployed using Yelp PaaSTA. Keeping with the paradigm of Storm, we built a generic transformer and then spun up a multiple instances instances to consume from each topic that had source data we wanted to get into Salesforce. Using the source topic, each instance would look up the transformation steps from a YAML file and then perform copying, moving, and/or mapping values. This was important because the Salesforce schema predated our new infrastructure and could not be easily changed. This also meant there was no automatic way to map many of the fields. Having a config-driven mappings allowed us quick iterations on our transforms without the need for code deployments. This was critical to the project’s viability.
Each transformer would then publish a serialized Salesforce object into a new Kafka topic for our uploader to consume and then send that object to Salesforce.
Uploader
Having the uploader live as its own instance allows us to isolate how much of our service needs to be informed about communication to Salesforce.com. The uploader instance consumes transformed messages from each transformer and batches them up before sending requests to Salesforce. Since requests to Salesforce require reaching out into the Internet, this is one of the slowest parts of our pipeline. Batching efficiently is critical to performance. It is also important to use the ideal API. This can sometimes be hard when working with the various APIs that Salesforce provides. In order to make it easy for us to switch between APIs without extra work, we wrote a unified client that wraps existing Python clients for the SOAP, REST, and Bulk APIs. We also wrote an Object-relational Mapping (ORM) client and defined models for each of the tables we wish to write to. This allows us to validate data before it’s sent to Salesforce.com as well as identify which Salesforce External ID to use when writing.
Evaluation
The first table that we targeted was our Advertiser table. This was chosen since it’s smaller subset of our total businesses on Yelp and it is critical for our sales team to operate effectively. It had been taking 16 hours to sync changes from Yelp to Salesforce. When we launched our new infrastructure we saw that drop to an average of 10 seconds with spikes sometimes only as high as a few minutes! This meant that the data in Salesforce was reliable enough that our sales team doesn’t have to constantly request updated data whenever they view a record.
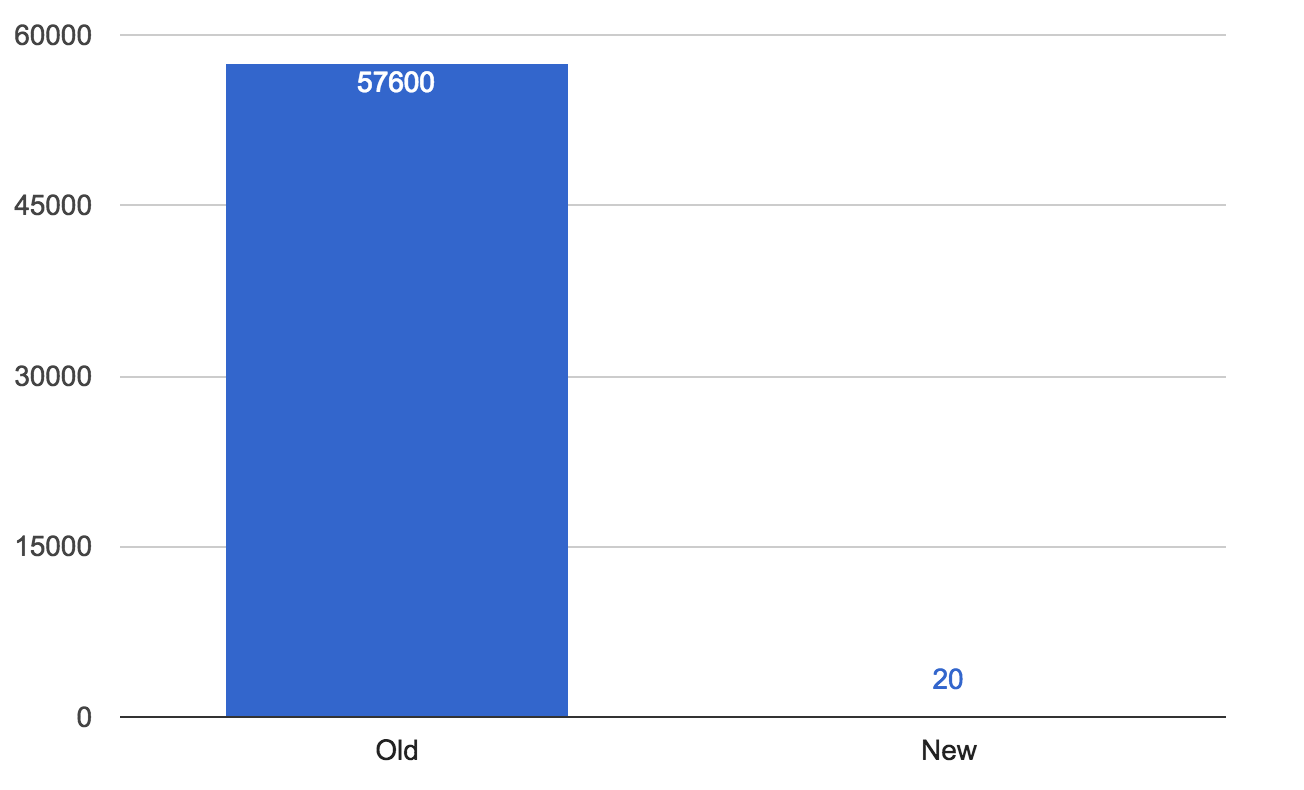
Average Sync Latency in Seconds
Challenges
Wasn’t that easy? Well, not quite. During the process of designing and building our connector we had to be sure to solve for several problems.
Since going live, we noticed that a good portion of our failed updates were due to requests that timed out in Salesforce or were rejected due to failing to get a lock for a required row. Both of these can be attributed to the heavy usage of triggers and rollups in our Salesforce instance. Nearly every table has very complicated logic that is executed with every write to ensure consistency across various records or to automate certain business processes. These features are great until you start hitting these kinds of problems. We are working now to reduce the amount of processing we do during write operations. Moving as much as we can to asynchronous processes will reduce the amount of time we need to lock a row and reduce the amount of processing done for every write.
Another problem that we have had to solve is dependency resolution. While our original data sources (MySQL) has constrained dependencies, Kafka does not. While messages written to individual Kafka topics are guaranteed to be in order, we cannot guarantee that the topics will be read at a specific or consistent rate. In the case of tables with dependencies on each other this is problematic because a one table may be read and updated before the other, causing data to go out of sync for periods of time. A common example is with our Advertiser records coming in shortly before a User. Since the Advertiser record contains a Lookup Field (aka. Foreign Key) to the User table, the write will fail. This requires us to keep track of records that fail due to missing dependencies and then retry them when their dependency is seen by the uploader. Serializing our uploads in dependency orders and handling retries covers most of our use cases, though it means we cannot achieve a high degree of parallelism.
Our other problem is that not all data exists in a single database row, yet the data that is readily available to us is of single data rows. To resolve this we are building new functionality to read two topics, join them, and republish the joined data.
Conclusion
We’ve seen huge improvements using our Kafka-backed data pipeline in getting data in front of our sales teams. Our next steps are building up our infrastructure so we can perform additional transformations, simple aggregations, and higher reliability when writing to Salesforce.
Read the posts in the series:
- Billions of Messages a Day - Yelp's Real-time Data Pipeline
- Streaming MySQL tables in real-time to Kafka
- More Than Just a Schema Store
- PaaStorm: A Streaming Processor
- Data Pipeline: Salesforce Connector
- Streaming Messages from Kafka into Redshift in near Real-Time
- Open-Sourcing Yelp's Data Pipeline
- Making 30x Performance Improvements on Yelp’s MySQLStreamer
- Black-Box Auditing: Verifying End-to-End Replication Integrity between MySQL and Redshift
- Fast Order Search Using Yelp’s Data Pipeline and Elasticsearch
- Joinery: A Tale of Un-Windowed Joins
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 1
- Streaming Cassandra into Kafka in (Near) Real-Time: Part 2
Build Real-time Data Infrastructure at Yelp
Want to build next-generation streaming data infrastructure? Apply to become an Infrastructure Engineer today.
View Job